RGCN - Modeling Relational Data with Graph Convolutional Networks 使用图卷积网络对关系数据进行建模 ESWC 2018
文章目录
- 1 相关介绍
- 两个任务
- main contributions
- 2 Neural relational modeling
- 2.1 符号定义
- 2.2 关系图卷积网络R-GCN
- 2.3 Regularization 规则化
- basis decomposition 基函数分解
- block-diagonal decomposition 块对角分解
- 3 节点分类
- 4 链接预测
- 5 实验
- 5.1 实体分类实验
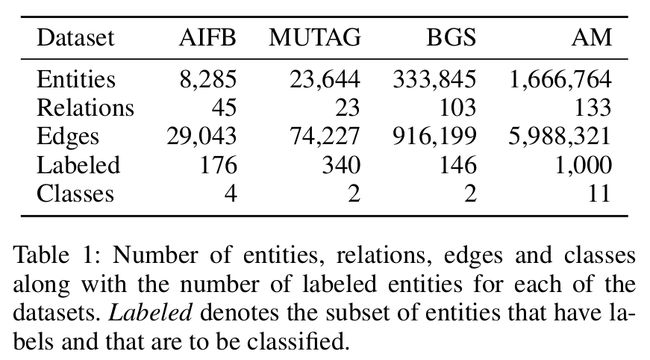
- Datasets
- Baselines
- Results
- 5.2 链路预测实验
- Datasets
- Baselines
- Results
- 参考
论文:Modeling Relational Data with Graph Convolutional Networks 使用图卷积网络对关系数据进行建模
作者:来自于荷兰阿姆斯特丹大学的 Michael Schlichtkrull, Thomas N. Kipf(GCN的作者), Peter Bloem, Rianne van den Berg, Ivan Titov, Max Welling
来源:ESWC 2018
论文链接:https://arxiv.org/abs/1703.06103
Github链接:Graph Convolutional Networks for relational graphs https://github.com/tkipf/relational-gcn
知识图谱支持多种应用,包括问答系统和信息检索。尽管在知识图谱的创建和维护上投入了很大的努力,但是目前最大的知识库(例如 Yago, DBPedia或Wikidata)仍然是不完善的。预测知识库中的缺失信息是统计关系学习(statistical relational learning,SRL)的主要研究内容。
文中引入了关系图卷积网络(R-GCNs),并将其应用于两个标准知识库上完成任务:链接预测(恢复缺失的元组,即subject-predicate-object三元组)和实体分类(为实体分配类型或分类属性)。RGCNs是专门为处理具有高度多关系数据特征的现实知识库而开发的。实验证明了R-GCNs作为实体分类的独立模型的有效性。实验进一步证明,对诸如DistMult这样的链路预测的分解模型的改进是显著的,方法是使用一个编码器模型来在关系图的多个推理步骤上积累证据,结果表明FB15k-237比仅使用一个解码器的baseline提高了29.8%。
1 相关介绍
在之前的SRL研究中,假设知识库存储的都是三元组(subject-predicate-object,主语、谓语、宾语)的集合。 例如(Mikhail Baryshnikov, educated at, Vaganova Academy)三元组,其中Mikhail Baryshnikov和Vaganova Academy表示实体,educated at表示实体之间的关系。并假设实体的标签用类型来表示,例如用university来标记Vaganova Academy。因此实体对应于节点,关系对应于边,就可以把知识库表示为一个有向有标签的多图。

两个任务
考虑SRL中的两个任务:
- 链接预测(恢复缺失的元组)
- 实体分类(为实体分配类型或分类属性)
在这两种情况下,许多丢失的信息都可能存在于通过邻域结构编码的图中。也就是说,知道Mikhail Baryshnikov在Vaganova Academy接受教育,意味着Mikhail Baryshnikov应该有一个标签person,而且三人组(Mikhail Baryshnikov, lived in, Russia)一定属于知识图。
