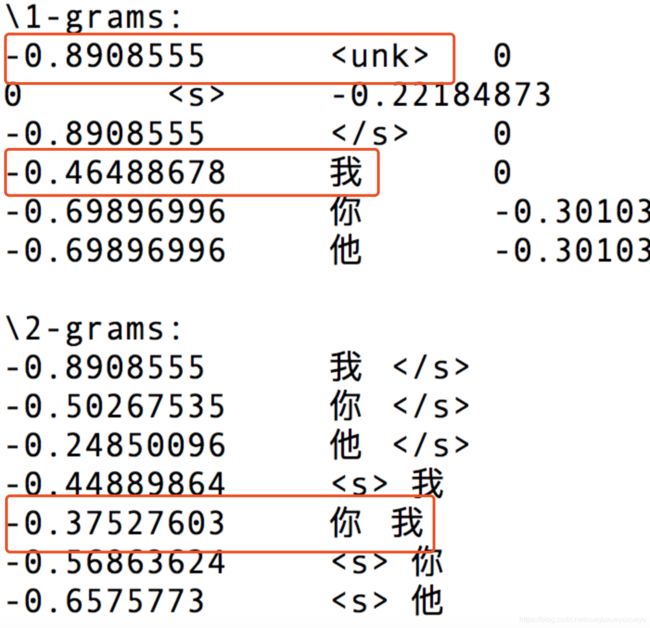
以kenlm为例,详细介绍N-gram语言模型
本文为转载https://blog.csdn.net/asrgreek/article/details/81979194的基础上,做了一些推演与推演过程的修正,如有错误欢迎指正。
本文以KenlM介绍常用的N-gram语言模型原理。KenlM采用的平滑技术是Modified Kneser-ney smoothing
以以下代码段为例介绍,以N=2为例,即2-gram,bigram介绍N-gram模型:
我
你 我
他
我
你接下来我们一步步剖析该模型的实现过程
一、增加和标记符,表示句子的开头和结尾
我
你 我
他
我
你
二、把每个词映射到唯一的数字id,为了更直观地描述下面的关键步骤,我们这里就不把单词映射为数字id
三、Counting(原始计数)。也就是把相同的字合并,然后排序(假设编码顺序为、我、你、他、<\s>) 。根据步骤一的文本,我们可以得到1-gram和2-gram的原始计数counting一列:
表1 1-gram counting
| 1-gram | 原始计数counting | 中间计算过程 | Adjust count |
| 5 | 由公式第一行, |
5 | |
| 我 | 3 | “我”前面出现了“你”和“ |
2 |
| 你 | 2 | “你”前面出现了“ |
1 |
| 他 | 1 | “他”前面出现了“ |
1 |
| 5 | “”前面出现了“我”,“你”,“他”a(<\s>)=3 | 3 |
| 2-gram | 原始计数 | 中间计算过程 | Adjust count |
|---|---|---|---|
| 2 | 根据式1的条件表达式(n=N),故与原始计数相同 | 2 | |
| 2 | 同上 | 2 | |
| 1 | 同上 | 1 | |
| 我 | 3 | 同上 | 3 |
| 你 我 | 1 | 同上 | 1 |
| 你 | 1 | 同上 | 1 |
| 他 | 1 | 同上 | 1 |
四、Adjusting(调整计数)。其基本思想是对于那些lower-gram,我们不care其出现的次数,而是关心其作为novel continuation的可能性。比如“York”,其在语料中出现的次数一般会比较多,因为“New York”是很高频的词。但“York”作为continuation(中文意思:别的词把“york”作为接续词)的可能性就较低,也就是说它前面的词只有“new”等少数几类词,所以应该给它较低的计数。其公式如右: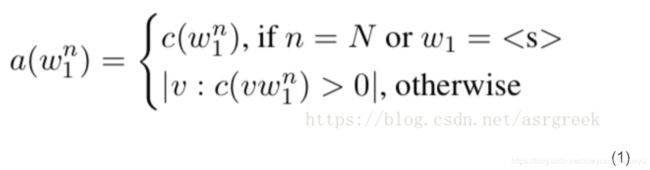
其中:
 表示某个n-gram,比如n=2时,那么
表示某个n-gram,比如n=2时,那么 表示表2中第一列的某个2-gram
表示表2中第一列的某个2-gram- c()表示的原始计数;1-gram的原始计数见表1,2-gram的原始计数见表
- a()表示由原始计数调整后的计数;2-gram的调整后计数不变(根据式子(1)中的第一行),还是如表2所示;1-gram的调整后计数见表1(根据式子(1)中的第二行得到的)第三和第四列
特别需要说明的是公式(1)中的|v:c(v![]() )∣,表示
)∣,表示![]() 前面出现的词的种类,比如=“我”,词库中“
前面出现的词的种类,比如=“我”,词库中“我”出现2次,“你我”出现1次,那么“我”的前面出现的词的种类就为2,a(我)=2,而不是3,因为我们care的不是出现次数。根据这一原则,我们可以得到1-gram的调整计数,如表1的第三/四列所示
