KMP算法啊啊啊
KMP算法
- 问题引入
- 串
- 引子
- 串的存储
- 顺序存储结构
- 链式存储结构
- 问题来了
- 直观解决方案
- KMP算法
- 前言
- next数组
- KMP算法改进
问题引入
串
引子
我们在生活中可以看到很多的所谓“串”,比如现在我写的这段话就是“串”,更多的,比如我们在网上查找资料,如下图:
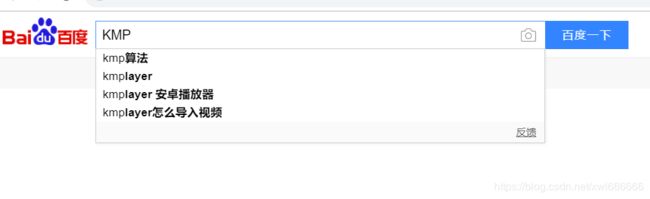
"KMP"就是一个字符串,而每次我们所搜所完之后界面显示带红色的字就是与之匹配的串,其实就是在一个串中找与之匹配的字串,我感觉搜索的想法很简单:我呈现的内容都含有这个字串,那跟你要找的肯定八九不离十啊。好了好了,我现在这种水平还谈什么搜索,还是先弄清楚如何在字符串中寻找到我要寻找的子串。在此之前我们先弄清楚串的存储。
串的存储
无论是找还是存,我们都需要有地方可以操作对不对,不能只是在脑子里瞎想是不是,所有我们得想办法去找块地方,这里呢有两种方式,一种文明点,一种野蛮点,大家都是文明人,所以我先将野蛮一点的方式(好吧,是没什么逻辑…)
顺序存储结构
所谓顺序存储结构就是定义一个数组,然后进行存储,为啥说他野蛮呢,因为这个数组的空间申请完全不用你管,你要你就直接抢一块,用完了,系统替你把他结束,真的是完全不讲道理。
那就把它的结构展示一下:
typedef struct
{
char str[maxSize +1];//maxSize表示串的最大的长度,多加个1是用来储存'\0'的
int length;
}Str;
链式存储结构
文明的链式存储,需要你有礼貌的去申请一段内存,你不申请那肯定就没地方,和链表是很相像的,记得最后用完一定要释放掉这块区域(free),做人要有责任心,有借有还,再借不难!
typedef struct
{
char *ch;
int length;
}Str;
//操作
Str S;
S.ch=(char*)malloc((L+1)*sizeof(char));
/*存储与使用balabal....*/
free(S.ch);
问题来了
知道了两种储存结构之后我们来解决一个小小问题吧!话不多说,冲冲冲!
假如要在一个串"ABABBBAAABABABBA"中找到与"ABABABB"相同的一串,我们习惯把第一串叫做主串,把第二串叫做模式串,如下:
ABABBBAAABABABBA 主串
ABABABB 模式串
想想你该怎么做呢?