据此,文中为关系图中的实体开发了一个编码器模型,并将其应用于两个任务。
对于实体分类任务,和GCN论文中的类似,都是对图中的每一个节点使用一个softmax分类器。文中使用关系图卷积网络 (R-GCN)来提取每个节点的表示并预测标签。在 (R-GCN)模型中,参数通过优化交叉熵损失函数来学习。
对于链路预测任务可以看作一个自编码器,包括两个部分
- 编码器:一个生成实体的隐含特征表示的R-GCN
- 解码器:一个利用这些表示来预测标记边的张量因子分解模型
虽然原则上解码器可以依赖于任何类型的因子分解(或通常是任何评分函数),但文中使用最简单和最有效的因子分解方法之一的DistMult。
main contributions
- 此文第一个展示了GCN框架可以应用于关系数据建模,特别是链接预测和实体分类任务
- 引入了参数共享和实现稀疏约束的技术,并将其应用于具有大量关系的多图。
- 以DistMult为例,通过使用一个在关系图中执行多步信息传播的编码器模型来加强因子分解模型,可以显著提高它们的性能
2 Neural relational modeling
2.1 符号定义
- 有向有标签的多图: G = ( W , E , R ) G=(\mathcal{W}, \mathcal{E}, \mathcal{R}) G=(W,E,R)
- 节点(实体) v i ∈ V v_{i} \in \mathcal{V} vi∈V,有标签的边(关系) ( v i , r , v j ) ∈ E \left(v_{i}, r, v_{j}\right) \in \mathcal{E} (vi,r,vj)∈E
- r ∈ { 1 , … , R } = R r \in\{1, \ldots, R\}=\mathcal{R} r∈{1,…,R}=R表示关系的类型
2.2 关系图卷积网络R-GCN
R-GCN是对局部邻居信息进行聚合的GCN在大规模关系数据上的扩展。这些GNN的相关方法都可以理解为一个简单可微的消息传递模型的一个特例:
h i ( l + 1 ) = σ ( ∑ m ∈ M i g m ( h i ( l ) , h j ( l ) ) ) (1) \tag{1} h_{i}^{(l+1)}=\sigma\left(\sum_{m \in \mathcal{M}_{i}} g_{m}\left(h_{i}^{(l)}, h_{j}^{(l)}\right)\right) hi(l+1)=σ(m∈Mi∑gm(hi(l),hj(l)))(1)
- g m ( ⋅ , ⋅ ) g_{m}(\cdot, \cdot) gm(⋅,⋅)形式的传入消息被聚合并通过元素激活函数 σ ( ⋅ ) \sigma(\cdot) σ(⋅)传递,例如ReLU(·) = max(0, ·)
- M i \mathcal{M}_{i} Mi表示节点 v i v_i vi的传入消息集,通常选择为传入的边集
- g m ( ⋅ , ⋅ ) g_{m}(\cdot, \cdot) gm(⋅,⋅)通常选择一个针对特定消息,类似于神经网络的函数或一个线性转换 g m ( h i , h j ) = W h j g_{m}\left(h_{i}, h_{j}\right)=W h_{j} gm(hi,hj)=Whj,这个线性转换有一个权重矩阵 W W W,例如在GCN中就是这样的。
这种转换从局部有结构的邻居中聚集、编码特征是非常有效的,对图分类、基于图的半监督节点分类(GCN)
等任务的性能有了很大的提升。
受到这些方法的激发,文中定义了下面的简单的传播模型用于计算在一个关系多图(directed and labeled)中的节点或实体 v i v_i vi的前向更新:
