概率统计之——方差分析
方差分析
1. 概要
方差分析(Analysis of variance, ANOVA) 主要研究分类变量作为自变量时,对因变量的影响是否是显著的。
方差分析的方法是由20世纪的统计学家Ronald Aylmer Fisher在1918年到1925年之间提出并陆续完善起来的,该方法刚开始是用于解决田间实验的数据分析问题,因此,方差分析的学习是和实验设计、实验数据的分析密不可分的。
实验设计和方差分析都有自己相应的语言。因此,在这里我们通过一个焦虑症治疗的实例,先了解一些术语,并且思考一下,方差分析主要用于解决什么样的问题。
以焦虑症治疗为例,现有两种治疗方案:认知行为疗法(CBT)和眼动脱敏再加工法(EMDR)。我们招募10位焦虑症患者作为志愿者,随机分配一半的人接受为期五周的CBT,另外一半接受为期五周的EMDR,设计方案如表1-1所示。在治疗结束时,要求每位患者都填写状态特质焦虑问卷(STAI),也就是一份焦虑度测量的自我评测报告。
表1-1 单因素组间方差分析

在这个实验设计中,治疗方案是两水平(CBT、EMDR)的组间因子。之所以称其为组间因子,是因为每位患者都仅被分配到一个组别中,没有患者同时接受CBT和EMDR。表中字母s代表受试者(患者)。STAI是因变量,治疗方案是自变量。由于在每种治疗方案下观测数相等,因此这种设计也称为均衡设计(balanced design);若观测数不同,则称作非均衡设计(unbalanced design)。
因为仅有一个类别型变量,表1的统计设计又称为单因素方差分析(one-way ANOVA),或进一步称为单因素组间方差分析。方差分析主要通过F检验来进行效果评测,若治疗方案的F检验显著,则说明五周后两种疗法的STAI得分均值不同。
假设你只对CBT的效果感兴趣,则需将10个患者都放在CBT组中,然后在治疗五周和六个月后分别评价疗效,设计方案如表1-2所示。
表1-2 单因素组内方差分析
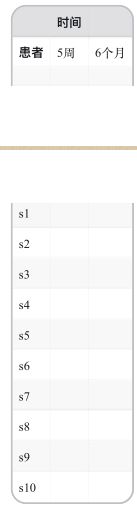
此时,时间(time)是两水平(五周、六个月)的组内因子。因为每位患者在所有水平下都进行了测量,所以这种统计设计称单因素组内方差分析;又由于每个受试者都不止一次被测量,也称作重复测量方差分析。当时间的F检验显著时,说明患者的STAI得分均值在五周和六个月间发生了改变。
现假设你对治疗方案差异和它随时间的改变都感兴趣,则将两个设计结合起来即可:随机分配五位患者到CBT,另外五位到EMDR,在五周和六个月后分别评价他们的STAI结果(见表1-3)。
表1-3 含组间和组内因子的双因素方差分析
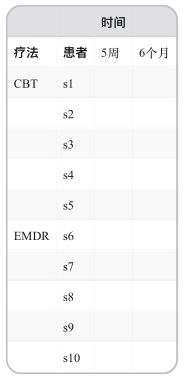
疗法(therapy)和时间(time)都作为因子时,我们既可分析疗法的影响(时间跨度上的平均)和时间的影响(疗法类型跨度上的平均),又可分析疗法和时间的交互影响。前两个称作主效应,交互部分称作交互效应。
当设计包含两个甚至更多的因子时,便是因素方差分析设计,比如两因子时称作双因素方差分析,三因子时称作三因素方差分析,以此类推。若因子设计包括组内和组间因子,又称作混合模型方差分析,当前的例子就是典型的双因素混合模型方差分析。
本例中,你将做三次F检验:疗法因素一次,时间因素一次,两者交互因素一次。若疗法结果显著,说明CBT和EMDR对焦虑症的治疗效果不同;若时间结果显著,说明焦虑度从五周到六个月发生了变化;若两者交互效应显著,说明两种疗法随着时间变化对焦虑症治疗影响不同(也就是说,焦虑度从五周到六个月的改变程度在两种疗法间是不同的)。
现在,我们对上面的实验设计稍微做些扩展。众所周知,抑郁症对病症治疗有影响,而且抑郁症和焦虑症常常同时出现。即使受试者被随机分配到不同的治疗方案中,在研究开始时,两组疗法中的患者抑郁水平就可能不同,任何治疗后的差异都有可能是最初的抑郁水平不同导致的,而不是由于实验的操作问题。抑郁症也可以解释因变量的组间差异,因此它常称为混淆因素(confounding factor)。由于你对抑郁症不感兴趣,它也被称作干扰变数(nuisance variable)。
