基于深度学习的车牌识别技术的研究
**当前行业现状:**https://www.jianshu.com/p/82174681e89f
1.A Theoretically Grounded Application of Dropout in Recurrent Neural Networks
Abstract–Recurrent neural networks (RNNs) stand at the forefront of many recent developments in deep learning. Yet a major difficulty with these models is their tendency to overfit, with dropout shown to fail when applied to recurrent layers. Recent results at the intersection of Bayesian modelling and deep learning offer a Bayesian interpretation of common deep learning techniques such as dropout. This grounding of dropout in approximate Bayesian inference suggests an extension of the theoretical results, offering insights into the use of dropout with RNN models. We apply this new variational inference based dropout technique in LSTM and GRU models, assessing it on language modelling and sentiment analysis tasks. The new approach outperforms existing techniques, and to the best of our knowledge improves on the single model state-of-the-art in language modelling with the Penn Treebank (73.4 test perplexity). This extends our arsenal of variational tools in deep learning.
2.Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Abstract–In this paper we compare different types of recurrent units in recurrent neural net-works (RNNs). Especially, we focus on more sophisticated units that implement a gating mechanism, such as a long short-term memory (LSTM) unit and a re-cently proposed gated recurrent unit (GRU). We evaluate these recurrent units on the tasks of polyphonic music modeling and speech signal modeling. Our experiments revealed that these advanced recurrent units are indeed better than more traditional recurrent units such as tanh units. Also, we found GRU to be comparable to LSTM.
3.Learning to Forget: Continual Prediction with LSTM
Abstract–Long Short-Term Memory (LSTM,[5]) can solve many tasks not solvable by previous learning algorithms for recurrent neural networks (RNNs). We identify a weakness of LSTM networks pro- cessing continual input streams without explic- itly marked sequence ends. Without resets, the internal state values may grow indefinitely and
eventually cause the network to break down. Our remedy is an adaptive “forget gate” that enables an LSTM cell to learn to reset itself at appropriate times, thus releasing internal re- sources. We review an illustrative benchmark
problem on which standard LSTM outperforms other RNN algorithms. All algorithms (including LSTM) fail to solve a continual version of that problem. LSTM with forget gates, how- ever, easily solves it in an elegant way.
4.On the Properties of Neural Machine Translation: Encoder–Decoder Approaches
Abstract–Neural machine translation is a relatively new approach to statistical machine trans-lation based purely on neural networks. The neural machine translation models of-ten consist of an encoder and a decoder. The encoder extracts a fixed-length repre-sentation from a variable-length input sen-tence, and the decoder generates a correct translation from this representation. Inthis paper, we focus on analyzing the proper-ties of the neural machine translation us-ing two models; RNN Encoder–Decoder and a newly proposed gated recursive con-volutional neural network. We show that the neural machine translation performs relatively well on short sentences without unknown words, but its performance de-grades rapidly as the length of the sentence and the number of unknown words increase. Furthermore, we find that the pro-posed gated recursive convolutional net-work learns a grammatical structure of a sentence automatically.