直观解决方案
如果你跟我一样是只小菜鸟的话,那咱俩肯定是很投缘的想到了这个地方,没事,别慌,add oil ! 如果你是大佬,也不妨抽个眼神瞧一下凡人的思路…
开始匹配
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | B | A | A | A | B | A | ||
| A | B | A | B | B | B |
如图我们可以看到像我这样菜鸟的思路就是:主串与模式串从第一个开始依次比较,直到不相等停止比较(上图中第五个出现(序号5)不一样的,这时候我们让模式串再从头开始比较,主串则从第二个字符开始,如下图)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | A | B | B | B | A | A | A | B | A | ||
| B | A | B | A | B | B |
很不幸,不相等,那么就让模式串第一个与主串第三个比较:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | B | A | A | A | B | A | ||
| A | B | B | A | B | B |
就这样,不相等继续移动,过了N年~~
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | B | B | A | A | A | B | A | |
| A | B | A | B | A | B | B |
终于发现这里面压根就没有相等的…漫长的等待换来的的这个结果才是最让人崩溃的…
关于我这只菜鸟的解决想法就是用两个循环,第一个用来控制主串移动,第二个用来移动模式串,在发现可以用一个循环解决时我才发现我果然是蒟蒻啊…
这种算法名字还是很实在:暴力算法(BF),当然也有人叫他各种外号:傻瓜、天真…(扎心),不过对我这种蒟蒻还是要看看代码:
int BF(Str str1,Str str2)//主串str1 模式串str2
{
int i=1,j=1,k=i;//定义i移动主串,j用来移动模式串,k用来标记当前比较的初始位置
while(i<=str1.length&&j<=str2.length)//主串和模式串还没比尽
{
if(str1.ch[i]==str2.ch[j])//两个字符相等,看对眼了
{
//移动到下一对新人比较
++j;
++i;
}
else//两个字符不想等,发张好人卡
{
j=1;//模式串回到第一个
i=++k; //从主串下一个开始比较
}
}i
if(j>str2.length)//匹配完成返回,返回找的字串所在的第一个位置
return k;
else//否则返回-1
return -1;
}
(长舒一口气)BF都挺不易,想想高级的KMP算法,肯定难啊!!!别怕,蒟蒻在这里安慰你一下:没事的,没事的,后面还有KMP算法的优化呢(手动滑稽)。
KMP算法
前言
终于到了大佬们相聚的地方。想出这个算法的三个大牛:Kunth、Pratt、Morris,,小弟真是佩服,好了好了,我们来理解一下大佬们的想法(确实是高深…)
如果我们使用BF算法,对于短一点的字符串,可能“嗖!”很快就出来了,可万一这个串长一点,你还这么傻傻的一个一个比,那岂不是等到白了头才能等出答案(特别是答案还没找到),别提多崩溃了。所以我们考虑一下怎么提高代码的高效性,我们把之前比较的部分图放在下面做下研究:
刚开始
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | B | A | A | A | B | A | ||
| A | B | A | B | B | B |
主串第二位比较
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | A | B | B | B | A | A | A | B | A | ||
| B | A | B | A | B | B |
主串第三位比较
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | B | A | A | A | B | A | ||
| A | B | B | A | B | B |
大家一眼就可以看出主串第二位比较是不是啥都没比出来,大佬也是这么觉得,但他们想的比我们更深:既然这步操作没用,为什么我不能选择把这步跳过,只比较有用的?所以我们只保留一三步,听到这里,菜鸟的我有疑问:咋知道这步就一定没用呢?要跳过,哪里该跳?所以我们从一个例子(上面那个例子担心不能完全讲清,所以这里再写了一个)往下继续探索:
给定一个主串ABABAAAABABABABB
要搜索的模式串ABABABB
我们先用BF算法看看该怎么做?
1
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | A | B | A | B | A | B | A | B | A | B | ||
| A | B | A | B | A | B |
2 然后
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | A | B | A | A | B | A | B | A | B | A | B | A | B | ||
| B | A | B | A | B | B |
3 再然后
