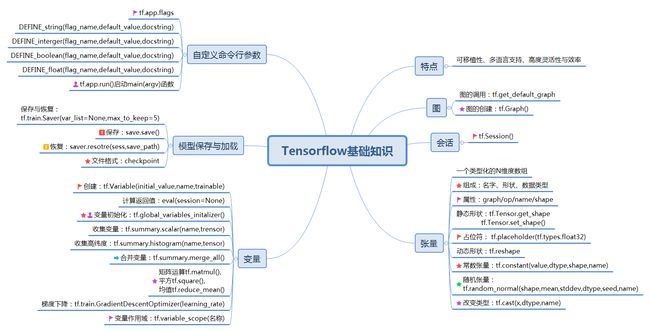
机器学习Tensorflow基础知识、张量与变量
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
一、Tensorflow的特征
- 高度的灵活性
TensorFlow 不是一个严格的“神经网络”库。只要你可以将你的计算表示为一个数据流图,你就可以使用Tensorflow。你来构建图,描写驱动计算的内部循环。我们提供了有用的工具来帮助你组装“子图”(常用于神经网络),当然用户也可以自己在Tensorflow基础上写自己的“上层库”。定义顺手好用的新复合操作和写一个python函数一样容易,而且也不用担心性能损耗。当然万一你发现找不到想要的底层数据操作,你也可以自己写一点c++代码来丰富底层的操作。
- 真正的可移植性(Portability)
Tensorflow 在CPU和GPU上运行,比如说可以运行在台式机、服务器、手机移动设备等等。想要在没有特殊硬件的前提下,在你的笔记本上跑一下机器学习的新想法?Tensorflow可以办到这点。准备将你的训练模型在多个CPU上规模化运算,又不想修改代码?Tensorflow可以办到这点。想要将你的训练好的模型作为产品的一部分用到手机app里?Tensorflow可以办到这点。你改变主意了,想要将你的模型作为云端服务运行在自己的服务器上,或者运行在Docker容器里?Tensorfow也能办到
- 多语言支持
Tensorflow 有一个合理的c++使用界面,也有一个易用的python使用界面来构建和执行你的graphs。你可以直接写python/c++程序,也可以用交互式的ipython界面来用Tensorflow尝试些想法,它可以帮你将笔记、代码、可视化等有条理地归置好。当然这仅仅是个起点——我们希望能鼓励你创造自己最喜欢的语言界面,比如Go,Java,Lua,Javascript,或者是R
- 性能最优化
比如说你又一个32个CPU内核、4个GPU显卡的工作站,想要将你工作站的计算潜能全发挥出来?由于Tensorflow 给予了线程、队列、异步操作等以最佳的支持,Tensorflow 让你可以将你手边硬件的计算潜能全部发挥出来。你可以自由地将Tensorflow图中的计算元素分配到不同设备上,Tensorflow可以帮你管理好这些不同副本。
二、下载以及安装
选择类型
必须选择以下类型的TensorFlow之一来安装:
- TensorFlow仅支持CPU支持。如果您的系统没有NVIDIA®GPU,则必须安装此版本。请注意,此版本的TensorFlow通常会更容易安装(通常在5或10分钟内),因此即使您有NVIDIA GPU,我们建议先安装此版本。
- TensorFlow支持GPU。TensorFlow程序通常在GPU上比在CPU上运行得更快。因此,如果您的系统具有满足以下所示先决条件的NVIDIA®GPU,并且您需要运行性能关键型应用程序,则应最终安装此版本。
Ubuntu和Linux
如果要安装GPU版本的,需要安装一大堆NVIDIA软件(不推荐):
- CUDA®Toolkit 8.0。有关详细信息,请参阅 NVIDIA的文档。确保您将相关的Cuda路径名附加到 LD_LIBRARY_PATH环境变量中,如NVIDIA文档中所述。与CUDA Toolkit 8.0相关的NVIDIA驱动程序。
- cuDNN v5.1。有关详细信息,请参阅 NVIDIA的文档。确保CUDA_HOME按照NVIDIA文档中的描述创建环境变量。
- 具有CUDA Compute Capability 3.0或更高版本的GPU卡。有关支持的GPU卡的列表,请参阅 NVIDIA文档。
- libcupti-dev库,即NVIDIA CUDA Profile Tools界面。此库提供高级分析支持。要安装此库,请发出以下命令:
使用pip安装,分别有2.7和3.6版本的
# 仅使用 CPU 的版本
$ pip install https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.0.1-cp27-none-linux_x86_64.whl
$ pip3 install https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.0.1-cp36-cp36m-linux_x86_64.whl
Mac
macX下也可以安装2.7和3.4、3.5的CPU版本
# 2.7
$ pip install https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.0.1-py2-none-any.whl
# 3.4、3.5
$ pip3 install https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.0.1-py3-none-any.whl三、初识tf
使用 TensorFlow, 你必须明白 TensorFlow:
Tensorflow有一下几个简单的步骤:
- 使用 tensor 表示数据.