5.端到端的OCR:LSTM+CTC的实现 https://www.jianshu.com/p/4fadf629895b
代码:examples/warpctc/lstm_ocr.py
CTC是序列标志的一个重要算法,它主要解决了label对齐的问题。有很多实现。百度IDL在16年初公开了一个GPU的实现,号称速度比之前的theano-ctc, stanford-ctc都要快。Mxnet目前还没有ctc的实现,因此决定吧warpctc集成进mxnet。
**6.深度学习(Deep Learning)读书思考六:循环神经网络一(RNN)**https://blog.csdn.net/fangqingan_java/article/details/53014085
梯度弥散和爆炸问题
RNN训练比较困难,主要原因在于隐藏层参数W,无论在前向传播过程还是在反向传播过程中都会乘上多次。这样就会导致1)前向传播某个小于1的值乘上多次,对输出影响变小。2)反向传播时会导致梯度弥散问题,参数优化变得比较困难。
梯度弥散问题解决方案
针对该问题,有大量的解决方法,效果不一致。
1.有效初始化+ReLU激活函数能够得到较好效果
2.算法上的优化,例如截断的BPTT算法。
3.模型上的改进,例如LSTM、GRU单元都可以有效解决长期依赖问题。
4.在BPTT算法中加入skip connection,此时误差可以间歇的向前传播。
5.加入一些Leaky Units,思路类似于skip connection
7.循环神经网络(RNN)的发展
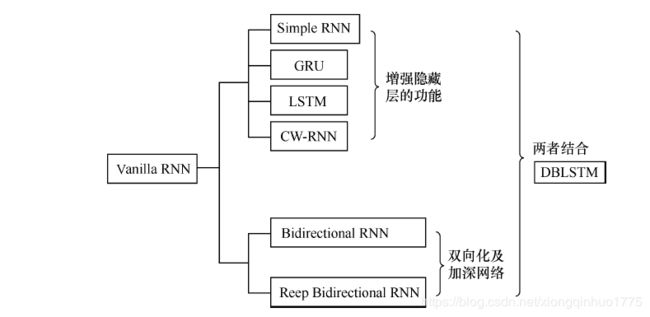
8.三次简化一张图:一招理解LSTM/GRU门控机制
https://zhuanlan.zhihu.com/p/28297161
9.A Critical Review of Recurrent Neural Networks for Sequence Learning
Countless learning tasks require dealing with sequential data. Image captioning, speech synthesis, and music generation all require that a model produce outputs that are sequences. In other domains, such as time series prediction, video analysis, and musical information retrieval, a model must learn from inputs that are sequences. Interactive tasks, such as translating natural language, engaging in dialogue, and controlling a robot, often demand both capabilities. Recurrent neural networks (RNNs) are connectionist models that capture the dynamics of sequences via cycles in the network of nodes. Unlike standard feedforward neural networks, recurrent networks retain a state that can represent information from an arbitrarily long context window. Although recurrent neural networks have traditionally been dicult to train, and often contain millions of parameters, recent advances in network architectures, optimization techniques, and parallel computation have enabled successful large-scale learning with them.
In recent years, systems based on long short-term memory (LSTM) and bidirectional (BRNN) architectures have demonstrated ground-breaking performance on tasks as varied as image captioning, language translation, and handwriting recognition. In this survey, we review and synthesize the research that over the past three decades rst yielded and then made practical these powerful learning models. When appropriate, we reconcile con icting notation and nomenclature. Our goal is to provide a self-contained explication of the state of the art together with a historical perspective and references to primaryresearch.
10.A Theoretically Grounded Application of Dropout in Recurrent Neural Networks
Recurrent neural networks (RNNs) stand at the forefront of many recent developments in deep learning. Yet a major difficulty with these models is their tendency to overfit, with dropout shown to fail when applied to recurrent layers. Recent results at the intersection of Bayesian modelling and deep learning offer a Bayesian interpretation of common deep learning techniques such as dropout. This grounding of dropout in approximate Bayesian inference suggests an extension of the theoretical results, offering insights into the use of dropout with RNN models. We apply this new variational inference based dropout technique in LSTM and GRU models, assessing it on language modelling and sentiment analysis tasks. The new approach outperforms existing techniques, and to the best of our knowledge improves on the single model state-of-the-art in language modelling with the Penn Treebank (73.4 test perplexity). This extends our arsenal of variational tools in deep learning.