假设招募患者时使用抑郁症的自我评测报告,比如白氏抑郁症量表(BDI),记录了他们的抑郁水平,那么你可以在评测疗法类型的影响前,对任何抑郁水平的组间差异进行统计性调整。本案例中,BDI为协变量,该设计为协方差分析(ANCOVA)。
以上设计只记录了单个因变量情况(STAI),为增强研究的有效性,可以对焦虑症进行其他的测量(比如家庭评分、医师评分,以及焦虑症对日常行为的影响评价)。当因变量不止一个时,设计被称作多元方差分析(MANOVA), 若协变量也存在, 那么就叫多元协方差分析(MANCOVA)。
下面我们主要介绍单因素方差分析与双因素方差分析的原理与实现。
2 .单因素方差分析
2.1 推导过程
接下来我们使用种小麦的例子,去帮助理解方差分析里涉及的一些变量。
假设我们现在有若干品种的小麦,要在某一地区播种,我们想知道这些品种的产量有没有显著区别,为此我们先设计了一个田间实验,取一大块地将其分成形状大小都相同的 n n n小块.设供选择的品种有 k k k个,我们打算其中的 n 1 n_1 n1小块种植品种1, n 2 n_2 n2小块种植品种2,等等, n 1 + n 2 + . . . n k = n n_1+ n_2 + ... n_k = n n1+n2+...nk=n.
接下来,我们使用方差分析的方法去看不同小麦品种的产量是否有显著差异。
设问题中涉及一个因素 A A A,有 k k k个水平,如上例的 k k k个种子品种,以 Y i j Y_{ij} Yij记第 i i i个水平的第 j j j个观察值,如上例 Y i j Y_{ij} Yij是种植品种 i i i的第 j j j小块地上的亩产量。模型为 Y i j = a i + e i j , j = 1 , . . . , n i , i = 1 , . . . , k ( 2.1 ) Y_{ij} = a_i + e_{ij}, j = 1,...,n_i, i = 1,...,k\qquad(2.1) Yij=ai+eij,j=1,...,ni,i=1,...,k(2.1) a i a_i ai表示水平 i i i的理论平均值,称为水平 i i i的效应。在小麦例子中, a i a_i ai就是品种 i i i的平均亩产量, e i j e_{ij} eij就是随机误差。并且我们假定: E ( e i j ) = 0 , 0 < V a r ( e i j ) = σ 2 < ∞ , 一 切 e i j 独 立 同 分 布 ( 2.2 ) E(e_{ij})=0, 0
接下来,把 S S SS SS分为两部分,一部分表示随机误差的影响,记为 S S e SS_e SSe;另一部分表示因素 A A A的各水平理论平均值 a i a_i ai不同带来的影响,记为 S S A SS_A SSA。
关于 S S e SS_e SSe,先固定一个 i i i,此时对应的所有观测值 Y i 1 , Y i 2 , ⋯ , Y i n Y_{i1},Y_{i2},\cdots,Y_{in} Yi1,Yi2,⋯,Yin,他们之间的差异与每个水平的理论平均值不等无关,而是取决于随机误差,反映这些观察值差异程度的量是 ∑ j = 1 n i ( Y i j − Y i ˉ ) 2 \sum_{j=1}^{n_i}\left ( Y_{ij}-\bar{Y_i} \right )^2 ∑j=1ni(Yij−Yiˉ)2,其中 Y i ˉ = ( Y i 1 + Y i 2 + ⋯ + Y i n ) / n i , i = 1 , 2 , ⋯ , n ( 2.5 ) \bar{Y_i}=(Y_{i1}+Y_{i2}+\cdots+Y_{in})/n_i,\quad i=1, 2,\cdots,n \qquad (2.5) Yiˉ=(Yi1+Yi2+⋯+Yin)/ni,i=1,2,⋯,n(2.5) Y i ˉ \bar{Y_i} Yiˉ可以视为对 a i a_i ai的估计。