- 使用图 (graph) 来表示计算任务.
- 在会话(session)中运行图s
关于新版本
TensorFlow提供多种API。最低级API为您提供完整的编程控制。请注意,tf.contrib.learn这样的高级API可以帮助您管理数据集,估计器,培训和推理。一些高级TensorFlow API(方法名称包含的那些)contrib仍在开发中。某些contrib方法可能会在随后的TensorFlow版本中发生变化或变得过时。这个模块类似于scikit-learn中算法模型。
在 TF 中发生的所有事,都是在会话(Session) 中进行的。所以,当你在 TF 中编写一个加法时,其实你只是设计了一个加法操作,而不是实际添加任何东西。所有的这些设计都是会在图(Graph)中产生,你会在图中保留这些计算操作和张量,而不是具体的值。
图
TensorFlow程序通常被组织成一个构建阶段和一个执行阶段. 在构建阶段, op的执行步骤被描述成一个图. 在执行阶段, 使用会话执行执行图中的op。我们来构建一个简单的计算图。每个节点采用零个或多个张量作为输入,并产生张量作为输出。一种类型的节点是一个常数。像所有TensorFlow常数一样,它不需要任何输入,它输出一个内部存储的值。我们可以创建两个浮点型常量node1 ,node2如下所示:
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0)
print(node1, node2)
最终的打印声明生成
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)
他为什么不是输出结果,那是因为tensorflow中的图形节点操作必须在会话中运行,稍后介绍
构建图
构建图的第一步, 是创建源 op (source op). 源 op 不需要任何输入, 例如 常量 (Constant). 源 op 的输出被传递给其它 op 做运算.TensorFlow Python 库有一个默认图 (default graph), op 构造器可以为其增加节点. 这个默认图对 许多程序来说已经足够用了.,后面我们会接触多个图的使用
默认Graph值始终注册,并可通过调用访问 tf.get_default_graph()
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点,加到默认图中.构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
print tf.get_default_graph(),matrix1.graph,matrix2.graph
重要注意事项:此类对于图形构造不是线程安全的。所有操作都应从单个线程创建,或者必须提供外部同步。除非另有说明,所有方法都不是线程安全的
在会话中启动图
构造阶段完成后,才能启动图。启动图的第一步是创建一个Session对象,如果无任何创建参数,会话构造器将启动默认图。
调用Session的run()方法来执行矩阵乘法op, 传入product作为该方法的参数,会话负责传递op所需的全部输入,op通常是并发执行的。
# 启动默认图.
sess = tf.Session()
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print result
# 任务完成, 关闭会话.
sess.close()
Session对象在使用完后需要关闭以释放资源,当然也可以使用上下文管理器来完成自动关闭动作。
op
计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。一种运算操作代表了一种类型的抽象运算,比如矩阵乘法、加法。tensorflow内建了很多种运算操作,如下表所示:
| 类型 | 示例 |
|---|---|
| 标量运算 | Add、Sub、Mul、Div、Exp、Log、Greater、Less、Equal |
| 向量运算 | Concat、Slice、Splot、Constant、Rank、Shape、Shuffle |
| 矩阵运算 | Matmul、MatrixInverse、MatrixDeterminant |
| 带状态的运算 | Variable、Assign、AssignAdd |
| 神经网络组件 | SoftMax、Sigmoid、ReLU、Convolution2D、MaxPooling |
| 存储、恢复 | Save、Restore |
| 队列及同步运算 | Enqueue、Dequeue、MutexAcquire、MutexRelease |
| 控制流 | Merge、Switch、Enter、Leave、NextIteration |
feed
TensorFlow还提供了feed机制, 该机制可以临时替代图中的任意操作中的tensor可以对图中任何操作提交补丁,直接插入一个 tensor。feed 使用一个 tensor 值临时替换一个操作的输入参数,从而替换原来的输出结果.