h i ( l + 1 ) = σ ( ∑ r ∈ R ∑ j ∈ N i r 1 c i , r W r ( l ) h j ( l ) + W 0 ( l ) h i ( l ) ) (2) \tag{2} h_{i}^{(l+1)}=\sigma\left(\sum_{r \in \mathcal{R}} \sum_{j \in \mathcal{N}_{i}^{r}} \frac{1}{c_{i, r}} W_{r}^{(l)} h_{j}^{(l)}+W_{0}^{(l)} h_{i}^{(l)}\right) hi(l+1)=σ⎝⎛r∈R∑j∈Nir∑ci,r1Wr(l)hj(l)+W0(l)hi(l)⎠⎞(2)
- N i r \mathcal{N}_{i}^{r} Nir表示在关系 r r r的节点 i i i的邻居集的索引
- c i , r c_{i, r} ci,r是一个正则化常量,可以学习的或者提取选取为 c i , r = ∣ N i r ∣ c_{i, r}=|\mathcal{N}_{i}^{r}| ci,r=∣Nir∣
- 可以使用稀疏矩阵乘法避免对邻居进行显式求和
和GCN不同的是,文中引入了一个relation-specific的转换,也就是依赖于边的类型和方向。
此处采取简单的线性消息转换,其实可以选择更灵活的函数,如多层神经网络(以牺牲计算效率为代价)。

- 图2:R-GCN模型对图中的节点或实体(红色)进行计算更新隐含表示的示意图
- 对每个节点引入了一个特殊的关系类型:自连接
- 深蓝色表示来自于邻居节点激活的特征(d维向量)
- in和out表示两种类型的边
- 每个节点的更新可以用整个图中的共享参数并行计算
2.3 Regularization 规则化
将公式(2)应用于多关系数据的一个核心问题是,图中关系的数量随着参数的数量快速增长而增长。在实践中,这很容易导致过拟合问题。
为了解决这个问题,引入两个独立的方法对R-GCN层进行规则化:基函数分解和块对角分解。两种分解方法都能减少关系非常多的数据(例如现实中的知识库)在训练中需要学习的参数。
basis decomposition 基函数分解
对于基函数分解, W r ( l ) W_{r}^{(l)} Wr(l)定义为
W r ( l ) = ∑ b = 1 B a r b ( l ) V b ( l ) (3) \tag{3} W_{r}^{(l)}=\sum_{b=1}^{B} a_{r b}^{(l)} V_{b}^{(l)} Wr(l)=b=1∑Barb(l)Vb(l)(3)
- 其实就是基 V b ( l ) ∈ R d ( l + 1 ) × d ( l ) V_{b}^{(l)} \in \mathbb{R}^{d^{(l+1)} \times d^{(l)}} Vb(l)∈Rd(l+1)×d(l)和系数 a r b ( l ) a_{r b}^{(l)} arb(l)的线性组合
- 只有系数依赖于关系类型 r r r
- 基函数分解是否可以看作是不同关系类型之间的有效权重共享的一种形式
- 基参数化可以减轻稀有关系(rare relations)数据的过拟合问题,因为稀有关系和更频繁的关系之间共享参数更新
block-diagonal decomposition 块对角分解
W r ( l ) = ⨁ b = 1 B Q b r ( l ) = diag ( Q 1 r ( l ) , … , Q B r ( l ) ) (4) \tag{4} W_{r}^{(l)}=\bigoplus_{b=1}^{B} Q_{b r}^{(l)}=\operatorname{diag}\left(Q_{1 r}^{(l)}, \ldots, Q_{B r}^{(l)}\right) Wr(l)=b=1⨁BQbr(l)=diag(Q1r(l),…,QBr(l))(4)