把上述平方和做累加得: S S e = ∑ i = 1 k ∑ j = 1 n i ( Y i j − Y i ˉ ) 2 ( 2.6 ) SS_e=\sum_{i=1}^{k}\sum_{j=1}^{n_i}\left ( Y_{ij}-\bar{Y_i} \right )^2 \qquad (2.6) SSe=i=1∑kj=1∑ni(Yij−Yiˉ)2(2.6) 可求得 S S A SS_A SSA:

因为 Y i ˉ \bar{Y_i} Yiˉ可以视为对 a i a_i ai的估计, a i a_i ai的差异越大, Y i ˉ \bar{Y_i} Yiˉ之间的差异也越大,所以 S S A SS_A SSA可以用来衡量不同水平之间的差异程度。
在统计学上,通常称 S S SS SS为总平方和, S S A SS_A SSA为因素 A A A的平方和, S S e SS_e SSe为误差平方和,分解式 S S = S S A + S S e SS=SS_A+SS_e SS=SSA+SSe为该模型的方差分析。
基于上面的分析,我们可以得到假设(2.8)的一个检验方法:当比值 S S A / S S e SS_A/SS_e SSA/SSe大于某一给定界限时,否定 H 0 H_0 H0,不然就接受 H 0 H_0 H0。为了构造 F F F分布的检验统计量,我们假定随机误差 e i j e_{ij} eij满足正态分布 N ( 0 , σ 2 ) N(0, \sigma^2) N(0,σ2),同时我们也假定观察值 Y i j Y_{ij} Yij符合正态分布,此时,记 M S A = S S A / ( k − 1 ) , M S e = S S e / ( n − k ) ( 2.8 ) MS_A = SS_A/(k-1), \quad MS_e = SS_e/(n-k) \qquad (2.8) MSA=SSA/(k−1),MSe=SSe/(n−k)(2.8) 当 H 0 H_0 H0成立时,有: M S A / M S e ∼ F k − 1 , n − k ( 2.9 ) MS_A / MS_e \sim F_{k-1, n-k} \qquad (2.9) MSA/MSe∼Fk−1,n−k(2.9) 据(2.9),在给定显著性水平 α \alpha α时,即得(2.10)的假设 H 0 H_0 H0的检验如下: 当 M S A / M S e ⩽ F k − 1 , n − k ( α ) 时 , 接 受 H 0 , 不 然 就 拒 绝 H 0 ( 2.10 ) 当MS_A / MS_e \leqslant F_{k-1, n-k}(\alpha)时,接受H_0,不然就拒绝H_0 \qquad (2.10) 当MSA/MSe⩽Fk−1,n−k(α)时,接受H0,不然就拒绝H0(2.10) M S A MS_A MSA和 M S e MS_e MSe分别被称为因素 A A A和随机误差的平均平方和。被除数 k − 1 k-1 k−1和 n − k n-k n−k,分别称为这两个平方和的自由度。 M S e MS_e MSe的自由度为什么是 n − k n-k n−k呢?因为平方和 ∑ j = 1 n i ( Y i j − Y i ˉ ) 2 \sum_{j=1}^{n_i}\left ( Y_{ij}-\bar{Y_i} \right )^2 ∑j=1ni(Yij−Yiˉ)2的自由度为 n i − 1 n_i-1 ni−1,故对 i i i求和, S S e SS_e SSe的自由度就是 n − k n-k n−k。那么, M S A MS_A MSA的自由度为什么是 k − 1 k-1 k−1呢?因为一共有 k k k个平均值 a 1 , ⋯ , a k a_1,\cdots,a_k a1,⋯,ak等 k − 1 k-1 k−1个,故自由度为 k − 1 k-1 k−1,两者自由度之和为 n − 1 n-1 n−1,恰好是总平方和的自由度。
