用深度学习技术,让你的眼睛可以控制电脑
[转] http://www.gair.link/page/TextTranslation/756
用深度学习技术,让你的眼睛可以控制电脑
01
你有没有过这样的经历,当你在吃东西的时候,发现自己没有多余的手来调节电影的音量,或者调节屏幕的亮度?在本文,我们将看到如何使用最先进的人工智能技术来解决这个问题,通过眼球运动把相应命令下达到你的计算机。
注:在你阅读完本文之后,我邀请你继续阅读那些后续专为实现细节而写的帖子。
引言
我们想要实现什么
这个项目的目标是用我们的眼睛来触发计算机上的动作。这是一个非常综合的问题,所以我们首先需要明确我们想要实现的内容。
例如,我们可以检测眼睛什么时候朝向特定的角落,然后从那个角度进行工作。然而,这是非常有限的,并不是很灵活,加上它需要我们对角落组合。所以作为替代,我们使用递归神经网络来学习识别完整的眼球运动。
02
数据
我们不想使用外部数据集进行工作,作为替代的,我们自己制作数据集。我们在模型的训练和预测阶段用了相同的数据源以及处理方式,这对于我们这个项目而言具有非常大的益处。
毫无疑问,从我们的眼睛中提取信息的最有效的方法是使用专用的特写镜头。借助于这样的硬件,我们可以直接跟踪瞳孔中心,从而做出各种各样的令人惊叹的数据资料。
我不想使用外部相机,所以我决定使用我笔记本电脑破旧的720P摄像头。
工作流程
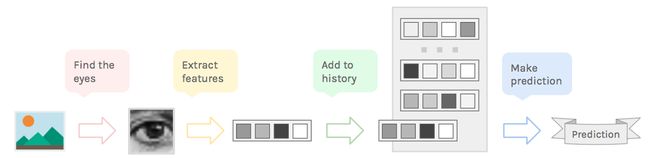
在我们直接进入技术讨论之前,让我们回顾一下这个过程的步骤。这里是我提出的流程:
-
用摄像头拍一张照片并找到眼睛。
-
对图像进行预处理并提取重要的特征(你是想说是利用神经网络来实现吗?)。
-
保持最后几帧特征提取的运行记录。
-
基于运行记录实现眼球动作的预测。
03
我们将使用管道法处理图像。
我们将通过本文下述步骤来实现,让我们开始吧!
获取眼睛图片
探测眼睛
直接通过摄像头,对图像降采样并将其转换为灰度图像(多颜色通道会产生大量冗余信息),这会使得接下来的操作更加快速,有助于模型实时运行。
对于探测,我们将使用 HAAR Cascades(Haar 基于特征的级联分类器),因为它们快捷,通过简单调整,我们可以得到良好结果,但在直接探测眼睛时会导致许多误报。为了消除这些影响,我们在图像中检测人脸而不是眼睛,然后可以在人脸上找到眼睛。
一旦获得含有眼睛的边界框,我们可以从最初的全尺寸摄像头抓拍中提取图像,这样就不会丢失任何信息了。
04
预处理数据
一旦找到了双眼,我们就需要为我们的数据集处理它们。 要做到这一点,我们可以简单地将双眼重塑为固定正方形,24px 大小,并使用直方图归一化来消除阴影。

提取眼睛的步骤
然后我们可以直接使用标准化图片作为输入,但我们有机会做更多有用的工作。 我们计算当前帧和前一帧中眼睛之间的差异来代替使用眼睛图像。 这是一种非常有效的动作编码方式,这是我们最终需要的。
**注意除了下面的 GIF 之外的所有图表,我将使用眼睛图片来表示眼睛差异,因为屏幕上的差异看起来很糟糕。**
标准化帧与帧差异之间的比较
现在我们已经处理了双眼,我们可以选择将它们分别视为同一类的两个代表,或者将它们一起使用,就像它们是单个图像一样。 我选择后者,因为即使眼睛应该遵循完全相同的运动,两个输入都会使模型更加健壮。
*尽管如此,我们要做的还是比将图像拼接在一起更聪明一点。
05
 把双眼合在一起
把双眼合在一起
06
创建数据集
记录
我已经分别为两个单独的动作记录了 50 个样本(一个看起来像“gamma”,另一个看起来像“Z”)。 我试图改变样本的位置、比例和速度,以帮助模型的推广。 我还添加了 50 个“idle”的例子,其中包含大致一般的无图案的眼睛动作和静止帧。

动作示例 - 'gamma'、'mount'、'Z'、'idle'
不幸的是,150 个样本对于这样的任务来说很小,所以我们需要用新样本来扩充数据集。
07
数据扩充
我们可以做的第一件事就是修复任意序列长度—100 帧。从那里,我们可以减慢较短的样本,加快较长的样本。因为速度不能定义运动,所以这是可能的。
与此同时,因为在100帧的窗中可以随时检测到低于100帧的序列,我们可以增加填充示例。

用于滑动窗口填充低于100帧的样本。
通过这些技术,我们可以扩充数据集大约到 1000—2000 个示例。
08
最终数据集
回顾一下,试着理解我们的数据。我们已经记录了一些带有相关标签的样本。每个样本都是由一系列的两个 24px 大小的方形图像组成。
注意每个眼睛都有一个数据集。