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | A | A | A | B | B | A | B | A | B | A | B | |
| A | B | A | B | A | B | B |
4 再然后
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | A | A | B | A | B | A | B | A | B | A | B | ||
| B | A | B | A | B | B |
5 再然后
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | A | A | B | A | B | A | B | A | B | A | B | |
| A | B | A | B | A | B | B |
6 再然后
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | A | A | B | A | B | A | B | A | B | A | B | |
| A | B | A | B | A | B | B |
太累了,太累了,就这样吧,我们开始分析:
首先,我们发现第二步没什么作用,我们考虑他能不能省去,我们看,第一步的时候是不是已经知道了主串1~5的子串为ABABA(因为他和模式串匹配上了啊,模式串肯定是已知的啊,你要找的你都不知可就是天下奇谈了)也就是我们知道第二个字符是’B’了,假如我们继续第二步(在已知的串方面)拿主串BABA和模式串ABAB进行比较,很明显,已知的字符串都对不上,何谈要去比那些还没去探查的串?所以我的拙见认为,KMP算法的精髓就在于移动模式串时能让模式串与去与已知的主串部分尽可能地去重和,这样就能简便过程,然后很多资料都是说其实我们只要研究模式串就行了,为什么这么说了,因为已知的主串和与之相对应的模式串是一模一样的啊哈哈哈!你说说假如他们可以匹配,那他们肯定是相同的,不相同才奇怪。所以这个问题我们就变成了只需要研究模式串,看看如何能减少判断次数,这部分是我学习KMP算法最绕的地方,为什么主串不用考虑?为什么要移动到模式串前后缀最大的地方去?,第一个问题我已经解释完了,如果还有什么问题或者更好的理解方式,欢迎在蒟蒻这里留言,好了好了,我们开始解决第二个问题。
对于我们要找的模式串ABABABB,当他与任意主串比较是不是存在以下情况:
0 匹配上0个
A 匹配上1个
AB 匹配上2个
ABA 匹配上3个
ABAB 匹配上4个
ABABA 匹配上5个
ABABAB 匹配上6个
ABABABB 匹配上7个(已找到)
而上图情况是不是也是已知主串的情况(模式串与主串匹配,相等才能匹配上),我们不能预知未知的串字符是不是会相等,所以我们只能减少已知主串与模式串的比较次数,如何减少,便是找各已知串的最大前缀或后缀,即寻找从前往后与从后往前的两部分能相等的最大长度,这个时候你可能会问为什么,没事,我们把下面那个表列出来兴许你会有所启发。
| 匹配上的串 | 最大前缀或后缀 |
|---|---|
| 0 | 0 |
| A | 1(A) |
| AB | 0 |
| ABA | 1(A) |
| ABAB | 2(AB) |
| ABABA | 3(ABA) |
| ABABAB | 4(ABAB) |
| ABABABB | 已找到 |
好吧,我也觉着没啥启发,那我说说,KMP算法简单来说就是将模式串前缀移至后缀位置,如果前后缀为0,就往下移动一次,为什么要前后缀包含了,因为除了前后缀包含,再也找不到能使两个相同的串能重合,前后缀包含使得我们不必再去考虑已知串,而是转而比较位置的字符,假如我们匹配到ABABA相等时发现下一个字符不相等,需要移动的时候,我们如果一个一个移动就是BF算法,把已知的重新看作未知的了。我们想的是如何能够做到移动到某个位置可以接着比较那个没匹配上的字符,而不是把匹配上的再重新进行匹配,最大前后缀把开头的移到结尾不就是这个意思吗?不想判断已经判断的那就只能去找已知串里面重复的。不去找重复的,他们肯定匹配不上,那不就浪费时间了吗?
那可能有人这么说:ABABA中第1、2个字符AB和第3、4个字符AB相等,我可以把1、2位移动至3、4位吗?可以是可以,但是你想想,你这个就是相当于还要比较A(3位)和A(5位)是否相等,这两个相等已经用了一次判断,再比较不显得浪费?何不把他直接移到ABA的位置,
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| A | B | A | B | A(待比较) | 未知 | 未知 |
| A | B | A(待比较) | B | A |
再者,如果第三位和第五位不等怎么办,比如ABABB,那这次移动岂不浪费了。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| A | B | A | B | 未知 | 未知 | |
| A | B | B | B |
那可能又有人说:我不找最大的前后缀行不行?当然不行,如果你不找最大的,那你不是太过了一种可能满足条件的情况吗?自然不行。
啊啊啊,写了好多,可能会看不懂,要是我我也没耐心看下去了,哎,画图不行,太菜…
接着,我们便要想想该如何去寻找最大前后缀,计算机不是人,不能一眼看出,何况长一点的我们人也无法一次看出不是,所以,我们接下来探讨如何求模式串的最大前后缀。
既然是寻找,那么我ta们肯定是有备而来,找到了我们肯定要找地方放好,所以我们接下来将next[]数组存储。
next数组
