Redis进阶-Redis集群 【高可用切换】&【cluster-require-full-coverage】集群是否完整才能对外提供服务
文章目录
- Pre
- 需求 :集群不完整仍然需要对外提供服务
- 验证
- Redis Cluster 架构
- 高可用切换
- Code访问测试
- 继续停掉8006 ,验证集群是否down掉

Pre
Redis进阶-Redis集群原理剖析及gossip协议初探 中提到了 “ 集群是否完整才能对外提供服务” ,这里我们详细展开验证下
需求 :集群不完整仍然需要对外提供服务
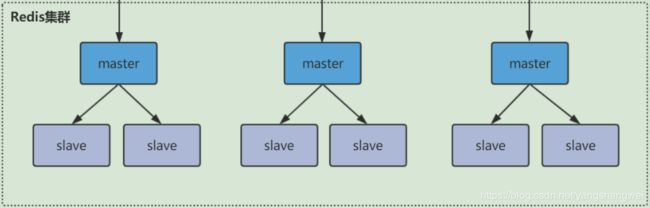
假设我们现在的集群架构是 3主 6从 的redis cluster .
那3个master 平分16384个slot,每个master的小集群 负责 1/3的slot,对应一部分数据。
通常情况,如果这3个小集群中,任何一个(1主2从) 挂了,你这个集群对外可提供的数据只有2/3了, 整个集群是不完整的, redis 默认在这种情况下,是不会对外提供服务的。
如果你的诉求是,集群不完整的话 也需要对外提供服务,比如如下,你也希望redis cluster 对外提供服务
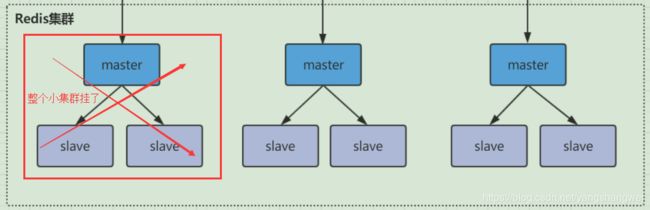
Redis也考虑到了这一点,提供了参数cluster-require-full-coverage
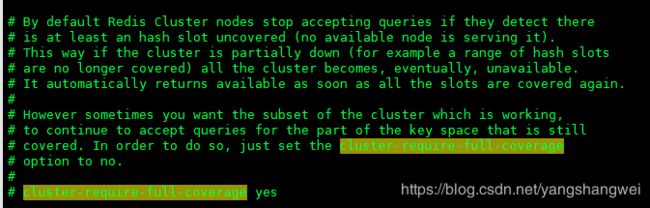
cluster-require-full-coverage: 默认值 yes , 即需要集群完整性,方可对外提供服务 ,
如果你要支持上述你的需求,需要将该参数设置为no ,这样的话,你挂了的那个小集群是不行了,但是其他的小集群仍然可以对外提供服务。
redis.conf中说明和配置如下:
验证
Redis Cluster 架构
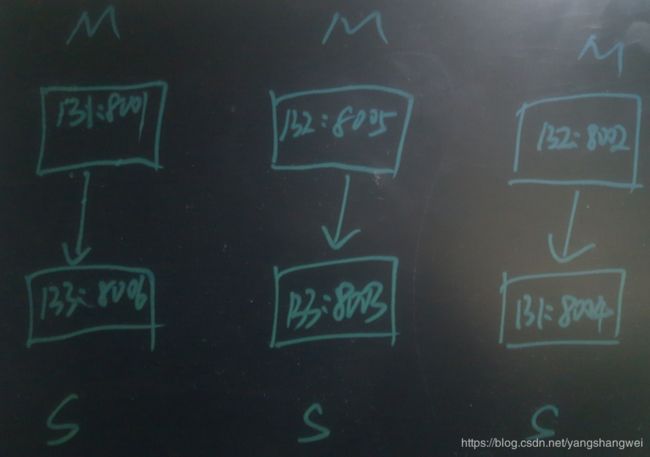
我们先看下默认参数下的场景 , 先看下我们目前的redis nodes 情况 (简单的3主3从)
[redis@artisan bin]$ ./redis-cli -c -h 192.168.18.131 -p 8001 -a artisan
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
192.168.18.131:8001> CLUSTER NODES
3410ea1dd49144f5d02b59036641bde566f03ee0 192.168.18.132:8005@18005 master - 0 1586809003000 10 connected 10923-16383
9a6804a96f9351d3fd61ea1e4d7dd77976b4133b 192.168.18.132:8002@18002 master - 0 1586809002648 3 connected 5461-10922
c4083f856388cc73feb3223433d10500b5556abe 192.168.18.131:8004@18004 slave 9a6804a96f9351d3fd61ea1e4d7dd77976b4133b 0 1586809002547 3 connected
6bff20d4d3564180cb8f4e623d1e0cd9f79b68e1 192.168.18.131:8001@18001 myself,master - 0 1586809001000 9 connected 0-5460
80618eaa0de9524cf439294b7cb6df1a34d3ad22 192.168.18.133:8003@18003 slave 3410ea1dd49144f5d02b59036641bde566f03ee0 0 1586809003961 10 connected
3178d965b77e2967930d7ea6072cdb9d7e5ba8ef 192.168.18.133:8006@18006 slave 6bff20d4d3564180cb8f4e623d1e0cd9f79b68e1 0 1586809003000 9 connected
192.168.18.131:8001>