数据集的张量描述
09
模型
现在有了数据集,我们需要构建正确的模型来学习和推广这些数据。 我们可以写如下规格:
我们的模型应该能够在每个时间步骤从两个图像中提取信息,结合这些特征来预测用眼睛执行的运动。
如此复杂的系统要求使用一个强大的人工智能模型—神经网络。让我们看看怎样建造一个符合我们需求的网络。神经网层和搭积木类似,我们只需要选择合适的块并把它放到合适的地方。
视觉特征—卷积神经网络
为了从图像中提取信息,我们需要卷积层。这些善于处理图像获取视觉特征。(在第一部分已经介绍了)
我们需要分开单独处理每只眼睛,然后通过全连接层融合这些特征。由此产生的卷积神经网络(CNN)会试着从双眼中提取相关知识。
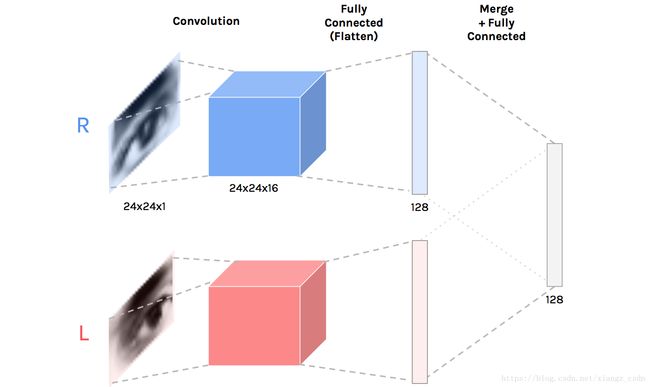
卷积神经网络—两个并行的卷积层提取视觉特征,然后两者融合。
10
时间特征—循环神经网络
现在我们对图像有一个简单描述,我们需要依次处理它们。因此使用递归层—长短期记忆网络。长短期记忆网络通过当前时间步骤提取到的特征和上一个状态来更新它的状态。
最后,当我们处理完这些图像序列,长短期记忆网络的状态传递到softmax 分类器来预测每个动作的可能性。
整体模型
最终神经网络需要用成对的图像序列作为输入,输出是每个动作的可能性。其中关键的是我们在一个单件中建造模型,因此它可以通过后向传播来进行端到端的训练。
我们可以称它为深度卷积的长短期记忆的双递归神经网络,但没人这样说。
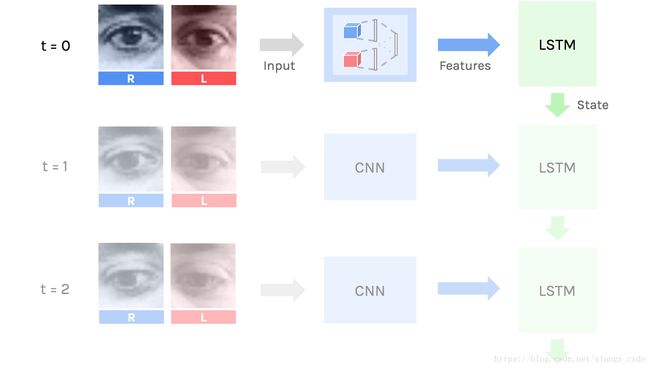
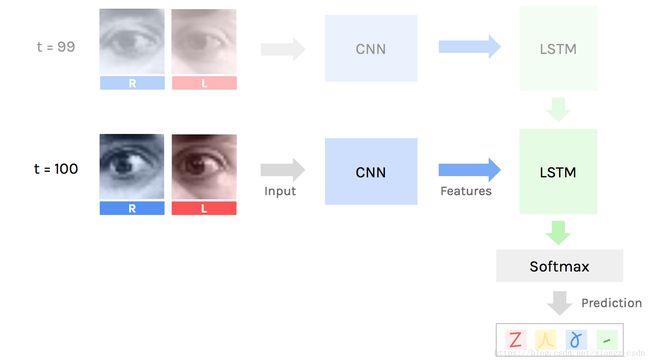
卷积神经网络从输入提取特征,由长短期记忆单元在每个步骤处理。
结果
这个训练的模型在测试集达到 85% 以上的准确率。考虑到未扩展之前的训练集非常小,这个结果是很好的。有更多的时间和贡献,我可以记录每一类至少 100—200 的示例,也许 3—4 个动作而不是 2 个(+空闲),这提高了效果。
唯一剩下的一步是实时使用分类器,调整它避免误报,并实现触发操作的逻辑(改变音量、打开应用程序、运行宏等)。更多的内容我会写在后续文章。
结论
在这里,我们已经看到如何使用 HAAR Cascades 来探测图像中的眼睛,如何清理图像以及如何使用图像差异来帮助进行运动相关的物体。
我们也看到了怎样人工扩展数据集和使用深度神经网络来拟合数据通过卷积层,全连接层和递归层。
我希望你喜欢这个研究,很高兴听到你的反馈。
11
如果您喜欢人工智能,请订阅时事通讯以接收文章更新等!
附文 - 代码和实现细节
如果您有兴趣,我会在这里详细介绍该项目的实施选择和各类问题(模型的选择,眼球追踪等)。
你可以在下列地址查阅项目代码:
despoisj/ DeepEyeControl