Apollo仿真「训练有素」,长沙无人驾驶出租「轻车熟路」
允中 发自 凹非寺
量子位 报道 | 公众号 QbitAI
书接上回,我们介绍到:百度Apollo无人驾驶出租,已在长沙全面免费开放。
但是!也有不少朋友发来疑问:心里有点担忧,不敢坐。
毕竟之前都是人类司机,应对各种场景和路况有大脑。现在改成AI驾驶,靠不靠谱?
或者更直白来说,百度Apollo的工程师们,到底是经过了怎样的技术考核和保障,才敢放心开放给每一个人乘坐?
于是,奉读者之问,我们找到了Apollo的技术大神们,并且经过「编译」,把这份Apollo无人驾驶出租敢于全民承载的背后技术解析,转述给你听。
来,我们由表及里,一起从现象到本质。
云端练了千万遍,才敢人间坐一回
自动驾驶是个技术活儿,能落地一定得技术上过硬。
我们知道,所有AI模型都需要借助海量数据来训练,而且为了保证训练的效果,数据需要覆盖各个维度、各个方面。在自动驾驶领域,AI技术要应对的场景非常多,比如山路、平地、堵车、高速、国道、市中心、郊区、超车、变道、逆行、闯红灯、横穿马路等各类场景。
在技术快速迭代的过程中,为了保证安全,在自动驾驶车辆上路测试前,需要经过一系列的测试与验证。
这里就需要仿真环境了。
早在2017年,Apollo的仿真环境就已经推出了,当时还是在Apollo 1.0版本的云服务平台模块中。在国内,百度率先真正落地了大规模集群版的仿真平台。
一年后,这一仿真环境再次升级,成为了增强现实的自动驾驶仿真系统(Augmented autonomous driving simulation, AADS),百度的研究人员为共同一作,论文发表在了Science Robotics上。在提升建模真实性方面,百度的仿真器迈出了坚实一步。
在自动驾驶领域的仿真环境中,可以创造出各类复杂路况、危险的突发状况来让AI模型在里面开车,获得丰富的数据。由于是虚拟的仿真环境,因此成本比真实环境低得多,而且没有危险。
所以,AI模型可以在虚拟环境里无数次开车,测试各类环境、挑战各类复杂情境。Apollo在虚拟环境中跑了无数遍,克服了各种艰难险阻之后,就成了安全靠谱的老司机。
因此,下一个问题来了:
仿真环境就是自动驾驶AI的训练场,既然仿真如此重要,那究竟什么样的仿真才能承担得起这样重要的责任?
答案很简单:真实,最大限度的接近真实。
那百度Apollo的自动驾驶仿真环境,又如何实现了真实性?
Apollo仿真世界全角度的”真实性”
前文提到,Apollo通过AADS系统,可以将真实的道路环境复刻建模到仿真环境中。
但光有道路环境是远远不够的,路上还包括路人和车辆,以及多种对象的复杂交互行为,还需考虑无人车自身的特性,包括它的传感器模型,动力学模型、还有对异常情况的识别,这里面维度众多,之间关系极度复杂。
仿真要达到怎样标准,才能完成在真实世界里“确保达到安全性”的要求。这需要仿真系统要尽可能多的发现路上所有可能出现的缺陷,同时不能有太多的误报。总结来说就是令仿真器能够达到对算法效果的预测结论能够无限接近实际路上的真实效果。
为了达到这样的目的,我们从四个维度来一一解析这个问题:
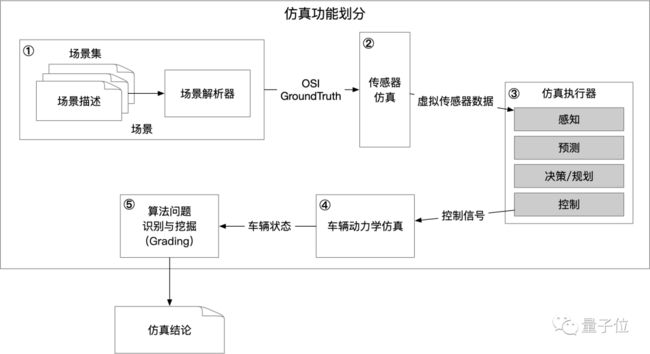
首先,需要考虑的是场景
何为“场景“?