192.168.18.131:8001主 192.168.18.133:8006从

192.168.18.132:8005 主 192.168.18.133:8003 从

192.168.18.132:8002 主 192.168.18.131:8004从
高可用切换
手工kill 8001 ,模拟故障
[redis@artisan redis-5.0.3]$ cd bin/
[redis@artisan bin]$ ps -ef|grep redis-server
redis 655 597 0 06:06 pts/1 00:00:00 grep --color=auto redis-server
redis 2926 1 0 Apr12 ? 00:09:43 ./redis-5.0.3/bin/redis-server *:8001 [cluster]
redis 2949 1 0 Apr12 ? 00:10:00 ./redis-5.0.3/bin/redis-server *:8004 [cluster]
[redis@artisan bin]$
[redis@artisan bin]$
[redis@artisan bin]$
[redis@artisan bin]$ kill 2926
[redis@artisan bin]$
先看看他的从节点 8006的日志 ,仔细观察日志
7834:S 14 Apr 2020 06:06:19.665 # Connection with master lost.
7834:S 14 Apr 2020 06:06:19.665 * Caching the disconnected master state.
7834:S 14 Apr 2020 06:06:19.804 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:19.804 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:19.804 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:20.812 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:20.812 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:20.813 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:21.822 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:21.822 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:21.822 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:22.831 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:22.832 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:22.833 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:23.843 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:23.844 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:23.844 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:24.849 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:24.849 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:24.849 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:25.858 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:25.858 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:25.858 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:26.542 * FAIL message received from 9a6804a96f9351d3fd61ea1e4d7dd77976b4133b about 6bff20d4d3564180cb8f4e623d1e0cd9f79b68e1
7834:S 14 Apr 2020 06:06:26.542 # Cluster state changed: fail
7834:S 14 Apr 2020 06:06:26.567 # Start of election delayed for 663 milliseconds (rank #0, offset 211176).
7834:S 14 Apr 2020 06:06:26.869 * Connecting to MASTER 192.168.18.131:8001
7834:S 14 Apr 2020 06:06:26.869 * MASTER <-> REPLICA sync started
7834:S 14 Apr 2020 06:06:26.869 # Error condition on socket for SYNC: Connection refused
7834:S 14 Apr 2020 06:06:27.273 # Starting a failover election for epoch 15.
7834:S 14 Apr 2020 06:06:27.309 # Failover election won: I'm the new master.
7834:S 14 Apr 2020 06:06:27.309 # configEpoch set to 15 after successful failover
7834:M 14 Apr 2020 06:06:27.309 # Setting secondary replication ID to eb9734612ef543cff912182e38ad59e531770939, valid up to offset: 211177. New replication ID is 7dc4e4f8a55df7feac1dc7979ea7a783bad2d2e4
7834:M 14 Apr 2020 06:06:27.309 * Discarding previously cached master state.
7834:M 14 Apr 2020 06:06:27.309 # Cluster state changed: ok
看看8005(两位一个主节点)
6926:M 14 Apr 2020 06:06:26.540 * Marking node 6bff20d4d3564180cb8f4e623d1e0cd9f79b68e1 as failing (quorum reached).
6926:M 14 Apr 2020 06:06:26.540 # Cluster state changed: fail
6926:M 14 Apr 2020 06:06:27.305 # Failover auth granted to 3178d965b77e2967930d7ea6072cdb9d7e5ba8ef for epoch 15
6926:M 14 Apr 2020 06:06:27.310 # Cluster state changed: ok
granted to 3178d965b77e2967930d7ea6072cdb9d7e5ba8ef (8006的NodeID) , 主节点回应
再看看 8003 (8005的从节点)
7826:S 14 Apr 2020 06:06:26.543 * FAIL message received from 9a6804a96f9351d3fd61ea1e4d7dd77976b4133b about 6bff20d4d3564180cb8f4e623d1e0cd9f79b68e1
7826:S 14 Apr 2020 06:06:26.543 # Cluster state changed: fail
7826:S 14 Apr 2020 06:06:27.344 # Cluster state changed: ok
从节点不回应
符合我们之前说的集群选举过程。
查看集群状态