到这里,我们可以做出方差分析表如表2-1
2-1 单因素方差分析的方差分析表

在上表中,对于显著性一栏,一般来说,我们把算出的 F F F比,即 M S A / M S e MS_A / MS_e MSA/MSe,与 F k − 1 , n − k ( 0.05 ) = c 1 F_{k-1, n-k}(0.05)=c_1 Fk−1,n−k(0.05)=c1和 F k − 1 , n − k ( 0.01 ) = c 2 F_{k-1, n-k}(0.01)=c_2 Fk−1,n−k(0.01)=c2比较。若 M S A / M S e > c 2 MS_A / MS_e>c_2 MSA/MSe>c2,用**表示,表明A因素的效应是高度显著的,即在 α = 0.01 \alpha=0.01 α=0.01的显著性水平下,拒绝原假设(5.3)。同理, c 2 < M S A / M S e < c 1 c_2
3 双因素方差分析
3.1 推导过程
在很多种情况下,只考虑一个指标对观察值的影响,显然是不够的,这时就会用到多因素方差分析。双因素方差分析和多因素方差分析在原理上是相似的,这里为了书写简便,我们只以双因素方差分析为例进行推导。
还是以田间实验的例子帮助理解推导过程,我们设有两个因素 A , B A, B A,B,分别有 k , l k, l k,l个水平(例如 A A A为品种,有 k k k个; B B B为播种量,考虑 l l l种不同的数值,如20斤/亩,25斤/亩,……). A A A的水平 i i i与 B B B的水平 j j j的组合记为 ( i , j ) (i,j) (i,j),其试验结果记为 Y i j , i = 1 , ⋅ ⋅ ⋅ , k , j = 1 , … , l Y_{ij}, i = 1, · · ·, k,j = 1,…, l Yij,i=1,⋅⋅⋅,k,j=1,…,l.统计模型定为 Y i j = μ + a i + b j + e i j , i = 1 , ⋅ ⋅ ⋅ , k , j = 1 , ⋅ ⋅ ⋅ , l ( 3.1 ) Y_{ij} = \mu + a_i + b_j + e_{ij},i= 1, · · ·, k,j = 1,· · ·, l\qquad (3.1) Yij=μ+ai+bj+eij,i=1,⋅⋅⋅,k,j=1,⋅⋅⋅,l(3.1) 为解释这模型,首先把右边分成两部分: e i j e_{ij} eij为随机误差,它包含了未加控制的因素( A , B A,B A,B以外的因素)及大量随机因素的影响.假定 E ( e i j ) = 0 , 0 < V a r ( e i j ) = σ 2 < ∞ , 一 切 e i j 独 立 同 分 布 ( 3.2 ) E(e_{ij})=0, 0
μ + a ˉ + b ˉ \mu + \bar{a}+\bar{b} μ+aˉ+bˉ, a i a_i ai换为 a i − a ˉ a_i-\bar{a} ai−aˉ, b j b_j bj换为 b j − b ˉ b_j-\bar{b} bj−bˉ,则 ( 3.1 ) (3.1) (3.1)式不变,而 ( 3.3 ) (3.3) (3.3)式成立。