而对于2-gram的adjusting count,根据式1的条件表达式(n=N)得,2-gram的adjusting count与表2相同,如表2的第三/四列所示
五、Discounting。其基本思想是把经常出现的一些N-Gram的概率分一些出来给没有出 现的N-gram,也就等同于将经常出现的N-Gram次数减去(discount)一部分,这样做的道理就在于,对于出现次数比较多的计数我们其实已经得到了一个相对比较好的估计,那么当我们从这个计数值中减去一个较小的数值d后应该影响不大。那 到底该discount取多少呢?其中比较有代表性的有Church & Gale于1991年通过留存 法实验从而得到的Absolute Discounting;另一个是Chen and Goodman于1998年提出 的方法,其公式如下: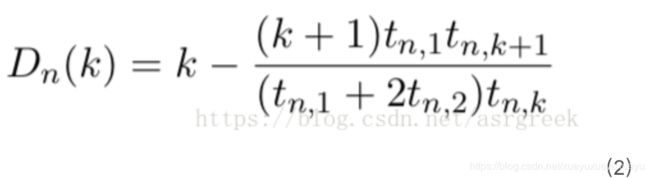
- k范围为[1,3],k=0时,
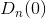 =0, k>3时,
=0, k>3时,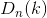 =
=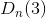
- n范围为[1,N],本文中N=2,所以n的范围为[1,2]
n ε [1,N];比如在本例中我们采用2-gram,那么N=2,n=[1,2];
在计算Dn(k)之前,我们需要先计算tn,k。tn,k表示出现了k次的n-gram的个数(比如根据表3,出现1次的1-gram的次数为2,分别为“你”、“他”)。其数学表达式如下: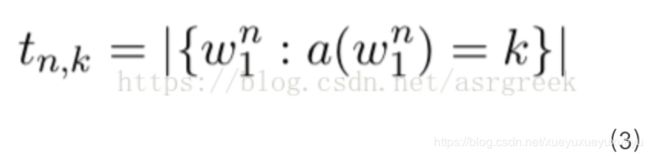
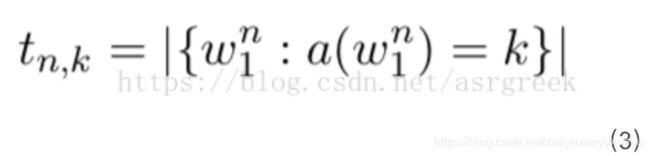
(3)根据公式(3)、表3和表4,我们可以得到![]() 的取值
的取值![]() 到
到![]() ,
,![]() 到
到![]()
| 中间计算过程 | 结果 | |
| a( |
2 | |
| a( |
1 | |
| a( |
1 | |
| a( |
0 | |
| a( |
4 | |
| a( |
2 | |
| a( |
1 | |
| a( |
0 |
根据公式(2)和表5,我们可以得到Dn(k)的取值:
| Discount | 中间计算过程 | 结果 |
| D1(1) | a( |
1/2 |
| D1(2) | a( |
1/2 |
| D1(3) | a( |
3 |
| D2(1) | a( |
1/2 |
| D2(2) | a( |
4/5 |
| D2(3) | a( |
3 |
六、Normalization。该步骤其实分为两小步:
① 计算n-gram的概率,该概率称之为pseudo probability,也就是说它不是最终的概率,但对于计算最终概率是有用的。pseudo probability的计算公式(4)如下: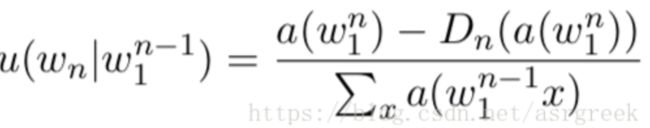
我们可以看到跟传统的n-gram公式相比,它的分子多减去一项,被减去的这一项也就是第五步计算得到的discount。
接下来我以u(我)和u(我∣你)为例来详细介绍下计算过程,其他概率的计算读者有兴趣的话可以自己做下。
对于u(我)的计算,n=1;
Unexpected text node: ' '
a(我)= (a(我)-Dn(a(我)))/(Σxa(x))=(2-1/2)/(2+1+1+3)