可以发现 8006 提升为了主节点 ,8001的状态为fail
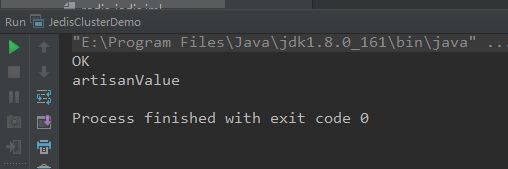
Code访问测试
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class JedisClusterDemo {
public static void main(String[] args) throws IOException {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(20);
config.setMaxIdle(10);
config.setMinIdle(5);
Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();
jedisClusterNode.add(new HostAndPort("192.168.18.131", 8001));
jedisClusterNode.add(new HostAndPort("192.168.18.131", 8004));
jedisClusterNode.add(new HostAndPort("192.168.18.132", 8002));
jedisClusterNode.add(new HostAndPort("192.168.18.132", 8005));
jedisClusterNode.add(new HostAndPort("192.168.18.133", 8003));
jedisClusterNode.add(new HostAndPort("192.168.18.133", 8006));
JedisCluster jedisCluster = null;
try {
//connectionTimeout:指的是连接一个url的连接等待时间
//soTimeout:指的是连接上一个url,获取response的返回等待时间
jedisCluster = new JedisCluster(jedisClusterNode, 6000, 5000, 10, "artisan", config);
System.out.println(jedisCluster.set("clusterArtisan", "artisanValue"));
System.out.println(jedisCluster.get("clusterArtisan"));
} catch (Exception e) {
e.printStackTrace();
} finally {
if (jedisCluster != null)
jedisCluster.close();
}
}
}
继续停掉8006 ,验证集群是否down掉
[redis@artisan log]$ ps -ef|grep 8006
redis 6371 3391 0 06:21 pts/0 00:00:00 grep --color=auto 8006
redis 7834 1 0 Apr12 ? 00:09:30 ./redis-5.0.3/bin/redis-server *:8006 [cluster]
[redis@artisan log]$
[redis@artisan log]$
[redis@artisan log]$ kill 7834
[redis@artisan log]$
[redis@artisan log]$
再次使用代码访问 ,CLUSTERDOWN The cluster is down

结果。。集群宕了。 默认情况下 cluster-require-full-coverage 为 yes ,需要集群完整性,才能对外提供服务
在查看下nodes的状态

如果你想这个时候,还让redis对外提供服务,cluster-require-full-coverage设置为no 即可。
已经验证过了,未记录笔记,周知~