feed 只在调用它的方法内有效, 方法结束,feed就会消失。最常见的用例是将某些特殊的操作指定为"feed"操作, 标记的方法是使用 tf.placeholder() 为这些操作创建占位符.并且在Session.run方法中增加一个feed_dict参数
# 创建两个个浮点数占位符op
input1 = tf.placeholder(tf.types.float32)
input2 = tf.placeholder(tf.types.float32)
#增加一个乘法op
output = tf.mul(input1, input2)
with tf.Session() as sess:
# 替换input1和input2的值
print sess.run([output], feed_dict={input1:[7.], input2:[2.]})
如果没有正确提供feed, placeholder() 操作将会产生错误
四、张量的阶和数据类型
TensorFlow用张量这种数据结构来表示所有的数据.你可以把一个张量想象成一个n维的数组或列表.一个张量有一个静态类型和动态类型的维数.张量可以在图中的节点之间流通.其实张量更代表的就是一种多位数组。
阶
在TensorFlow系统中,张量的维数来被描述为阶.但是张量的阶和矩阵的阶并不是同一个概念.张量的阶(有时是关于如顺序或度数或者是n维)是张量维数的一个数量描述.比如,下面的张量(使用Python中list定义的)就是2阶.
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量.
| 阶 | 数学实例 | Python | 例子 |
|---|---|---|---|
| 0 | 纯量 | (只有大小) | s = 483 |
| 1 | 向量 | (大小和方向) | v = [1.1, 2.2, 3.3] |
| 2 | 矩阵 | (数据表) | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 | 3阶张量 | (数据立体) | t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
| n | n阶 | (自己想想看) | .... |
数据类型
Tensors有一个数据类型属性.你可以为一个张量指定下列数据类型中的任意一个类型:
| 数据类型 | Python 类型 | 描述 |
|---|---|---|
| DT_FLOAT | tf.float32 | 32 位浮点数. |
| DT_DOUBLE | tf.float64 | 64 位浮点数. |
| DT_INT64 | tf.int64 | 64 位有符号整型. |
| DT_INT32 | tf.int32 | 32 位有符号整型. |
| DT_INT16 | tf.int16 | 16 位有符号整型. |
| DT_INT8 | tf.int8 | 8 位有符号整型. |
| DT_UINT8 | tf.uint8 | 8 位无符号整型. |
| DT_STRING | tf.string | 可变长度的字节数组.每一个张量元素都是一个字节数组. |
| DT_BOOL | tf.bool | 布尔型. |
| DT_COMPLEX64 | tf.complex64 | 由两个32位浮点数组成的复数:实数和虚数. |
| DT_QINT32 | tf.qint32 | 用于量化Ops的32位有符号整型. |
| DT_QINT8 | tf.qint8 | 用于量化Ops的8位有符号整型. |
| DT_QUINT8 | tf.quint8 | 用于量化Ops的8位无符号整型. |
五、张量操作
在tensorflow中,有很多操作张量的函数,有生成张量、创建随机张量、张量类型与形状变换和张量的切片与运算
生成张量
固定值张量
tf.zeros(shape, dtype=tf.float32, name=None)
创建所有元素设置为零的张量。此操作返回一个dtype具有形状shape和所有元素设置为零的类型的张量。
tf.zeros_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为零相同的类型和形状的张量。
tf.ones(shape, dtype=tf.float32, name=None)
创建一个所有元素设置为1的张量。此操作返回一个类型的张量,dtype形状shape和所有元素设置为1。
tf.ones_like(tensor, dtype=None, name=None)
给tensor定单张量(),此操作返回tensor与所有元素设置为1 相同的类型和形状的张量。
tf.fill(dims, value, name=None)
创建一个填充了标量值的张量。此操作创建一个张量的形状dims并填充它value。
tf.constant(value, dtype=None, shape=None, name='Const')
创建一个常数张量。
用常数张量作为例子
t1 = tf.constant([1, 2, 3, 4, 5, 6, 7])
t2 = tf.constant(-1.0, shape=[2, 3])