其中Σxa(x) = a(我) + a(你) + a(他) + a(<\s>) = 2+1+1+3 = 7。需要注意的是我们并没有加上a(),因为最为句子开头标志,其前面不可能再有其他词
对于u(我|你)的计算,n=2;
a(我∣你)= Σxa(你x)a(我∣你)−Dn(a(我∣你))=(1-1/2)/(1+1)
其中a(你x) = a(你 我) + a(你 ) = 1+1 = 2
② 计算回退权重,也称为back-off weight, 它衡量的是某个词后面能接不同词的能力。举个例子,考虑 spite 和 constant 的 bigram,在 Europarl corpus 中,两个 bigram 都出现了 993 次,以 spite 开始的 bigram 只有 9 种,大多数情况下 spite 后面跟着 of(979 次),因为 in spite of 是常见的表达,而跟在 constant 后的单词有 415 种,所以我们更有可能见到一个跟在 constant 后面的bigram,因此back-off(constant)>back-off(spite)。 基于上述思想,定义其表达式为:
(5)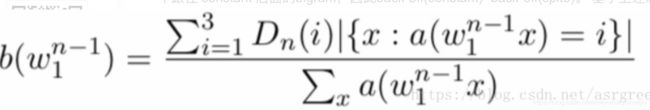
根据该公式,再结合表3和表6,我们可以计算每个字的回退权重,如下:
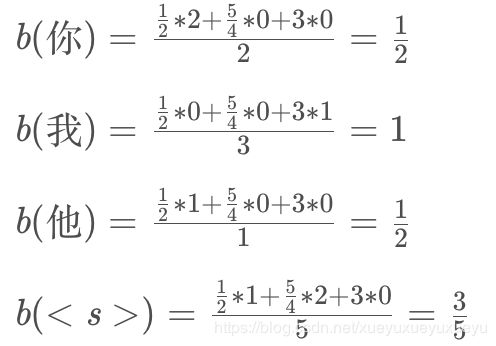
然后对上述的概率取以10为底的log,就能得到与图1中的第三列对应的结果。需要注意的是我们没有计算b(),这是因为已经是句子的最后一个单词,它在后退之后就没有其他词了。
ps:arpa中的概率是取log10,而不是ln
七、Interpolation。在讲解Interpolation之前,我们先看一个例子:如果c(多的)和c(多敛) 都为0,也就是说在某个语料中都没出现,那么在传统的n-gram中,p(的∣多)=p(敛∣ 多)。而这个概率我们直观上来看是错误的,p(的∣多)应该比p(敛∣多)高很多。要实 现这个,我们就希望把 bigram 和 unigram 结合起来,因为“的”比“敛”常见的多,就能保证p(的∣多)>p(敛∣多)。interpolate 就是这样一种方法,它的数学表达式如下所示:
(6)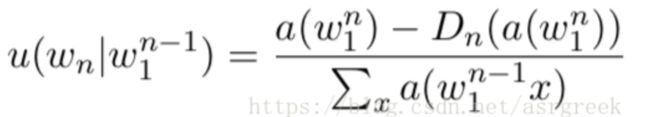
该过程不断递归,直到unigram停止。其中unigram的插值用uniform distribution表 示,如下列表达式所示:
(7)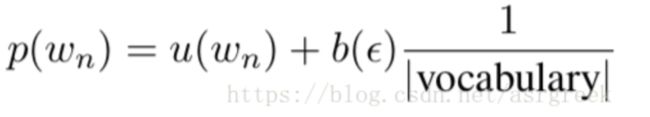
其中∣vocabulary∣表示词汇量大小,这里总共有{、我、你、他、<\s>}5个词,所以 ∣vocabulary∣=5;ε表示空字符串。b(ε)
b(ε)的计算需要特别说明下:
b(ε)=12∗2+12∗1+3∗12+1+1+3=914
需要注意的是,上式对于b(ε)b(ε)的计算,n应该取1。
接下来我们选取几个概率进行计算,来验证下计算结果是否与实际结果相同。
p(我)=u(我)+b(ε)∗1∣vocabulary∣=3/14+9/14∗1/5=24/70
p(我∣你)=u(我∣你)+b(你)∗p(我)= 1/4+1/2*(24/70)=59/140
如果你仔细看图1,你会发现其中有个
因为我们这个例子没有未登录词,所以
同样的,对上述的概率取以10为底的log,就能得到与图1中的第一列对应的结果。 因为篇幅有限(实际上也没这个必要),我就不把全部的概率计算过程列出来了。读者 有兴趣可以按照上面的方法把全部概率都计算一遍,再跟实际结果如下图对比