约束条件 ( 3.3 ) (3.3) (3.3)给了 a i , b j a_i,b_j ai,bj的意义一种更清晰的解释: a i > 0 a_i>0 ai>0 表示A的水平 i i i的效应在 A A A的全部水平的平均效应之上, a i < 0 a_i<0 ai<0 则相反。另外,这个约束条件也给了 μ , a i , b j \mu,a_i,b_j μ,ai,bj的 一个适当的估计法:把 Y i j Y_{ij} Yij对一切 i , j i,j i,j相加.注意到 ( 3.3 ) (3.3) (3.3),有 ∑ i = 1 k ∑ j = 1 l Y i j = k l μ + ∑ i = 1 k ∑ j = 1 l e i j ( 3.4 ) \sum_{i=1}^{k}\sum_{j=1}^{l}Y_{ij}= kl\mu+\sum_{i=1}^{k}\sum_{j=1}^{l}e_{ij} \qquad (3.4) i=1∑kj=1∑lYij=klμ+i=1∑kj=1∑leij(3.4) 由 ( 3.2 ) (3.2) (3.2)得, Y ˉ = ∑ i = 1 k ∑ j = 1 l Y i j / k l ( 3.5 ) \bar{Y}=\sum_{i=1}^{k}\sum_{j=1}^{l}Y_{ij}/kl \qquad (3.5) Yˉ=i=1∑kj=1∑lYij/kl(3.5) 是 μ \mu μ的一个无偏估计。其次,有 ∑ j = 1 l Y i j = l μ + l a + ∑ j = 1 l e i j ( 3.6 ) \sum_{j=1}^{l}Y_{ij}=l\mu+la+\sum_{j=1}^{l}e_{ij} \qquad (3.6) j=1∑lYij=lμ+la+j=1∑leij(3.6) 于是,记
Y i ˉ = ∑ j = 1 l Y i j / l , Y j ˉ = ∑ i = 1 k Y i j / k ( 3.7 ) \bar{Y_i}=\sum_{j=1}^{l}Y_{ij}/l, \quad \bar{Y_j}=\sum_{i=1}^{k}Y_{ij}/k \qquad (3.7) Yiˉ=j=1∑lYij/l,Yjˉ=i=1∑kYij/k(3.7) 由 ( 3.7 ) (3.7) (3.7)知, Y j ˉ \bar{Y_j} Yjˉ为 μ + a i \mu+a_i μ+ai的一个无偏估计。于是得到 a i a_i ai的一个无偏估计为 a i ^ = Y i ˉ − Y ˉ , i = 1 , ⋯ , k ( 3.8 ) \hat{a_i}=\bar{Y_i}-\bar{Y}, i=1,\cdots,k \qquad(3.8) ai^=Yiˉ−Yˉ,i=1,⋯,k(3.8) 同理, b j ^ = Y j ˉ − Y ˉ , j = 1 , ⋯ , l ( 3.9 ) \hat{b_j}=\bar{Y_j}-\bar{Y}, j=1,\cdots,l \qquad(3.9) bj^=Yjˉ−Yˉ,j=1,⋯,l(3.9) a i ^ , b j ^ \hat{a_i},\hat{b_j} ai^,bj^适合约束条件 ( 3.3 ) (3.3) (3.3)。
下面进行方差分析,要设法把总平方和 S S = ∑ i = 1 k ∑ j = 1 l ( Y i j − Y ˉ ) 2 SS=\sum_{i=1}^{k}\sum_{j=1}^{l}(Y_{ij}-\bar{Y})^2 SS=i=1∑kj=1∑l(Yij−Yˉ)2 分解为三部分: S S A , S S B , S S e SS_A,SS_B,SS_e SSA,SSB,SSe,分别表示因素 A , B A,B A,B和随机误差的影响。这种分解的主要目的是假设检验: H 0 A : a 1 = ⋯ = a k = 0 ( 3.10 ) H_{0A}:a_1=\cdots=a_k=0 \qquad(3.10) H0A:a1=⋯=ak=0(3.10) 和 H 0 B : b 1 = ⋯ = b k = 0 ( 3.11 ) H_{0B}:b_1=\cdots=b_k=0 \qquad(3.11) H0B:b1=⋯=bk=0(3.11)
H 0 A H_0A H0A成立表示因素 A A A对指标其实无影响。在实际问题中,绝对无影响的场合少见,但如影响甚小以致被随机误差所掩盖时,这种影响事实上等于没有。因此,拿 S S A SS_A SSA和 S S e SS_e SSe的比作为检验统计量正符合这一想法.