11.Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
In this paper we compare different types of recurrent units in recurrent neural networks (RNNs). Especially, we focus on more sophisticated units that implement a gating mechanism, such as a long short-term memory (LSTM) unit and a re-
cently proposed gated recurrent unit (GRU). We evaluate these recurrent units on the tasks of polyphonic music modeling and speech signal modeling. Our experiments revealed that these advanced recurrent units are indeed better than more traditional recurrent units such as tanh units. Also, we found GRU to be comparable to LSTM
12.Understanding GRU networks
https://towardsdatascience.com/understanding-gru-networks-2ef37df6c9be
13.CVPR2017-如何在无标签数据集上训练模型
https://blog.csdn.net/u014380165/article/details/76946425
传统的fine-tuning都是在一个固定的数据集上继续训练一个预训练的模型,但是本文的fine-tuning从一个空的带标签数据集开始,然后不断将部分未标注数据进行标注并填充到带标签数据集中并继续训练模型。这种算法主要就是解决带标注的医疗图像数据量少的问题,因为这个模型可以通过给未标注图像进行标注然后加入到数据集中继续训练模型。
14.LPRNet: License Plate Recognition via Deep Neural Networks
Abstract–This paper proposes LPRNet - end-to-end method for Automatic License Plate Recognition without preliminary character segmentation. Our approach is inspired by re-cent breakthroughs in Deep Neural Networks, and works in real-time with recognition accuracy up to 95% for Chinese license plates: 3 ms/plate on nVIDIA R GeForce TM GTX 1080 and 1.3 ms/plate on Intel R Core TM i7-6700K CPU. LPRNet consists of the lightweight Convolutional Neural Network, so it can be trained in end-to-end way. To the best of our knowledge, LPRNet is the first real-time License
Plate Recognition system that does not use RNNs. As a re-sult, the LPRNet algorithm may be used to create embedded solutions for LPR that feature high level accuracy even on challenging Chinese license plates.
15.LocNet: Improving Localization Accuracy for Object Detection + A Theoretical analysis of feature pooling in Visual Recognition https://www.cnblogs.com/jie-dcai/p/5785563.html
- Sequence Modeling With CTC https://distill.pub/2017/ctc/
Connectionist Temporal Classification (CTC)
Encoder: The encoder of a CTC model can be just about any encoder we find in commonly used encoder-decoder models. For example the encoder could be a multi-layer bidirectional RNN or a convolutional network. There is a constraint on the CTC encoder that doesn’t apply to the others. The input length cannot be sub-sampled so much that T/s is less than the length of the output.
Decoder: We can view the decoder of a CTC model as a simple linear transformation followed by a softmax normalization. This layer should project all T steps of the encoder output H into the dimensionality of the output alphabet.
Beam Search https://www.zhihu.com/question/54356960
17.Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally
Abstract–Intense interest in applying convolutional neural net-works (CNNs) in biomedical image analysis is wide spread, but its success is impeded by the lack of large annotated datasets in biomedical imaging. Annotating biomedical im-ages is not only tedious and time consuming, but also de-manding of costly, specialty-oriented knowledge and skill-s, which are not easily accessible. To dramatically reduce annotation cost, this paper presents a novel method called AIFT (active, incremental fine-tuning) to naturally integrate active learning and transfer learning into a single framework. AIFT starts directly with a pre-trained CNN to seek “worthy” samples from the unannotated for annotation, and the (fine-tuned) CNN is further fine-tuned continuously by incorporating newly annotated samples in each iteration
to enhance the CNN’s performance incrementally. We have evaluated our method in three different biomedical imaging applications, demonstrating that the cost of annotation can be cut by at least half. This performance is attributed to the
several advantages derived from the advanced active and incremental capability of our AIFT method.
18.Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
Abstract–Many real-world sequence learning tasks require the prediction of sequences of labels from noisy, unsegmented input data. In speech recognition, for example, an acoustic signal is transcribed into words or sub-word units. Recurrent neural networks (RNNs)are powerful sequence learners that would seem well suited to such tasks. However, because they require pre-segmented training data, and post-processing to transform their outputs into label sequences, their applicability has so far been limited. This paper presents a novel method for training RNNs to label unsegmented sequences directly, thereby solving both problems. An experiment on the TIMIT speech corpus demonstrates its ad-vantages over both a baseline HMM and a hybrid HMM-RNN.
∗
19.Deep Automatic Licence Plate Recognition system
Abstract-Automatic License Plate Recognition (ALPR) has important applications in trac surveillance . It is a challenging problem especially in countries like in India where the license plates have varying sizes, number of lines, fonts etc. The diculty is all the more accentuated in trac videos as the cameras are placed high and most plates appear skewed. This work aims to address ALPR using Deep CNN methods for real-time trac videos. We rst extract license plate candidates from each frame using edge information and ge-ometrical properties, ensuring high recall. These proposals are fed to a CNN classi er for License Plate detection obtaining high precision. We then use a CNN classi er trained for individual characters along with a spatial transformer network (STN) for character recognition. Our system is evaluated on several trac videos with vehicles having di erent license plate formats in terms of tilt, distances, colors, illumination, character size, thickness etc. Results demonstrate robustness to such variations and impressive performance in both the localization and recognition. We also make avail-able the dataset for further research on this topic.