print(t1,t2)
我们可以看到在没有运行的时候,输出值为:
('Const:0' shape=(7,) dtype=int32>, 'Const_1:0' shape=(2, 3) dtype=float32>)
一个张量包含了一下几个信息
- 一个名字,它用于键值对的存储,用于后续的检索:Const: 0
- 一个形状描述, 描述数据的每一维度的元素个数:(2,3)
- 数据类型,比如int32,float32
创建随机张量
一般我们经常使用的随机数函数 Math.random() 产生的是服从均匀分布的随机数,能够模拟等概率出现的情况,例如 扔一个骰子,1到6点的概率应该相等,但现实生活中更多的随机现象是符合正态分布的,例如20岁成年人的体重分布等。
假如我们在制作一个游戏,要随机设定许许多多 NPC 的身高,如果还用Math.random(),生成从140 到 220 之间的数字,就会发现每个身高段的人数是一样多的,这是比较无趣的,这样的世界也与我们习惯不同,现实应该是特别高和特别矮的都很少,处于中间的人数最多,这就要求随机函数符合正态分布。
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从截断的正态分布中输出随机值,和 tf.random_normal() 一样,但是所有数字都不超过两个标准差
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None)
从正态分布中输出随机值,由随机正态分布的数字组成的矩阵
# 正态分布的 4X4X4 三维矩阵,平均值 0, 标准差 1
normal = tf.truncated_normal([4, 4, 4], mean=0.0, stddev=1.0)
a = tf.Variable(tf.random_normal([2,2],seed=1))
b = tf.Variable(tf.truncated_normal([2,2],seed=2))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(a))
print(sess.run(b))
输出:
[[-0.81131822 1.48459876]
[ 0.06532937 -2.44270396]]
[[-0.85811085 -0.19662298]
[ 0.13895047 -1.22127688]]
tf.random_uniform(shape, minval=0.0, maxval=1.0, dtype=tf.float32, seed=None, name=None)
从均匀分布输出随机值。生成的值遵循该范围内的均匀分布 [minval, maxval)。下限minval包含在范围内,而maxval排除上限。
a = tf.random_uniform([2,3],1,10)
with tf.Session() as sess:
print(sess.run(a))
tf.random_shuffle(value, seed=None, name=None)
沿其第一维度随机打乱
tf.set_random_seed(seed)
设置图级随机种子
要跨会话生成不同的序列,既不设置图级别也不设置op级别的种子:
a = tf.random_uniform([1])
b = tf.random_normal([1])
print "Session 1"
with tf.Session() as sess1:
print sess1.run(a)
print sess1.run(a)
print sess1.run(b)
print sess1.run(b)
print "Session 2"
with tf.Session() as sess2:
print sess2.run(a)
print sess2.run(a)
print sess2.run(b)
print sess2.run(b)
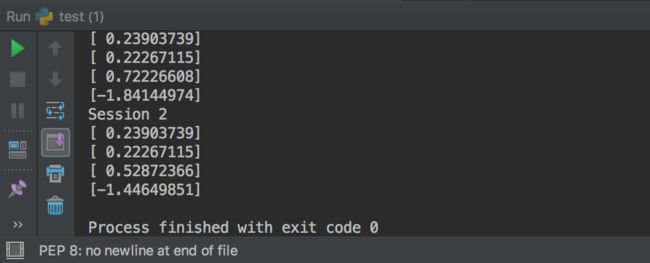
要为跨会话生成一个可操作的序列,请为op设置种子:
a = tf.random_uniform([1], seed=1)
b = tf.random_normal([1])
print "Session 1"
with tf.Session() as sess1:
print sess1.run(a)
print sess1.run(a)
print sess1.run(b)
print sess1.run(b)
print "Session 2"
with tf.Session() as sess2:
print sess2.run(a)
print sess2.run(a)
print sess2.run(b)
print sess2.run(b)
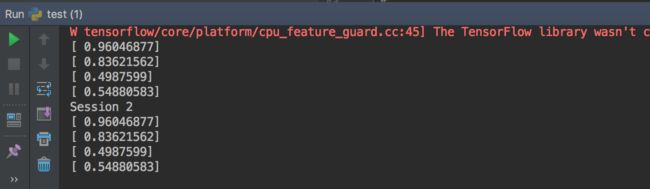
为了使所有op产生的随机序列在会话之间是可重复的,设置一个图级别的种子:
tf.set_random_seed(1234)
a = tf.random_uniform([1])
b = tf.random_normal([1])
print "Session 1"
