散列表(四):冲突处理的方法之开地址法(二次探测再散列的实现)
前面的文章分析了开地址法的其中一种:线性探测再散列,这篇文章来讲开地址法的第二种:二次探测再散列
(二)、二次探测再散列
为改善“堆积”问题,减少为完成搜索所需的平均探查次数,可使用二次探测法。
通过某一个散列函数对表项的关键码 x 进行计算,得到桶号,它是一个非负整数。

若设表的长度为TableSize = 23,则在线性探测再散列举的例子中利用二次探查法所得到的散列结果如图所示。
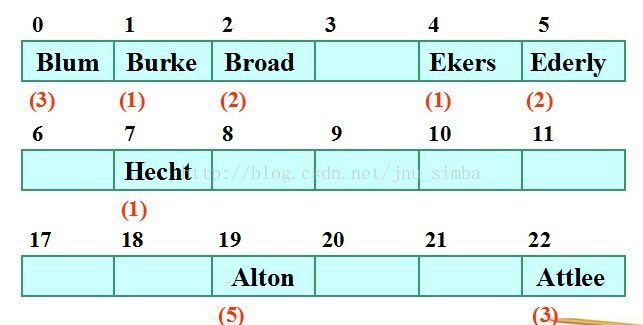
比如轮到放置Blum 的时候,本来应该是位置1,已经被Burke 占据,接着探测 H0 + 1 = 2,,发现被Broad 占据,接着探测 H0 - 1 =
0,发现空位于是放进去,探测次数为3。
下面来看具体代码实现,跟前面讲过的线性探测再散列差不多,只是探测的方法不同,但使用的数据结构也有点不一样,此外还实
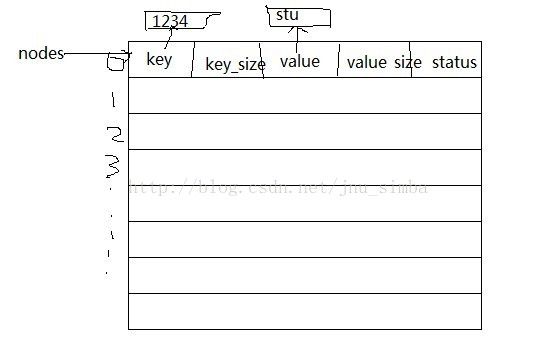
现了开裂,如果装载因子 a > 1/2; 则建立新表,将旧表内容拷贝过去,所以hash_t 结构体需要再保存一个size 成员,同样的原因,
为了将旧表内容拷贝过去,hash_node_t 结构体需要再保存 *key 和 *value 的size。
common.h:
C++ Code
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#ifndef_COMMON_H_
#define_COMMON_H_ #include #include #include #include #include #defineERR_EXIT(m)\ do\ {\ perror(m);\ exit(EXIT_FAILURE);\ }\ while( 0) #endif |
hash.h:
C++ Code
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#ifndef_HASH_H_
#define_HASH_H_ typedef structhashhash_t; typedef unsigned int(*hashfunc_t)( unsigned int, void*); hash_t*hash_alloc( unsigned intbuckets,hashfunc_thash_func); voidhash_free(hash_t*hash); void*hash_lookup_entry(hash_t*hash, void*key, unsigned intkey_size); voidhash_add_entry(hash_t*hash, void*key, unsigned intkey_size, void*value, unsigned intvalue_size); voidhash_free_entry(hash_t*hash, void*key, unsigned intkey_size); #endif /*_HASH_H_*/ |
hash.c:
C++ Code
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 |
#include
"hash.h"
#include "common.h" #include typedef enumentry_status { EMPTY, ACTIVE, DELETED }entry_status_t; typedef structhash_node { enumentry_statusstatus; void*key; unsigned intkey_size; //在拷贝进新的哈希表时有用 void*value; unsigned intvalue_size; //在拷贝进新的哈希表时有用 }hash_node_t; structhash { unsigned intbuckets; unsigned intsize; //累加,如果size>buckets/2,则需要开裂建立新表 hashfunc_thash_func; hash_node_t*nodes; }; unsigned intnext_prime( unsigned intn); intis_prime( unsigned intn); unsigned inthash_get_bucket(hash_t*hash, void*key); hash_node_t*hash_get_node_by_key(hash_t*hash, void*key, unsigned intkey_size); hash_t*hash_alloc( unsigned intbuckets,hashfunc_thash_func) { hash_t*hash=(hash_t*)malloc( sizeof(hash_t)); //assert(hash!=NULL); hash->buckets=buckets; hash->hash_func=hash_func; intsize=buckets* sizeof(hash_node_t); hash->nodes=(hash_node_t*)malloc(size); memset(hash->nodes, 0,size); printf( "Thehashtablehasallocate.\n"); returnhash; } voidhash_free(hash_t*hash) { unsigned intbuckets=hash->buckets; inti; for(i= 0;i if(hash->nodes[i].status!=EMPTY) { free(hash->nodes[i].key); free(hash->nodes[i].value); } } free(hash->nodes); printf( "Thehashtablehasfree.\n"); } void*hash_lookup_entry(hash_t*hash, void*key, unsigned intkey_size) { hash_node_t*node=hash_get_node_by_key(hash,key,key_size); if(node== NULL) { return NULL; } returnnode->value; } voidhash_add_entry(hash_t*hash, void*key, unsigned intkey_size, void*value, unsigned intvalue_size) { if(hash_lookup_entry(hash,key,key_size)) { fprintf(stderr, "duplicatehashkey\n"); return; } unsigned intbucket=hash_get_bucket(hash,key); unsigned inti=bucket; unsigned intj=i; intk= 1; intodd= 1; while(hash->nodes[i].status==ACTIVE) { if(odd) { i=j+k*k; odd= 0; //i%hash->buckets; while(i>=hash->buckets) { i-=hash->buckets; } } else { i=j-k*k; odd= 1; while(i< 0) { i+=hash->buckets; } ++k; } } hash->nodes[i].status=ACTIVE; if(hash->nodes[i].key) ////释放原来被逻辑删除的项的内存 { free(hash->nodes[i].key); } hash->nodes[i].key=malloc(key_size); hash->nodes[i].key_size=key_size; //保存key_size; memcpy(hash->nodes[i].key,key,key_size); if(hash->nodes[i].value) //释放原来被逻辑删除的项的内存 { free(hash->nodes[i].value); } hash->nodes[i].value=malloc(value_size); hash->nodes[i].value_size=value_size; //保存value_size; memcpy(hash->nodes[i].value,value,value_size); if(++(hash->size) return; //在搜索时可以不考虑表装满的情况; //但在插入时必须确保表的装填因子不超过0.5。 //如果超出,必须将表长度扩充一倍,进行表的分裂。 unsigned intold_buckets=hash->buckets; hash->buckets=next_prime( 2*old_buckets); hash_node_t*p=hash->nodes; unsigned intsize; hash->size= 0; //从0 开始计算 size= sizeof(hash_node_t)*hash->buckets; hash->nodes=(hash_node_t*)malloc(size); memset(hash->nodes, 0,size); for(i= 0;i if(p[i].status==ACTIVE) { hash_add_entry(hash,p[i].key,p[i].key_size,p[i].value,p[i].value_size); } } for(i= 0;i
// active or deleted
if(p[i].key) { free(p[i].key); } if(p[i].value) { free(p[i].value); } } free(p); //释放旧表 } voidhash_free_entry(hash_t*hash, void*key, unsigned intkey_size) { hash_node_t*node=hash_get_node_by_key(hash,key,key_size); if(node== NULL) return; //逻辑删除 node->status=DELETED; } unsigned inthash_get_bucket(hash_t*hash, void*key) { unsigned intbucket=hash->hash_func(hash->buckets,key); if(bucket>=hash->buckets) { fprintf(stderr, "badbucketlookup\n"); exit(EXIT_FAILURE); } returnbucket; } hash_node_t*hash_get_node_by_key(hash_t*hash, void*key, unsigned intkey_size) { unsigned intbucket=hash_get_bucket(hash,key); unsigned inti= 1; unsigned intpos=bucket; intodd= 1; unsigned inttmp=pos; while(hash->nodes[pos].status!=EMPTY&&memcmp(key,hash->nodes[pos].key,key_size)!= 0) { if(odd) { pos=tmp+i*i; odd= 0; //pos%hash->buckets; while(pos>=hash->buckets) { pos-=hash->buckets; } } else { pos=tmp-i*i; odd= 1; while(pos< 0) { pos+=hash->buckets; } i++; } } if(hash->nodes[pos].status==ACTIVE) { return&(hash->nodes[pos]); } //如果运行到这里,说明pos为空位或者被逻辑删除 //可以证明,当表的长度hash->buckets为质数且表的装填因子不超过0.5时, //新的表项x一定能够插入,而且任何一个位置不会被探查两次。 //因此,只要表中至少有一半空的,就不会有表满问题。 return NULL; } unsigned intnext_prime( unsigned intn) { //偶数不是质数 if(n% 2== 0) { n++; } for(;!is_prime(n);n+= 2); //不是质数,继续求 returnn; } intis_prime( unsigned intn) { unsigned inti; for(i= 3;i*i<=n;i+= 2) { if(n%i== 0) { //不是,返回0 return 0; } } //是,返回1 return 1; } |
main.c:
C++ Code
|
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
#include
"hash.h"
#include "common.h" typedef structstu { charsno[ 5]; charname[ 32]; intage; }stu_t; typedef structstu2 { intsno; charname[ 32]; intage; }stu2_t; unsigned inthash_str( unsigned intbuckets, void*key) { char*sno=( char*)key; unsigned intindex= 0; while(*sno) { index=*sno+ 4*index; sno++; } returnindex%buckets; } unsigned inthash_int( unsigned intbuckets, void*key) { int*sno=( int*)key; return(*sno)%buckets; } intmain( void) { stu2_tstu_arr[]= { { 1234, "AAAA", 20}, { 4568, "BBBB", 23}, { 6729, "AAAA", 19} }; hash_t*hash=hash_alloc( 256,hash_int); intsize= sizeof(stu_arr)/ sizeof(stu_arr[ 0]); inti; for(i= 0;i hash_add_entry(hash,&(stu_arr[i].sno), sizeof(stu_arr[i].sno), &stu_arr[i], sizeof(stu_arr[i])); } intsno= 4568; stu2_t*s=(stu2_t*)hash_lookup_entry(hash,&sno, sizeof(sno)); if(s) { printf( "%d%s%d\n",s->sno,s->name,s->age); } else { printf( "notfound\n"); } sno= 1234; hash_free_entry(hash,&sno, sizeof(sno)); s=(stu2_t*)hash_lookup_entry(hash,&sno, sizeof(sno)); if(s) { printf( "%d%s%d\n",s->sno,s->name,s->age); } else { printf( "notfound\n"); } hash_free(hash); return 0; } |
simba@ubuntu:~/Documents/code/struct_algorithm/search/hash_table/quardratic_probing$ ./main
The hash table has allocate.
4568 BBBB 23
not found
The hash table has free.