自动驾驶技术要解决的问题是通过人工智能,让无人车能够处理各种复杂路况,在各种情况下都能够安全和优化的行驶。所谓“复杂路况”,在对其进行原子化分割后,在自动驾驶领域称之为“场景”。
一个个场景就是一个个的考题,自动驾驶算法需要在仿真中通过所有的“考题”测试,才能够认为是初步具备了上路的资格。
首先我们要生成道路上车和障碍物所在的静态环境,这个被称为静态环境建模。
静态环境的基础模型是高精地图所包含的地图语义要素,是场景语义分类的重要维度。百度仿真直接基于百度高精地图作为底图来构建整个静态环境。基于百度在高精地图领域深厚的技术以及经验,百度仿真中的静态环境构建精度可以达到厘米级。
△ 社会车辆危险行驶
道路上的车和障碍物不是静止不动的,他们存在一定的交互关系,比如大部分行人都会谨慎的过马路,先看看两边的车辆再走,只有少部分行人会在马路上乱串行;周围大部分车辆都会礼貌的切入,只有少部分车辆会快速切车或别车。
这就需要进行动态环境建模。
动态环境建模指的是在某个场景中,障碍物与车交互的合理性。在仿真环境中,人物和车辆的行为分布比率都要类似真实世界,在同一个场景中,横穿马路的人、正常行走的人、出了故障的停在路上的车、正常行走的车等,这些在真实环境中可能会同时存在的情况在仿真环境里也应当合理的分布。
除了基于规则定义的多样化的障碍物行为,以及基于数据生成的模型来控制障碍物行为外,障碍物的行为还必须足够多样化、足够精细和合理,才可能令仿真的结论达到跟路测结论的一致。
如何达到场景分布的合理性,解决这个问题必须基于海量的真实道路数据。
海量的真实道路数据提供了覆盖更全,刻画更为精细的障碍物+无人车的交互模型,同时满足了障碍物行为的真实性以及多样性需求。
为了满足算法需求,在Apollo的仿真场景集在构成上,在保证覆盖面全面的基础上,更细致的调整了场景集中场景数据的构成方式,使得仿真场景集中的场景出现频率与实际路上的场景频率保持一致。有且仅有趋同的场景分布,仿真结论与路测结论才能一致。
△ 主车障碍车同时向中间车道并道-碰撞风险
Apollo仿真的场景库的基础是百万公里级别的真实路测数据。
一方面,百度的工程师们从大量真实道路数据中提取出更精确的“障碍车与主车的交互/博弈的行为模型”,这样“真实在路上出现过的交互行为”保证了单个障碍物行为的真实性。
另一方面,基于大量的真实道路数据,能够构造出足够丰富的场景种类,保证了Apollo自动驾驶“习题集”对路上多样化场景的高覆盖率,让Apollo无人车在上路前,已经完成了对于路上可能会发生的所有场景的充分验证。
Apollo仿真就是一个对于自动驾驶算法的好的老师。Apollo仿真拥有一个广泛且精确的场景库,能够令算法在足够真实且足够覆盖率的环境下捶打自己的能力,以保证路上效果。
其次,是无人车不可缺少的传感器仿真
无人车,在硬件层面与传统车辆的不同之处,除了AI芯片作为大脑之外,另外两处不同,一个是“传感器组”,另一个是“控制单元”。前者作为无人车的眼睛,为大脑提供源源不断的对外部环境的感知。后者作为无人车的四肢,在大脑的指挥下控制车辆的行为。
在仿真平台中,为了提升运行效率,Apollo仿真需要对这两个“硬件”组件:“传感器”和“控制单元”。对它们进行“软件化变换”,也就是在仿真器中用软件算法来模拟出这两组硬件。
这就是无人车仿真中2个专有名词——传感器仿真,以及车辆动力学仿真。
传感器仿真要让虚拟的传感器有真实的传感器一样的效果?我们不能凭主观感觉来定义传感器仿真的真实性,必须要找到一种客观的量化评估方案。
Apollo的算法设定了大量的评估指标,从多角度刻画“真实数据”特征,以及“仿真数据”特征。通过比对特征,然后通过“补充传感器渲染新功能,以及场景建模细节”逐步缩小评估结果的差距,令传感器仿真的模拟效果与真实传感器采集的数据尽最大可能一致。