- W r ( l ) W_{r}^{(l)} Wr(l)是一个块对角矩阵,其中 Q b r ( l ) ∈ R ( d ( l + 1 ) / B ) × ( d ( l ) / B ) Q_{b r}^{(l)} \in \mathbb{R}^{\left(d^{(l+1)} / B\right) \times\left(d^{(l)} / B\right)} Qbr(l)∈R(d(l+1)/B)×(d(l)/B)
- 块对角分解可以看作是对每个关系类型在权重矩阵上的稀疏约束
- 块分解结构的核心:隐含特征可以被分组成变量集,这些变量在组内的耦合比组间的耦合更紧密
对所有的R-GCN模型都采取下面的形式:
- 按公式(2)堆叠 L L L层
- 输入层中的每个节点如果没有其他特征就选择一个one-hot向量作为输入特征
- 对于块分解,用一个简单的线性转换把这个one-hot向量映射到一个稠密的表示
- GCN中使用的就是这种featureless的方法
3 节点分类
对于(半)监督的节点(实体)分类任务,最后一层使用softmax激活函数,并在所有有标签的节点上最小化下面的交叉熵损失函数:
L = − ∑ i ∈ Y ∑ k = 1 K t i k ln h i k ( L ) (5) \tag{5} \mathcal{L}=-\sum_{i \in \mathcal{Y}} \sum_{k=1}^{K} t_{i k} \ln h_{i k}^{(L)} L=−i∈Y∑k=1∑Ktiklnhik(L)(5)
- Y \mathcal{Y} Y是节点的索引集合
- h i k ( L ) h_{i k}^{(L)} hik(L)表示在第 L L L层的有标签的第 i i i个节点的第 k k k个
- t i k t_{i k} tik表示ground truth标签
- 使用(full-batch) gradient descent
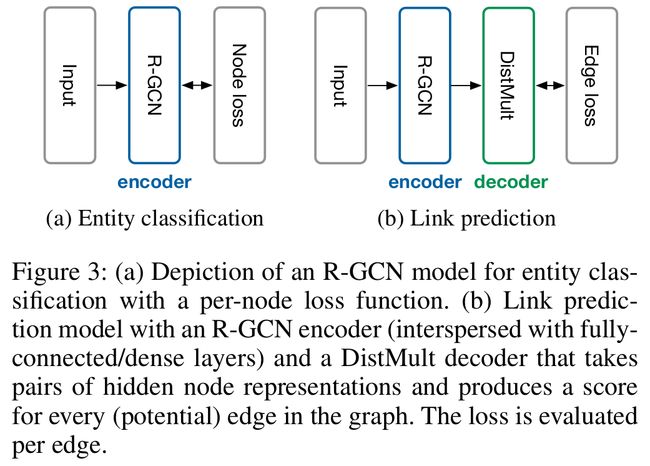
- 图3b表示了文中对预测链路任务提出的R-GCN编码器和DistMult解码器(即,使用DistMult分解作为评分函数)
4 链接预测
链接预测问题目的是预测新的元组 (subject, relation, object))。知识库通常是一个有向有标签的多图: G = ( W , E , R ) G=(\mathcal{W}, \mathcal{E}, \mathcal{R}) G=(W,E,R)。对于这个知识库,并没有给定边的全集 E \mathcal{E} E,而是只给定一个不完全的子集 E ^ \hat \mathcal{E} E^。
任务是为可能的边 ( s , r , o ) (s,r,o) (s,r,o)分配一个分数 f ( s , r , o ) f(s,r,o) f(s,r,o),以确定这些边属于 E \mathcal{E} E的可能性。为了解决这个问题,引入了一个由实体编码器和评分函数(解码器)组成的图形自动编码器。编码器把每个实体 v i ∈ V v_{i} \in \mathcal{V} vi∈V映射到一个真值向量 e i ∈ R d e_{i} \in \mathbb{R}^{d} ei∈Rd。解码器根据节点表示重建图的边;换句话说,它通过函数 s : R d × R × R d → R s: \mathbb{R}^{d} \times \mathcal{R} \times \mathbb{R}^{d} \rightarrow \mathbb{R} s:Rd×R×Rd→R对三元组 (subject, relation, object)进行评分。大部分之前的方法都是在训练的时候对每一个节点 v i v_i vi使用一个真值向量 e i e_i ei进行优化,但是文中使用一个R-GCN编码器,通过 e i = h i ( L ) e_{i}=h_{i}^{(L)} ei=hi(L)来计算节点表示,类似于 Kipf and Welling的GCN论文中为了处理无标签无方向的图而提出的图形自编码器模型。