with tf.Session() as sess1:
print sess1.run(a)
print sess1.run(a)
print sess1.run(b)
print sess1.run(b)
print "Session 2"
with tf.Session() as sess2:
print sess2.run(a)
print sess2.run(a)
print sess2.run(b)
print sess2.run(b)
我们可以看到结果
张量变换
TensorFlow提供了几种操作,您可以使用它们在图形中改变张量数据类型。
改变类型
提供了如下一些改变张量中数值类型的函数
- tf.string_to_number(string_tensor, out_type=None, name=None)
- tf.to_double(x, name='ToDouble')
- tf.to_float(x, name='ToFloat')
- tf.to_bfloat16(x, name='ToBFloat16')
- tf.to_int32(x, name='ToInt32')
- tf.to_int64(x, name='ToInt64')
- tf.cast(x, dtype, name=None)
我们用一个其中一个举例子
tf.string_to_number(string_tensor, out_type=None, name=None)
将输入Tensor中的每个字符串转换为指定的数字类型。注意,int32溢出导致错误,而浮点溢出导致舍入值
n1 = tf.constant(["1234","6789"])
n2 = tf.string_to_number(n1,out_type=tf.types.float32)
sess = tf.Session()
result = sess.run(n2)
print result
sess.close()
形状和变换
可用于确定张量的形状并更改张量的形状
- tf.shape(input, name=None)
- tf.size(input, name=None)
- tf.rank(input, name=None)
- tf.reshape(tensor, shape, name=None)
- tf.squeeze(input, squeeze_dims=None, name=None)
- tf.expand_dims(input, dim, name=None)
tf.shape(input, name=None)
返回张量的形状。
t = tf.constant([[[1, 1, 1], [2, 2, 2]], [[3, 3, 3], [4, 4, 4]]])
shape(t) -> [2, 2, 3]
静态形状与动态形状
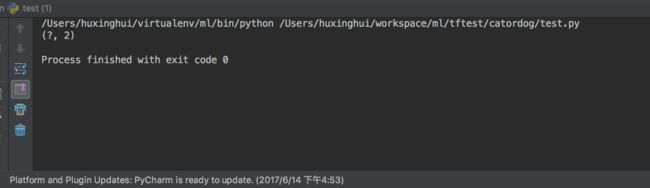
静态维度 是指当你在创建一个张量或者由操作推导出一个张量时,这个张量的维度是确定的。它是一个元祖或者列表。TensorFlow将尽最大努力去猜测不同张量的形状(在不同操作之间),但是它不会总是能够做到这一点。特别是如果您开始用未知维度定义的占位符执行操作。tf.Tensor.get_shape方法读取静态形状
t = tf.placeholder(tf.float32,[None,2])
print(t.get_shape())
结果
动态形状 当你在运行你的图时,动态形状才是真正用到的。这种形状是一种描述原始张量在执行过程中的一种张量。如果你定义了一个没有标明具体维度的占位符,即用None表示维度,那么当你将值输入到占位符时,这些无维度就是一个具体的值,并且任何一个依赖这个占位符的变量,都将使用这个值。tf.shape来描述动态形状
t = tf.placeholder(tf.float32,[None,2])
print(tf.shape(t))
tf.squeeze(input, squeeze_dims=None, name=None)
这个函数的作用是将input中维度是1的那一维去掉。但是如果你不想把维度是1的全部去掉,那么你可以使用squeeze_dims参数,来指定需要去掉的位置。
import tensorflow as tf
sess = tf.Session()
data = tf.constant([[1, 2, 1], [3, 1, 1]])
print sess.run(tf.shape(data))
d_1 = tf.expand_dims(data, 0)
d_1 = tf.expand_dims(d_1, 2)
d_1 = tf.expand_dims(d_1, -1)
d_1 = tf.expand_dims(d_1, -1)
print sess.run(tf.shape(d_1))
d_2 = d_1
print sess.run(tf.shape(tf.squeeze(d_1)))
print sess.run(tf.shape(tf.squeeze(d_2, [2, 4])))
tf.expand_dims(input, dim, name=None)
该函数作用与squeeze相反,添加一个指定维度
import tensorflow as tf
import numpy as np
sess = tf.Session()
data = tf.constant([[1, 2, 1], [3, 1, 1]])
print sess.run(tf.shape(data))
d_1 = tf.expand_dims(data, 0)
print sess.run(tf.shape(d_1))
d_1 = tf.expand_dims(d_1, 2)
print sess.run(tf.shape(d_1))
d_1 = tf.expand_dims(d_1, -1)
print sess.run(tf.shape(d_1))
切片与扩展
TensorFlow提供了几个操作来切片或提取张量的部分,或者将多个张量加在一起
- tf.slice(input_, begin, size, name=None)
- tf.split(split_dim, num_split, value, name='split')
- tf.tile(input, multiples, name=None)
- tf.pad(input, paddings, name=None)
- tf.concat(concat_dim, values, name='concat')
- tf.pack(values, name='pack')
- tf.unpack(value, num=None, name='unpack')
- tf.reverse_sequence(input, seq_lengths, seq_dim, name=None)
- tf.reverse(tensor, dims, name=None)
- tf.transpose(a, perm=None, name='transpose')
- tf.gather(params, indices, name=None)
- tf.dynamic_partition(data, partitions, num_partitions, name=None)
- tf.dynamic_stitch(indices, data, name=None)
其它一些张量运算(了解查阅)
张量复制与组合
- tf.identity(input, name=None)
- tf.tuple(tensors, name=None, control_inputs=None)
- tf.group(inputs, *kwargs)
- tf.no_op(name=None)
- tf.count_up_to(ref, limit, name=None)
逻辑运算符
- tf.logical_and(x, y, name=None)
- tf.logical_not(x, name=None)
- tf.logical_or(x, y, name=None)
- tf.logical_xor(x, y, name='LogicalXor')
比较运算符
- tf.equal(x, y, name=None)
- tf.not_equal(x, y, name=None)
- tf.less(x, y, name=None)
- tf.less_equal(x, y, name=None)
- tf.greater(x, y, name=None)
- tf.greater_equal(x, y, name=None)
- tf.select(condition, t, e, name=None)
- tf.where(input, name=None)
判断检查
- tf.is_finite(x, name=None)
- tf.is_inf(x, name=None)
- tf.is_nan(x, name=None)
- tf.verify_tensor_all_finite(t, msg, name=None) 断言张量不包含任何NaN或Inf
- tf.check_numerics(tensor, message, name=None)
- tf.add_check_numerics_ops()
- tf.Assert(condition, data, summarize=None, name=None)
- tf.Print(input_, data, message=None, first_n=None, summarize=None, name=None)
六、变量的的创建、初始化、保存和加载
其实变量的作用在语言中相当,都有存储一些临时值的作用或者长久存储。在Tensorflow中当训练模型时,用变量来存储和更新参数。变量包含张量(Tensor)存放于内存的缓存区。建模时它们需要被明确地初始化,模型训练后它们必须被存储到磁盘。值可在之后模型训练和分析是被加载。
Variable类
tf.Variable.init(initial_value, trainable=True, collections=None, validate_shape=True, name=None)
创建一个带值的新变量initial_value
initial_value:A Tensor或Python对象可转换为a Tensor.变量的初始值.必须具有指定的形状,除非 validate_shape设置为False.