正是因为有数百万公里的海量路采数据,才使得Apollo仿真器有能力在各种复杂条件下,都达到更高精度的传感器仿真能力。
仿真也需要大幅度提升虚拟车的控制精度
车辆控制的精度,也就是“AI给车辆下达的命令”和“车辆实际执行效果”的精度问题。
比如说,当自动驾驶车辆在真实世界行驶时,AI命令车辆“前进40厘米”,但实际上考虑到摩擦力等现实因素,车辆可能只前进了30厘米,造成了纵向10厘米的精度误差。
相对于汽车来说,10厘米似乎是个小到可忽略的距离,但是在百度工程师看来,哪怕只有小小的十几厘米的误差,利用仿真去优化对加速度变化率特别敏感的“体感”相关指标,都会带来数倍的体感异常点的漏判及误判,所以要进行车辆动力学仿真。
为了解决这个问题,百度工程师考虑利用海量的路采数据,做了“AI给车辆下达的命令”和“车辆实际执行效果”在大数据下的拟合,这样就得到更真实更精细的动力学模型。这样一种“大数据驱动的动力学模型调优”的方案,也有利于满足未来快速适配多种车型的需求。
最后,我们必须提一下:仿真执行器
前面的几项技术方向属于大家还比较熟悉的仿真功能,这一项虽然隐藏在最底层,但是影响却广泛的。它指的是仿真逻辑在服务器端执行过程中,需要进行的一些特殊设计。
现实世界中有一个熟知而又经常被忽视的物理约束:统一的时空。
所谓“统一时空”指的是:世间万物都在统一的时间和空间中进行相互作用。所有人、车……的1秒,都是一样长的时间,所有人、车……的1米,也都是一样长的距离。
仿真中,统一距离的约束是靠着统一坐标系,而统一时钟的约束就要使用不同于车端的做法。
这是因为仿真器运行的本质是在海量的CPU/GPU的计算资源上运行仿真逻辑,最终“计算出”整个世界,而服务器在执行任何逻辑时会以“多对象并行执行,但单体运行以一种随机的速率”的方式来进行,因此客观世界中“多物体间的统一时钟”的物理规律无法满足。
仿真执行器就是用来完成“强制约束所有的对象能以某个统一的节奏来运转”这样的需求的。
也就是说,因为有了仿真执行器,不同的仿真对象在执行时可以进行某种时间上的节奏同步,进而“模拟出”客观世界上中“统一时间”的概念。
当然,时钟同步还只是“仿真执行器”的一种易于理解的表达。更抽象的表述是,“仿真执行器”完成的是“自动驾驶的数据流在真实物理时间框架下的受控流转”。
真实情况中,在自动驾驶时车端多个模块之间数据流的发送和到达节奏会有大量微小的跳变,而这些数据节奏的跳变会带来车端算法结果的差异化。而精细化的仿真需要能够呈现/生成这样的微小的差异化结果。
什么样的数据节奏?它又带来了怎样的差异化?如何让仿真的结果能够与这样的差异化效果做出精确的拟合?又怎么证明我们的仿真已经实现了足够精确的拟合效果?这些又要从海量的数据中寻找答案了。
Apollo仿真一方面实现了一个令数据流受控的“仿真流控框架”后,也就能够做到消息延迟可自由定制,并且从真实数据中抽取出了延迟模型,用以注入到数据流中,令其整体上仿真运行时能够得到较为真实的“数据节奏波动性”的效果。
同时更重要的一点,是建立了一个“仿真复现率”的自动化的监控体系,持续的对比“真实路测中无人车的车姿数据”以及同场景下的“仿真中虚拟车的车姿数据”,在海量路测数据的验证下,能够证明百度仿真器自身具有足够高精确,足够高的泛化能力的“对真实情况的仿真能力”。
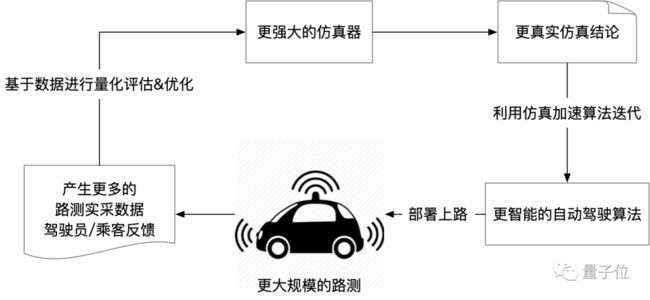
前文中,我们反复强调了数据对于仿真的重要性,仿真和路测并不是存在于不同验证阶段相互独立关系,更不是用仿真代替路测的替代关系。