实验中使用DistMult分解作为评分函数,每个关系 r r r都和一个对角矩阵 R r ∈ R d × d R_{r} \in \mathbb{R}^{d \times d} Rr∈Rd×d有关:
f ( s , r , o ) = e s T R r e o (6) \tag{6} f(s, r, o)=e_{s}^{T} R_{r} e_{o} f(s,r,o)=esTRreo(6)
采用负采样的方式训练模型:对每个观测到的样本,采样 ω \omega ω个负样本。通过corrupting 每个正样本的subject或object进行随机抽样。使用交叉熵损失进行优化,使模型的可观测的正的三元组样本的评分高于负的三元组样本:
L = − 1 ( 1 + ω ) ∣ E ^ ∣ ∑ ( s , r , o , y ) ∈ T y log l ( f ( s , r , o ) ) + ( 1 − y ) log ( 1 − l ( f ( s , r , o ) ) ) (7) \tag{7} \mathcal{L}=-\frac{1}{(1+\omega)|\hat{\mathcal{E}}|} \sum_{(s, r, o, y) \in \mathcal{T}} y \log l(f(s, r, o))+ (1-y) \log (1-l(f(s, r, o))) L=−(1+ω)∣E^∣1(s,r,o,y)∈T∑ylogl(f(s,r,o))+(1−y)log(1−l(f(s,r,o)))(7)
- T \mathcal{T} T表示 real and corrupted 三元组的集合
- l l l表示逻辑sigmoid函数
- y y y是个指示器, y = 1 y=1 y=1表示正样本, y = 0 y=0 y=0表示负样本
5 实验
5.1 实体分类实验
Datasets
Baselines
Results
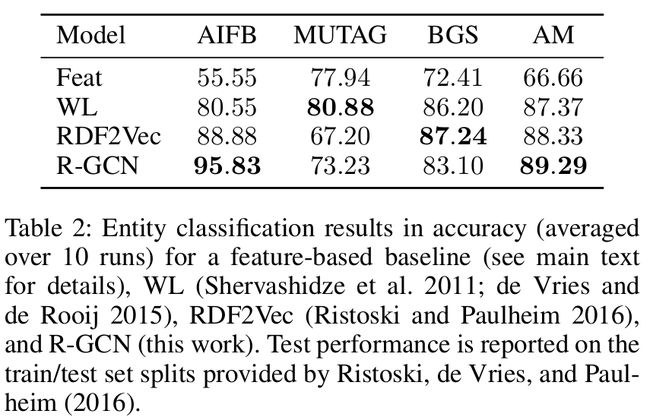
- R-GCN:2-layer model with 16 hidden units (10 for AM)
- c i , r = ∣ N i r ∣ c_{i, r}=\left|\mathcal{N}_{i}^{r}\right| ci,r=∣Nir∣
5.2 链路预测实验
Datasets

Baselines
Results
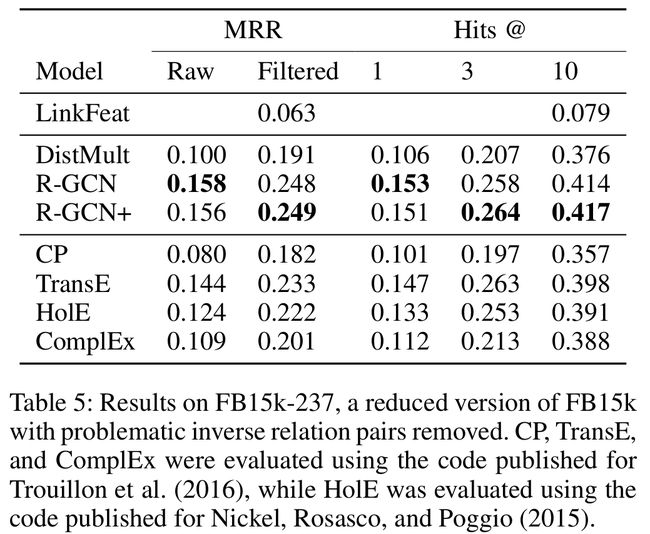
- c i , r = c i = ∑ r ∣ N i r ∣ c_{i, r}=c_{i}=\sum_{r}\left|\mathcal{N}_{i}^{r}\right| ci,r=ci=∑r∣Nir∣


- MRR(Mean Reciprocal Rank):是一个国际上通用的对搜索算法进行评价的机制,即第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。
- FB15k and WN18:使用公式(3)的基函数分解效果更好
- FB15k-237:使用公式(4)的块对角分解效果更好
- dropout rate 0.2 for self-loops and 0.4 for other edges
- 使用L2正则化,惩罚参数 0.01
参考
作者演讲视频:http://videolectures.net/eswc2018_kipf_convolutional_networks/