Flink运行时环境介绍
本文主要是相对Flink作业是如何运行的进行一个大概的介绍,如果有发现的说的不对的地方,非常欢迎在指正!我们一起进步!
一. Apache Flink是什么?
Apache Flink 是一个开源的分布式,高性能,高可用,准确的流处理框架。支持实时流处理和批处理。
无界流 有定义流的开始,但没有定义流的结束。无界流的数据必须持续立即处理,通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。无界流处理通常被称为流式处理。
有界流 有定义流的开始,也有定义流的结束。有界流处理通常被称为批处理
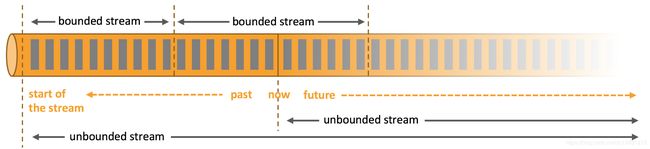
Flink也可以进行批处理,但是在我看来Spark的批处理能力就非常不错了,所以我后续学习FLink打算主要了解它的流式处理能力,批处理方面的能力暂时不做深入的了解。
二. Flink基本架构
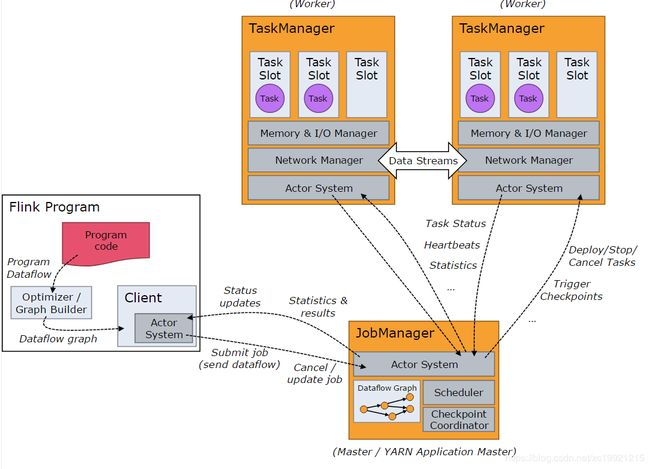
Flink也是Master/Slave架构, 运行时包含两类进程:
JobManagers (类似Spark中的Master)协调分布式计算。它们负责调度任务、协调故障恢复、协调 checkpoints等。
TaskManagers(类似Spark中的Executor)真正执行 dataflow (数据流)中的任务,并且管理所在节点的资源信息,如内存、网络、磁盘等等。
Client(类似Spark中的driver),负责将Flink Job提交到 JobManager 的。提交完成之后,客户端可以断开连接,也可以保持连接来接收进度报告。客户端可以在命令行中运行./bin/flink run ...
从上面来看,Flink的架构和Spark很像,并且也有Local、StandAlone、Yarn、Mesos等多种启动方式。
三. Flink作业分布式运行时环境
Flink Job在Yarn上运行有两种模式,一种是将所有的Job放在一个Flink Session集群运行,称为Yarn Session Model,另外一种是每个Job都单独启动一个Flink Session集群,独占全部资源,称为Single Job Model,生产环境一般都使用后者,避免集群中的多个Job资源抢占问题,而且多个Job一起运行资源也不太好估算。
提交作业命令:
./flink run –m yarn-cluster –p 3 –yjm 1024 –ytm 4096 –ys 3 -ynm jobName –yqu yarn-queue –c com.***.App –d /usr/***/***.jar
参数说明:
- -m 运行模式,这里使用yarn-cluster,即yarn集群模式。
- -p 并行度
- -ys slot个数。
- -ynm Yarn application的名字。
- -yjm job manager 的堆内存大小。
- -ytm task manager 的堆内存大小。
- -d detach模式。可以运行任务后无需再控制台保持连接。
- -c 指定jar包中class全名。
flink1.7之前使用 -yn 这个参数指定TaskManager的数量,但是之后被弃用了。现在TaskManager的数量 = -p / -ys,但是个人发现这样也不太正确,个人觉得,真正的TaskManager的数量是: 实际算子的最大并行度 / -ys,然后向上取整。
举个例子,我在命令行中设置 -p 3 -ys 3,理论上Flink应该只会启动一个TaskManager。但是我手动设置了一个算子的并行度为4,然后它就给我启动了两个TaskManager,所以我得出了上面这个结论。
单个TaskManager上的并行度限制:
如同Spark Executor使用CPU核数限制任务并行度一样,TaskManager使用了Slot概念进行并行度限制,Slot是对内存资源进行隔离,策略是均分。一个TaskManager至少有一个Slot。
一个TaskManager上存在多个Slot意味着多个算子子任务可以共享同一个JVM。同一个JVM进程中同一个Flink Job的任务将共享TCP连接(基于多路复用)和心跳消息。它们也可以共享数据集和数据结构,因此这减少了Slot之间的负载。
任务的并行度:
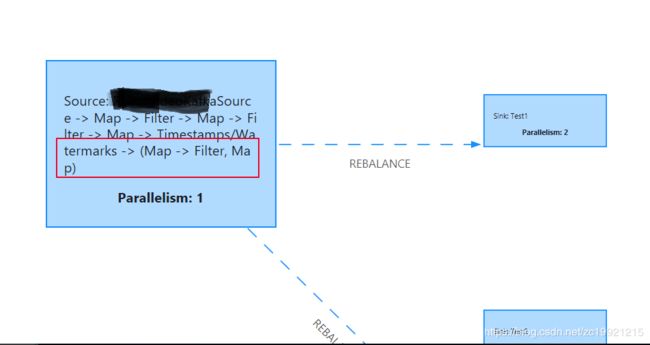
Flink使用并行度来定义某个算子在真正执行时被切分为多少个算子子任务来并行执行。我们编写程序能够形成一个逻辑视图,当实际运行时,逻辑视图中的每个算子会被并行切分为一到多个算子子任务,每个算子子任务处理一部分数据。如下图所示:
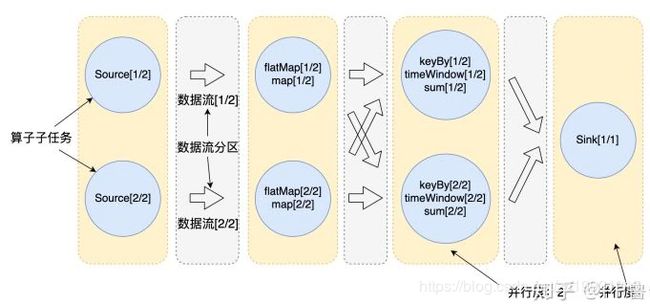
Slot是一个静态概念,表明TaskManager上最多可以并行执行多少个任务。Parallelsim是一个动态的概念,是一个Job实际的并发能力,表示最多会使用多少个Slot,所以并行度的设置应该 <= slot的数目。
并行度与共享Slot
但是如果每个算子的子任务都是单独使用一个Slot,那么就需要很多个Slot,并且不同算子之间切换时就会带来很多线程的切换开销,从而影响吞吐量。所以Flink对算子进行了chain操作,将符合条件的不同算子的subtask放到一个Slot中执行,这样能够减少线程间切换和缓冲的开销,在降低延迟的同时提高了整体吞吐量。
Flink 将多个算子的子任务(subTask)合并成一个 Task(任务),这个过程叫做 Operator Chains,每个任务由一个线程执行,Task是任务运行时的最小单位。如下面几幅图所示:
任务是运行在Thread里面的,不能Chains的任务运行在不同的Thread中

所以Flink Job的并行度设置只要考虑最大的那个算子的并行度即可。
什么情况下才会对task进行链式操作呢?
1. 上下游的并行度一致
2. 算子没有Shuffle
3. 用户没有禁止Chain
……
四. 总结
Flink也是Master/Slave架构,JobManager负责所有任务的总体调度,TaskManager负责运行具体的任务。生产环境中一般一个Flink Job单独创建一个Flink 环境。
TaskManager通过Slot对人物进行并行度的限制。
同一个Job中的subtask可以按照一定的规则共享Slot,所以Flink Job的并行度设置只要考虑最大的那个算子的并行度即可。
ps:可以对一个DataStream进行并行操作
只有当你定义的Function中需要多种输出的时候,才会用到Flink的侧输出流:
参考:
https://segmentfault.com/a/1190000019987618(Flink程序迁移到Yarn下运行速度变慢)
https://www.jianshu.com/p/094fa7b77091
https://blog.csdn.net/wangchunbo_1989/article/details/103195920