trainable:如果True,默认值也将该变量添加到图形集合GraphKeys.TRAINABLE_VARIABLES,该集合用作Optimizer类要使用的变量的默认列表
collections:图表集合键列表,新变量添加到这些集合中.默认为[GraphKeys.VARIABLES]
validate_shape:如果False允许使用未知形状的值初始化变量,如果True,默认形状initial_value必须提供.
name:变量的可选名称,默认'Variable'并自动获取
变量的创建
创建当一个变量时,将你一个张量作为初始值传入构造函数Variable().TensorFlow提供了一系列操作符来初始化张量,值初始的英文常量或是随机值。像任何一样Tensor,创建的变量Variable()可以用作图中其他操作的输入。此外,为Tensor该类重载的所有运算符都被转载到变量中,因此您也可以通过对变量进行算术来将节点添加到图形中。
x = tf.Variable(5.0,name="x")
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
biases = tf.Variable(tf.zeros([200]), name="biases")
调用tf.Variable()向图中添加了几个操作:
- 一个variable op保存变量值。
- 初始化器op将变量设置为其初始值。这实际上是一个tf.assign操作。
- 初始值的ops,例如 示例中biases变量的zeros op 也被添加到图中。
变量的初始化
- 变量的初始化必须在模型的其它操作运行之前先明确地完成。最简单的方法就是添加一个给所有变量初始化的操作,并在使用模型之前首先运行那个操作。最常见的初始化模式是使用便利函数 initialize_all_variables()将Op添加到初始化所有变量的图形中。
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
- 还可以通过运行其初始化函数op来初始化变量,从保存文件还原变量,或者简单地运行assign向变量分配值的Op。实际上,变量初始化器op只是一个assignOp,它将变量的初始值赋给变量本身。assign是一个方法,后面方法的时候会提到
with tf.Session() as sess:
sess.run(w.initializer)
通过另一个变量赋值
你有时候会需要用另一个变量的初始化值给当前变量初始化,由于tf.global_variables_initializer()初始化所有变量,所以需要注意这个方法的使用。
就是将已初始化的变量的值赋值给另一个新变量!
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
w2 = tf.Variable(weights.initialized_value(), name="w2")
w_twice = tf.Variable(weights.initialized_value() * 0.2, name="w_twice")
所有变量都会自动收集到创建它们的图形中。默认情况下,构造函数将新变量添加到图形集合GraphKeys.GLOBAL_VARIABLES。方便函数 global_variables()返回该集合的内容。
属性
name
返回变量的名字
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35),name="weights")
print(weights.name)
op
返回op操作
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35))
print(weights.op)
方法
assign
为变量分配一个新值。
x = tf.Variable(5.0,name="x")
w.assign(w + 1.0)
eval
在会话中,计算并返回此变量的值。这不是一个图形构造方法,它不会向图形添加操作。方便打印结果
v = tf.Variable([1, 2])
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# 指定会话
print(v.eval(sess))
# 使用默认会话
print(v.eval())
变量的静态形状与动态形状
TensorFlow中,张量具有静态(推测)形状和动态(真实)形状
- 静态形状:
创建一个张量或者由操作推导出一个张量时,初始状态的形状
- tf.Tensor.get_shape:获取静态形状
- tf.Tensor.set_shape():更新Tensor对象的静态形状,通常用于在不能直接推断的情况下
- 动态形状:
一种描述原始张量在执行过程中的一种形状
- tf.shape(tf.Tensor):如果在运行的时候想知道None到底是多少,只能通过tf.shape(tensor)[0]这种方式来获得
- tf.reshape:创建一个具有不同动态形状的新张量
要点
1、转换静态形状的时候,1-D到1-D,2-D到2-D,不能跨阶数改变形状
2、 对于已经固定或者设置静态形状的张量/变量,不能再次设置静态形状
3、tf.reshape()动态创建新张量时,元素个数不能不匹配
4、运行时候,动态获取张量的形状值,只能通过tf.shape(tensor)[]
管理图中收集的变量
tf.global_variables()
返回图中收集的所有变量
weights = tf.Variable(tf.random_normal([784, 200], stddev=0.35))
print(tf.global_variables())