Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning
题目与摘要
本文针对什么任务?任务简要介绍下。
针对于节点分类任务
本文发现了什么问题?该文大体是怎么解决的?解决得如何?
传统的GCN的层数不能过多,过多会引起过渡平滑,以及卷积的局部性当标签比较少时,不能将标签传遍全图。
解释下题目。题目起得如何?能概括内容并吸引人吗?
简单明了
介绍
这个任务以往是如何解决的?作者沿着哪条路径继续研究的?为什么?
作者的论文中以往没人解决,所以作者沿着random walk突破GCN的局部特性
目前工作存在什么问题?为什么?你觉得可能还存在什么其他问题?为什么?
1、GCN层数受限,因为拉普拉斯平滑会使其与周围特征区分不明显,层数少的时候有利于分类,层数过多,所有的点都是一样的了。
2、GCN的局部性,当标签过少时,标签传播不到整张图,会降低性能
我:1、Graph的边是固定不变的,如果一开始边的确定就是错误的,那么没有改正机会(有人已经解决了)
2、GCN容易被平滑与CNN比怀疑因为GCN的复杂度比较高,同时CNN的参数少。
3对于距离较远的点如何建立二者之间的联系
感觉很多都在动态图的范围之内了
该文准备如何解决这个问题?为什么可以这样解决?你觉得该文解决这个问题的方法如何?为什么?你觉得可以如何/或更好的解决这个问题?为什么?
本文使用random walk 与GCN一起训练,并进行self-training或者co-training,不需要使用验证集,只要训练集的点到达一定数量就认为全图都被传播遍了。
因为GCN主要受限于局部卷积,所以使用randim walk弥补这一短板
因为标签比较少,不能传播至全图,所以使用self-training co-trainning 在训练集中添加数据。增加点的数量,有利于传播至全图,当训练集点的数量到达一定数量,默认为整张图都被传播到标签了。
我觉得我们应该学会创建边,目前边的权重不进行改变始终是一个bug,但是如何创建边以及确定边的权重依旧是个问题
列出该文贡献(该文自己觉得的)
分析了GCN的局限性
提出了半监督学习来解决
模型
整体介绍(主要是图)
1、证明GCN卷积到最后所有的点的值都相同(看不太懂~~~~找时间继续看T_T)

self-training 将GCN的测试结果比较高的继续放入训练集
co-training 把GCN 和random walk的测试结果高的加入到对方的训练集
Union:将GCN与random walk测试集置信度最高的点的并集加入到GCN的训练集,
Intersection:将GCN与random walk测试集置信度最高的点的交集加入到GCN的训练集,
评估标签传播至全图的方法

模型创新点
使用了random walk弥补了GCN的局部性,同时提出了4种半监督的方法
以及一种评估标签传播至全图的方法
(仅对要进一步跟进的paper)详细介绍模型,从输入到输出,输入矩阵维度,公式等
实验
数据集及评价标准介绍
CiteSeer:
分为六类:Agents、AI(人工智能)、DB(数据库)、IR(信息检索)、ML(机器语言)和HCI,共包含3312篇论文,记录了论文之间引用或被引用信息。去除停用词和在文档中出现频率小于10次的词,整理得到3703个唯一词。CiteSeer数据集包含两个文件:.content文件和.cites文件,其中.content文件描述论文信息的格式为:
但是,Citeseer数据集中的分类太笼统
Cora:
分为6大类,36个小类。主要的文件目录包括:(1)papers:以
PubMed:
关于医学
结果分析
GCN+V:GCN并使用验证集
GCN-V:GCN没有验证集
Cheby :GCN使用切比雪夫多相似的filter(kipf2017)
LP:random walk
Planetoid:Graph embedding
DeepWalk:擅长稀疏的网络
Manireg:半监督算法,应该没有归纳
semi-supervised embedding
iterative classification algorithm (ICA):


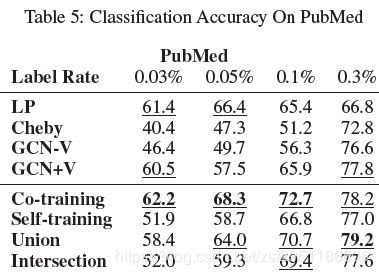
以上在不同测试集大小上的表现,发现以往模型比较依赖已经标注的数据,而半监督在标注数据较少的时候,可以取得比较良好的效果,对比其他模型。
数据集很大时候表现得比较相似

对比其他模型,图比较适用于处理网络结构的数据,明显优于其他模型
运行时间比较快
你觉得这篇paper创新与贡献是(不一定如作者所说)?为什么?
证明了GCN使用拉普拉斯平滑的短板在哪里,并提出了对应的解决方案,但是我认为本文只是提出对Graph的一个比较好的遍历方法,并没有从根本上去解决。
有没有进一步深入的价值?为什么?
可以借鉴其思路,但是深挖不是很好挖
列出该文弱点(或者是你觉得应该是什么问题,他解决的不好,你会如何解决?)
此文确实一定程度上克服GCN需要大量数据才可以获得比较好的性能,但是,往浅了说,不是两个模型集成比较成功,互相弥补短板?
没有涉及到动态图,图不是一成不变的,要学会去更新,这也是很多图模型的shorts,应该有人已经在做了。
每一次卷积后动态调整边的权重,但是因为参数过多,容易引起过拟合
该文对你的启发是?
半监督模型也是一种集成模型的好方法。
列出其中有价值的需要进一步阅读的参考文献