20.Adversarial Generation of Training Examples: Applications to Moving V ehicle License Plate Recognition
Generative Adversarial Networks (GAN) have attracted much research attention recently, leading to impressive results for natural image generation. However, to date little success was observed in using GAN generated images for improving classification tasks. Here we attempt to explore, in the context of license plate recognition for moving cars using a moving camera, whether it is possible to generate synthetic training data using GAN to improve recognition accuracy. With a carefully-designed pipeline, we show that the answer is affirmative. First, a large-scale image set is generated using the generator of GAN, without manual annotation. Then, these images are fed to a deep convolutional neural network (DCNN) followed by a bidirectional recurrent neural network (BRNN) with long short-term memory (LSTM), which performs the feature learning and sequence labelling. Finally, the pre-trained model is fine-tuned on real images. Our experimental results on a few data sets demonstrate the effectiveness of using GAN images: an improvement of 7.5 recognition accuracy percent points (pp) over a strong baseline with moderate-sized real data being available. We show that the proposed framework achieves competitive recognition accuracy on challenging testdatasets. We also leverage the depthwise separate convolution to construct a lightweight convolutional recurrent neural network (LightCRNN), which is about half size and 2 faster on CPU. Combining this framework and the proposed pipeline, we make progress in performing accurate recognition on mobile and embedded devices.
Index Terms—Generative adversarial network (GAN), Convo-lutional neural network (CNN), Bidirectional recurrent neural network (BRNN), Long short-term memory (LSTM), Depthwise separate convolution.
人造车牌,Gan训练车牌更为逼真
21.Towards End-to-End Car License Plates Detection and Recognition with Deep Neural Networks .
In this work, we tackle the problem of car license plate detection and recognition in natural scene images. We propose a unified deep neural network which can localize license plates and recognize the letters simultaneously in a single forward pass. The whole network can be trained end-to-end. In contrast to existing approaches which take license plate detection and recognition as two separate tasks and settle them step by step, our method jointly solves these two tasks by a single network. It not only avoids intermediate error accumulation, but also accelerates the processing speed. For performance evaluation, three datasets including images captured from various scenes under different conditions are tested. Extensive experiments show the effectiveness and efficiency of our proposed approach.
Index Terms—Car plate detection and recognition, Convolutional neural networks, Recurrent neural networks
22.多级细粒度特征融合的端到端车牌识别研究
摘要: 为解决预处理、车牌定位、字符分割和字符识别这一传统车牌识别方法复杂且流程衔接误差较大的问题,提出定位-识别的通道化车牌处理模型方法。首先根据车牌形态的结构化特点,改进Yolov2 提取不同网络深度的多级细粒度特征,重构后进行融合,并利用k-means + + 算法对实验数据集真实目标框进行维度聚类,以初始化候选框进行车牌定位,提高定位精度; 其次重塑Alexnet 网络,采用七个全连接层共享卷积神经网络的模型结构约减算法流程,实现端到端的车牌识别。实验结果表明,该方法具有较高的识别率和鲁棒性,能适应复杂自然环境下的识别应用。
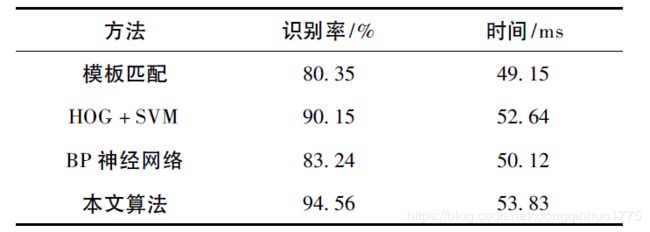
以上是笔者在学习阶段看的部分论文,和一些文章,仅供参考。