接下来讲一下方差分解的小技巧: Y i j − Y ˉ = ( Y i ˉ − Y ˉ ) + ( Y j ˉ − Y ˉ ) + ( Y i j − Y i ˉ − Y j ˉ + Y ˉ ) Y_{ij}-\bar{Y}=(\bar{Y_i}-\bar{Y}) + (\bar{Y_j}-\bar{Y})+(Y_{ij}-\bar{Y_i}-\bar{Y_j}+\bar{Y}) Yij−Yˉ=(Yiˉ−Yˉ)+(Yjˉ−Yˉ)+(Yij−Yiˉ−Yjˉ+Yˉ) 两边平方,对 i , j i,j i,j求和,结合约束条件(3.3),注意到
∑ i = 1 k ( Y i ˉ − Y ˉ ) = 0 , ∑ j = 1 l ( Y j ˉ − Y ˉ ) = 0 , \sum_{i=1}^{k}(\bar{Y_{i}}-\bar{Y})=0, \sum_{j=1}^{l}(\bar{Y_{j}}-\bar{Y})=0, i=1∑k(Yiˉ−Yˉ)=0,j=1∑l(Yjˉ−Yˉ)=0,
∑ i = 1 k ( Y i j − Y i ˉ − Y j ˉ + Y ˉ ) = ∑ j = 1 l ( Y i j − Y i ˉ − Y j ˉ + Y ˉ ) = 0 \sum_{i=1}^{k}(Y_{ij}-\bar{Y_i}-\bar{Y_j}+\bar{Y})=\sum_{j=1}^{l}(Y_{ij}-\bar{Y_i}-\bar{Y_j}+\bar{Y})=0 i=1∑k(Yij−Yiˉ−Yjˉ+Yˉ)=j=1∑l(Yij−Yiˉ−Yjˉ+Yˉ)=0
即知所有交叉积之和皆为0,而得到

第一个平方和可以作为因素 A A A的影响的衡量,从前述 Y i ˉ − Y ˉ \bar{Y_{i}}-\bar{Y} Yiˉ−Yˉ作为 a i a_i ai的估计可以理解第二个平方和同理。至于第三个平方和可作为随机误差的影响这一点, 直接看不甚明显。可以从两个角度去理解:在 S S SS SS中去掉 S S A SS_A SSA
和 S S B SS_B SSB后,剩余下的再没有其他系统性因素的影响,故只能作为 S S e SS_e SSe。另外,由模型 ( 3.1 ) (3.1) (3.1)及约束条件 ( 3.3 ) (3.3) (3.3),易知

这里面已经毫无 μ , a i , b j \mu,a_i,b_j μ,ai,bj的影响,而只含随机误差。
得到分解式 ( 3.12 ) (3.12) (3.12)后,我们就可以像单囚素情况那样,写出下面的方差分析表: S S A , S S B SS_A , SS_B SSA,SSB 自由度分别为其水平数减去1,这一点与单因素情况相同.总和自由度为全部观察值数目 k l kl kl减去1.剩下的就是误差平方和自由度: ( k l − 1 ) − ( k − 1 ) − ( l − 1 ) = ( k − 1 ) ( l − 1 ) (kl - 1) - (k - 1) - (l - 1) = (k - 1) (l - 1) (kl−1)−(k−1)−(l−1)=(k−1)(l−1) 表3.1
双因素方差分析表
 有一点要注意:在采纳模型 ( 3.1 ) (3.1) (3.1)时,我们事实上引进了 一 种假定,即两因素 A , B A,B A,B对指标的效应是可以叠加的.换一种方式说:因素 A A A的各水平的优劣比较,与因素 B B B处在哪个水平无关,反之亦然.更一般的情况是: A , B A,B A,B两因子有“交互作用 " 。这时在模型(5.13)中,还要加上表示交互作用的项 c i j c_{ij} cij.这时不仅统计分析复杂化了,尤其是分析结果的解释也复杂化了.本文档暂不讨论这种情况。在一个特定的问题中,交互作用是否需要考虑,在很大程度上取决于问题的实际背景和经验.有时,通过试验数据的分析也可以看出一些问题。例如,若误差方差 σ 2 \sigma^2 σ2的估计 M S e MS_e MSe反常地大,则有可能是由于交互作用所致.因为可以证明:若交互作用确实存在而未加考虑,则它的影响进入随机误差而增大了 M S e MS_e MSe。
有一点要注意:在采纳模型 ( 3.1 ) (3.1) (3.1)时,我们事实上引进了 一 种假定,即两因素 A , B A,B A,B对指标的效应是可以叠加的.换一种方式说:因素 A A A的各水平的优劣比较,与因素 B B B处在哪个水平无关,反之亦然.更一般的情况是: A , B A,B A,B两因子有“交互作用 " 。这时在模型(5.13)中,还要加上表示交互作用的项 c i j c_{ij} cij.这时不仅统计分析复杂化了,尤其是分析结果的解释也复杂化了.本文档暂不讨论这种情况。在一个特定的问题中,交互作用是否需要考虑,在很大程度上取决于问题的实际背景和经验.有时,通过试验数据的分析也可以看出一些问题。例如,若误差方差 σ 2 \sigma^2 σ2的估计 M S e MS_e MSe反常地大,则有可能是由于交互作用所致.因为可以证明:若交互作用确实存在而未加考虑,则它的影响进入随机误差而增大了 M S e MS_e MSe。