Apollo百万公里级别的真实路测数据正是仿真优化的基础,仿真优化为算法迭代提供了更大的支持,更优的算法又进一步带来了更大规模的路测里程,而更大规模的路测里程又进一步提升了仿真效果——仿真和路测,在迭代闭环的两端,两者关系实际上一种相互依存相互促进,良性正循环的模式。
未来,全无人驾驶会彻底改变人们的生活。而现在,无人驾驶还只是一个在蹒跚学步的孩子。无人驾驶的仿真,其定位非常明确——它是这个孩子的老师,它需要承担起“支持无人驾驶技术快速成长”的重任。
长沙本地的“典型习题集”
最后,我们从仿真的世界回到现实,百度Apollo无人驾驶出租在长沙全面开放。
针对长沙的地域特殊性,或者实际运营中出现的突发情况,比如前面有人过马路怎么办、有老人拄着拐杖走的特别慢怎么办、碰到强行超车的司机怎么办、恶劣天气看不清路况怎么办、大量送外卖的摩托车行驶在附近怎么办……
在仿真系统里提供专门的“典型习题集”,供AI反复训练测试,找出应对这类问题的最佳途径,不断迭代优化模型,让AI模型对此轻车熟路,提升自己的开车技巧,能够在真实场景中应对这类问题。
而且,这些场景出现的概率需要和长沙本地的情况一致,这样才能得到在长沙运行的真实效果。
比如说,在模拟长沙的仿真环境中,就有以下这些场景:
我在路上好好的跑,右边却突然杀过来一个骑摩托车逆行的配送员:
雨下的很大,摄像头上都是雨滴,看不太清楚,路又特别堵,我好纠结要不要并道:
瓢泼大雨让我的视线模糊,但前面有一辆临时停车的车子,我鼓起勇气试了试,成功绕了过去:
像这样的场景,Apollo仿真平台从真实数据中提取出数千万个,可以说能在行车途中遇到的各种奇怪的人和车、诡异的天气、拥堵不堪的交通状况都囊括在内了。
有了这上千万道题目的“习题集”,AI就可以反复在这些场景训练自己。
毕竟在真实的大马路上,不可能找几十辆车来当“群演”,天天陪着自动驾驶车辆训练,而且万一撞坏了还要赔;而在虚拟的仿真环境里,AI可以无数次用这些“错题”来训练自己,不用担心撞坏,也不用担心“群演”下班,可以潜心修炼,找到最佳的应对方法。
因此,用这种“错题集”的方式来测试AI,就好像每天都在做江苏高考数学题,久而久之水平就比做全国卷的同学高出一大截,训练质量也就高很多了。
所以,也是经过了这样虚拟和现实的无数次打磨,Apollo的工程师们也才敢让全民任意坐。
说个小秘密,在这些无人驾驶工程师眼里,AI系统可比人类可靠、稳定又安全多了。
你觉得呢?
传送门
文中相关内容的论文,有需要的读者可以自取:
AADS: Augmented autonomous driving simulation using data-driven algorithms
https://robotics.sciencemag.org/content/4/28/eaaw0863
An Automated Learning-Based Procedure for Large-scale Vehicle Dynamics Modeling on Baidu Apollo Platform
https://ieeexplore.ieee.org/document/8968102
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
报名 | 不会写代码如何开发对话机器人
5月29日下午14:00,竹间智能Bot Factory™平台发布,0代码开发对话机器人,机器人工厂开盒即用,支持文本、语音、图像情绪识别。
扫码可围观直播~

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !