基于句子相似度的FAQ问答系统
总结一波我的项目之一,历史久远,要把它理清一下。
Introduce:日趋增多的网络信息使用户很难迅速从搜索引擎返回的大量信息中找到所需内容。自动问答系统为人们提供了以自然语言提问的交流方式,为用户直接返回所需的答案而不是相关的网页,具有方便、快捷、高效等特点。
Process:本文的问答系统采用了一个FAQ(Frequently Asked Questions)问答库,并基于句子相似度进行设计。
1)首先建立一个足够大的问题答案库,即语料库--------建库
2)然后计算用户提问的问题和语料库中各个问题的相似度-------计算相似度-------余弦定理
3)最后把相似度较高的问题所对应的答案返回给用户。-------返回结果
core: 本文的核心是句子相似度的计算,分别使用了TF-IDF和word2vec两种方法对问句进行向量化,并在此基础上使用进行句子相似度的计算。
Improve:为了提高整个系统的运行速度,本文对算法的计算进行了相应的优化。
key words:FAQ;句子相似度;TF-IDF;word2vec;余弦定理
part1: research background and meaning
基于常问问题集的问答系统是在已有的问题答案对的集合中找到与用户提问相匹配的问题,并将其对应的答案直接返回给用户。
问答系统是目前自然语言处理领域的一个研究热点
优点:1)让用户用自然语言句子提问
2)为用户返回一个简洁、准确的答案,而不是一些相关的网页。
与传统的依靠关键字匹配的搜索引擎相比,能够更好地满足用户的检索需求,更准确地找出用户所需的答案,具有方便、快捷、高效等特点。如果用户的提问与以往的记录相符,可直接将对应的答案提交给用户,免去了重新组织答案的过程,可以提高系统的效率。
常问问题集(FAQ)可以作为自动问答系统中的一个组成部分。它把用户经常提问的问题和相关答案保存起来。对于用户输入的问题,可以首先在常问问题库中查找答案。
如果能够找到相应的问题,就可以直接将问题所对应的答案返回给用户,而不需要经过问题理解、信息检索、答案抽取等许多复杂的处理过程,提高了效率。我们提出的FAQ(Frequently Asked Questions)系统在根据用户问题建立候选问题集的基础上,建立常问问题集的倒排索引,提高了系统的检索效率,同时,与传统的基于关键词的方法相比,用基于语义的方法计算相似度提高了问题的匹配精度。
part 2: FAQ Answering System
2.1 Introduction to FAQ Answering System
问答式检索系统允许用户用自然语言提问,从大量异构数据中准确而快速查找出提问的答案,是集自然语言处理技术和信息检索技术与一体的新一代搜索引擎。这种提供准确、简洁的信息的方式更接近于人的思维和习惯,是下一代搜索引擎的发展方向。
FAQ问答系统是一种已有的“问题-答案”对集合中找到与用户提问相匹配的问句,并将其对应的答案返回给用户的问答式检索系统。由于FAQ问答系统免去了重新组织答案的过程,可以提高系统的效率,还可以提高答案的准确性。这其中要解决的一个关键问题是用户问句与“问题-答案”对集合中问句的相似度比较,并把最佳结果返回给用户。
2.2 The "Questions - Answers" Library
FAQ问答系统需要一个“问题-答案”库的支撑,库的好坏直接影响问答系统的效果。本设计所用的“问题-答案”库来源于百度知道的问题和对应的答案,共有10000条。用户输入问题,然后从库中匹配相似度符合设计阈值的问题并显示其答案。
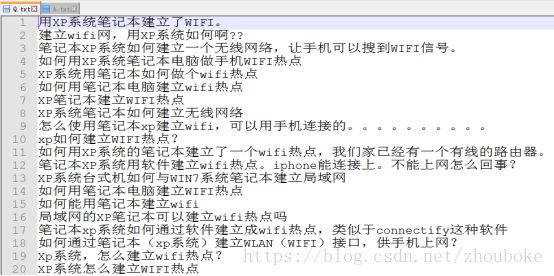
部分问题

部分答案
3 System Design and Implementation
3.1 Design Principles and Flow Charts
思想:把语料库的问题和用户所提问题预处理,然后向量化,最后通过计算两向量之间的余弦夹角值作为衡量相似度的值。只有该余弦值大于程序设定中的阈值才会将这些问题作为候选问题返回给用户。本设计的阈值设置为0.5,同时并选择相似度最高的前5个问题(Top5)所对应的答案返回给用户。若没有大于阈值的样本,则提示用户当前的提问没有相似的答案。系统的设计框图如图3-1所示。

3.2 Pretreatment of Questions
预处理是对问句进行初步处理的过程。本文对评论文本依次进行了去空去重、切词分词和停用词过滤操作。
原始网络评论会存在一些空或重复的问句,须过滤掉这些无价值且影响效率的问句。使用计算机自动地对中文文本进行词语切分的过程称为中文分词(Chinese Word Segmentation),即使中文句子中的词之间有空格标识。若要对一个句子进行分析,就需要将其切分成词的序列,然后以词为单位进行句子的分析,故中文分词是中文自然语言处理中最基本的一个环节。
分词之后需要对每个词进行词性标注,为接下来的停用词过滤提供便利。停用词(Stop Word)指通常在评论文本中出现的频率较高,但对确定评论的情感类别没有作用的词。停用词过滤指去掉评论文本中停用词的过程。本文使用中科院的“计算所汉语词性标记集”以及哈工大停用词表对评论文本进行停用词过滤。根据“计算所汉语词性标记集”,确定出要过滤掉的词性有:标点符号、介词和代词等,这些词性的词信息量低,无类别区分作用。本文先对评论文本进行词性过滤,再根据哈工大停用词表进一步过滤。
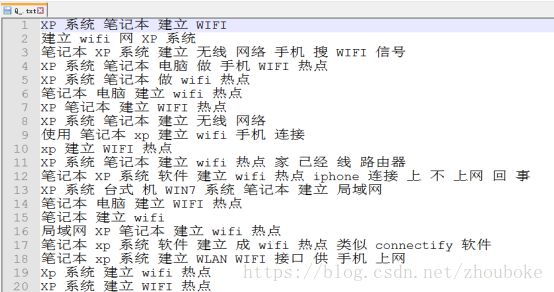
预处理后的部分问句
3.3 Text vectorization
在进行相似度计算之前,需要将每条问句都转换成向量的形式,即将每条问句都映射到一个向量空间,分别使用了两种方法TF-IDF(词频-反向文档频率)和word2vec对问句文本进行向量化。
3.3.1 TFIDF method based on vector space model
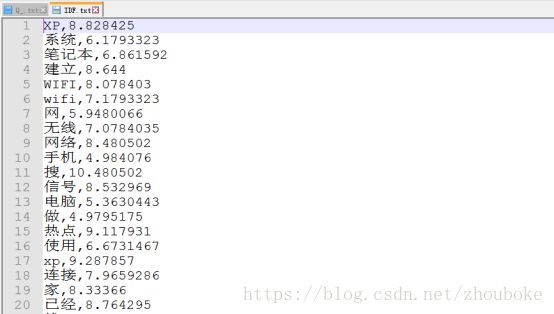
从FAQ中所有预处理后的问句中提取特征后,形成一个词汇表![]() ,则FAQ 中的每一个问句都可以用一个n 维的向量
,则FAQ 中的每一个问句都可以用一个n 维的向量![]() 来表示。
来表示。![]() 的计算方法为:设
的计算方法为:设![]() 为
为![]() 在当前问句中出现的次数,
在当前问句中出现的次数,![]() 为FAQ中含词汇
为FAQ中含词汇![]() 的问句个数,
的问句个数,![]() 为FAQ中问句的总数,那么
为FAQ中问句的总数,那么![]()
![]()
可以看出,一个问句中出现次数多的词将被赋予较高的值,但这样的词并不一定具有较高的值。
eg:汉语中“的”出现的频率非常高,TF值(k值)很大,但“的”在很多问句中都出现,它对于分辨各个问句并没有太大的帮助,它的IDF值是一个很小的数。因此,这种方法综合地考虑了一个词的出现频率和这个词对不同问句的分辨能力。
在计算用户提问问句的n 维向量时,用户提问问句和FQA库中的问句b不是同时向量化的,故在对FQA库中的问句向量化时,需要保存每个特征的ID F值,便于用户提问问句中特征词TFIDF值的计算。
3.3.2 word2vec word vector model
word2vec是用来产生词向量的一组相关模型。它利用输入的语料来产生一个向量空间,在这个向量空间中,每个词对应一个点,语义上相近的词在向量空间上对应的点也相近。
word2vec中两个重要的模型:
CBOW模型(Continuous Bag-of-Words Model)和Skip-gram模型(Continuous Skip-gram Model)。
CBOW模型的思想是用上下文来预测当前词的概率,而Skip-gram模型的思想是用当前词来预测其上下文词的概率。它们的目标函数分别为:![]() 和
和 ![]() 。
。
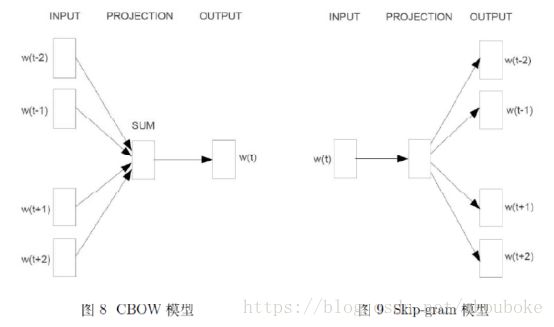
左为CBOW模型,右为Skip-gram模型
本文使用sougou大语料并基于CBOW模型训练得到词向量,然后使用问句中每个特征词对应词向量的算术平均作为问句的句向量。
3.4Calculation of sentence similarity based on cosine theorem
问句之间的相似度可以转换为向量之间的距离来进行度量。距离越小问句之间的相似性越大,反之亦然。
本文采用余弦夹角来计算向量之间的相似度,相似问题一般包含更多相同的特征词,两个问句的主题是否接近,取决于它们的特征向量“长得像不像”。![]() 是用户提问的问句向量,得到
是用户提问的问句向量,得到![]() 和
和![]() 后,它们所对应的两个问句之间的相似度就可以利用和这两个向量之间夹角的余弦值来表示。相似度的计算公式如下所示:
后,它们所对应的两个问句之间的相似度就可以利用和这两个向量之间夹角的余弦值来表示。相似度的计算公式如下所示:
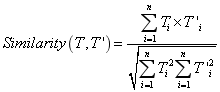
由上述公式可知,![]() 的值越大,说明两者的相似度越高,反之则越低。
的值越大,说明两者的相似度越高,反之则越低。
余弦相似度的定义虽然简单,但是在利用上述公式计算两个向量的夹角时,计算量为![]() ,当用户提出一个问题时,需计算
,当用户提出一个问题时,需计算![]() 次(
次(![]() 为语料库中问句的数量,本文的语料库中的问句数为10000条),如果语料库很大,则将答案返回给用户需要很长的时间。
为语料库中问句的数量,本文的语料库中的问句数为10000条),如果语料库很大,则将答案返回给用户需要很长的时间。
我们这个方案解答需要大概30秒的时间,这个时间对于用户来说过于长,用户体验效果不佳。为了降低计算量,本文在计算相似度时进行了一些简化:
1)首先,分母部分(即向量的模)不需要重复计算,即可以将它们进行预计算,并将预计算的结果保存起来,等计算向量模的时候,直接取出来即可。
2)其次,分子部分,即在计算两个向量的内积时,只需考虑向量中的非零元素,计算复杂度取决于两个向量中非零元素个数的最小值。这两个简化方法在使用TF-IDF向量化时效果比较明显,因为TF-IDF得到的向量极其高维和稀疏,而word2vec得到的向量则是低维和稠密,效果不是很明显。
4 Experimental results and analysis
4.1 Experiment Settings
表4-1 测试问题集
| 具有相似性的问题 |
基本无相似度的问题 |
| 1.小米怎么发彩信啊? |
1.大脸剪什么短发好看 |
| 2.如何成为经理? |
2.怎么做拔丝地瓜 |
| 3.怎样在聚划算卖东西 |
3.华为自动关机为什么 |
| 4.怎样停止建行卡的短信通知? |
4.去哪买手机比较好 |
| 5.你对知音有什么看法 |
5.怎样提高数学成绩 |
| 6.地震你怎么看 |
6.什么翻译软件比较好 |
| 7.选哪个快递?顺丰咋样 |
7.出国去哪里比较好 |
| 8.湖南长沙要穿防晒服吗 |
8.身份证掉了怎么补办 |
| 9.三星I910存储量是多少 |
9.怎样种蓝庭芥 |
| 10.CAD的修剪命令怎么操作? |
10.理八栋谁最帅 |
4.2 Experimental Results and Analysis
基于TF-IDF算法的句子相似度计算方法基本可以回答表4-1中“具有相似性的问题”,而对于表4-1中“基本无相似度的问题”,则会提示用户该问题基于当前的FAQ问答库无法回答,这说明基于相似度的FAQ问答系统完全依赖于语料库。
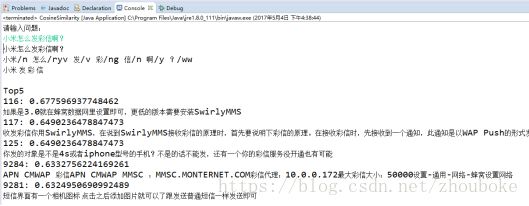
相似问题测试结果
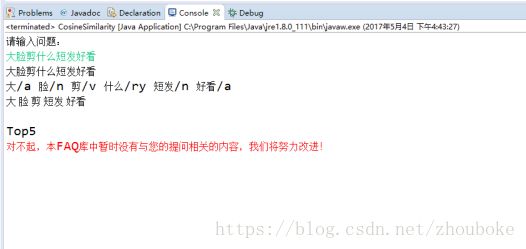
基本无相似度问题测试结果
当输入与语料库中问题相似的问题时,能得到较为正确的答案。
而对于与语料库中问题基本无相似度的问题,系统则会提示用户系统回答不了当前问题。
本文的TF-IDF算法的问答系统设置了相应的阈值,即当用户提问的问句与问答库中的问句相似度大于阈值时,才输出相应的问句所对应的答案,这里阈值是0.5。除此之外,本文对于阈值过滤后的答案,进行排序,先出阈值最高的前5个(Top5)反馈给用户。
基于word2vec的句子相似度计算方法,在计算速度上比基于TF-IDF的方法速度快,因为word2vec训练出来的向量要更低维和稠密。但是由于在进行词向量训练的时候,使用的是sougou大语料,该语料与本文的问句没有太大的关系,故训练出来的词向量不能很好的代表问答领域问句的一些语义信息,故在最终进行测试的时候,计算出来的结果无法达到预期的效果。
5 Summary and Outlook
本文使用了两种句子向量化算法对句子进行向量化:即TF-IDF和word2vec。
这两种向量化算法都能在一定程度上刻画出句子之间的相似度【余弦相似度】。
对于TF-IDF算法,其训练出来的句子向量具有高维、稀疏的缺点,故在计算的时候比较慢,本文针对这个问题对其进行了优化,在一定程度上降低了时间复杂度。
相反,对于word2vec算法,其训练出来的向量具有低维、稠密的优点,计算速度快,但词向量的训练需要大量的语料才能达到好的效果。这次训练语料比较不匹配,得到的向量不能很好地表示句子之间的相似性,效果较差。
由此可见,在进行word2vec词向量的训练时,需要根据具体的问题,使用合适的语料,这样才能更好的表示句子之间的相似度。