next数组就是利用找到的最大后缀来实现模式串的匹配(其实也是根据的最大后缀),我们来看看next数组是怎么存储的。和以前学的模拟链表的有点类似,我们将数组存放j应该移动到的位置,例如next[4]=2就表示j到4匹配失败应该将j移动到2位置。现在我们来求一下next数组。
以ABABABB为例
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| A | B | A | B | A | B | B | |
| next[j] | 0 | 1 | 1 | 2 | 3 | 4 | 5 |
这个表是怎么得到的呢,我们规定:
1 当j等于1时,数组值为0,代表j向后移动一位,其实也可以理解0位置到1位置上。
2 当j不为1时,数组值为1~j-1个字符的最大前(或后)缀+1,请看下图;
在发现第五个字符不匹配时:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | A | B | B |
我们要做的就是把1、2位置的AB转移到3、4位置,而此时模式串首字符要在3位置,其实我们不多列几个不难发现规律,next数组的值就是等于前后缀长度+1。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| A | B | A | B | A | B | B | |||
| A | B | A | B | A | B | B |
因此,我们总结一下:
当next[j]=t时,
(1)若j处两者匹配,则next[j+1]=t+1=next[j]+1;
(2)若j处二者不匹配,则令t=next[t],直到满足(1)或者使得t=0。如果t=0,就让next[t+1]=1(让j跳到1位置即移动一次)。
因此,我们可以很自然的写出next数组的代码
void getNext(Str str2,int next[])
{
int j=1,t=0;
next[1]=0;
while(j<str2.length)//没有到最后一个
{
if(t==0||str2.ch[j]==str2.ch[t])//第一个位置直接移动或者判断前后两者是否相等
{
next[j+1]=t+1;//求出next[j+1]
//继续移动
++t;
++j;
}
else//否则移动重新比较
t=next[t];
}
}
next数组求好了我们来写KMP算法的代码,其实我们只需要在我们之前写的BF算法的基础上改动就行。
//int BF(Str str1,Str str2)//主串str1 模式串str2
int KMP(Str str1,Str str2,int next[])//再增加一个next[];
{
//int i=1,j=1,k=i;//定义i移动主串,j用来移动模式串,k用来标记当前比较的初始位置
int i=1,j=1;//已经不需要k这个变量了
while(i<=str1.length&&j<=str2.length)//主串和模式串还没比尽
{
//if(str1.ch[i]==str2.ch[j])//两个字符相等,看对眼了
if(j==0||sre1.ch[i]==str2.ch[j])//要把j=0的情况考虑进去
{
//移动到下一对新人比较
++j;
++i;
}
else//两个字符不想等,发张好人卡
{
//j=1;//模式串回到第一个
//i=++k; //从主串下一个开始比较
j=next[j];//从next[j]位置开始比较
}
}
if(j>str2.length)//匹配完成返回,返回找的字串所在的第一个位置
// return k;
return i-str2.length;
else//否则返回-1
return -1;
}
KMP算法改进
关于改进,其实就是再考虑一些比较特殊的情况,啊啊啊,真是大牛!!!

话不多说,且看情形:
假如有着这样一种情况:
主串:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAB
模式串:AAAAAAB
我们求一下next数组
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| A | A | A | A | A | A | B | |
| next数组 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
是不是发现了,如果j=7不满足,然后j到6位置继续判断…然后一直到1位置,是不是感觉中间那些比较有点鸡肋,我们知道的已知字串没被我们好好使用,我们知道前面都相等的话,只需要让j到那个不相等的地方去,或者到第一个位置去,这就是改进的思路。
void getNextval(Str str2,int nextval[])
{
int j=1,t=0;
nextval[1]=0;
while(j<str2.length)
{
if(t==0||str2.ch[j]==str2.ch[t])
{
if(str2.ch[j+1]!=str2.ch[t+2])
nextval[j+1]=t+1;
else
nextval[j+1]=nextval[t+1];
++j;++t;
}
else
t=nextval[t];
}
}
害,想着这不是结束,KMP算法一定是还可以优化的,与其想想下次又要痛苦的理解别人的思想,为什么不想想优化算法的那个人为什么不能是你我呢?
冲冲冲!!!
可能有些地方确实讲的不好,中途写着也有些累,有些地方感觉没那么"敬业"的说清楚,敬请斧正!欢迎留言相互探讨!