我从 200 个机器学习工具中都学习到了什么?
英文:What I learned from looking at 200 machine learning tools
作者:Chip Huyen,计算机科学家,现就职于硅谷的一家人工智能初创公司,专注于机器学习生产流程。
译者:罗昭成
本文已获作者翻译授权。
为了更好的理解现在的机器学习、人工智能的工具,更好的预测他们的前景。我收集了所有我能收集到的,有关人工智能与机器学习的资料。这些资源来源以下几个方面:
- 全栈深度学习
- LF AI 基金会大图
- 人工智能与数据大图
- 媒体列出的众多 AI 初创公司
- 我在 Tweet 和 LinkedIn 中收到的回复
- 其它人(朋友、网友、风投等)与我分享的内容
我从中过滤掉使用机器学习做产品的公司(如,使用机器学习提供数据分析的公司)、不常用的工具或没有人使用的工具。还有 202 个机器学习的工具。这里有完整的列表。如果有你觉得应该包含但我没有列出来的工具,请你告诉我。
免责申明
- 这个列表是我在 2019 年的时候整理的,在过去的 6 个月,市场中可能会有一些变化。
- 有一些科技公司有大量的工具,我并不能一一列举。如 Amazon Web Services 提供了超过 165 种完整的服务。
- 有许多不知名或者已经不存在的公司并没有在此分析的数据之中。
本文包含以下 6 部分内容
- 概述
- 机器学习的发展历史
- 机器学习前途未卜
- 机器学习运维面临的问题
- 开源与开放核心
- 总结
1. 概述
创建一个机器学习的产品,包含以下四个步骤:
- 项目立项
- 数据处理
- 建模与训练
- 提供产品服务
我将我统计出来的机器学习工具,根据这些工具对上面步骤的支持情况,对所有机器学习工具进行分类。当然,这里面不包含项目立项相关的内容,它需要的是项目管理工具,而不是机器学习工具。分类这件事情并没有看起来的那么简单,很多工具都可以帮助你完成多个事情。并且它们模棱两可的解释,也并不能让我们很好理解它的作用,像下面的这些描述:“我们突破了数据科学的极限”,“我们将 AI 项目转变成商业成果”,“像呼吸一样,随意使用你的数据”,还有我最喜欢的一句: “我们驰骋在数据科学中。”
每个工具都有它最擅长的部分,我将包含多种能力的工具分类到它最擅长的那一类中。如果它擅长所有部分,我就将他们放在N 合一这个类别中。当然,分类中还包含基础设施提供商,他们提供训练与存储的基础设施,并且大部分都是云服务提供商。
2. 机器学习的发展历史
首先,我将这些工具发布的时间进行了整理。如果这个工具是一个开源项目,我从该项目的第一次提交开始,查找项目公开的时间;如果是一家公司,我使用它在 Crunchbase 上注册的时间作为工具的发布时间。基于这些数据,我绘制了各类工具每年发布的数量图。
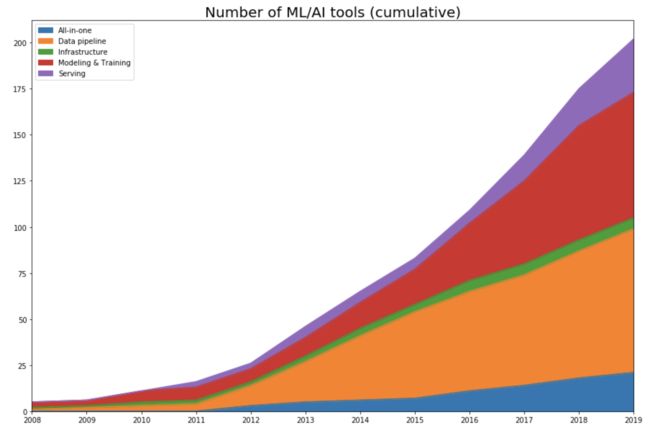
不出所料,数据中可以看到,随着深度学习的发展,在 2012 年开始迎来爆发式的增长。
前卷积神经网络时代(2012 年之前)
直到 2011 年,机器学习主要工作都是在建模和训练模型上,那时的一些框架,到现在还很流行(如:Scikit learn),当然还有一些框架为现在的发展留下了深远的影响。很多机器学习工具开始于 2012 年前,一直持续优化迭代到今天,直到它们 IPO(Cloudera、Datadog、Alteryx)或者被收购,或者成为社区流行的开源项目(Spark、Flink、Kafka)。
高速发展阶段 (2012 - 2015 年)
当机器学习的社区采用“数据驱动”的方法时,机器学习的发展就变成了数据处理的发展。每年在每个类别中工具的发布数量,也清晰的展现出了这一点。在 2015 年,有 57% 数据处理工具。

生产阶段 (2016 年至今)
纯粹的技术研究对机器学习领域来说非常重要,但是大多数公司并没有足够的研究经费支持技术研究,除非对应的技术研究能在短期内应用在真实的商业场景中。随着机器学习的研究与发展,海量的数据与处理模型的增长,使得机器学习越来越触手可得。越来越多的人为他们的应用找到使用机器学习的场景,这也近一步增加了我们对机器学习工具的需求。
在 2016 年,Google 宣布使用神经网络来提高 Google 翻译的准确度,这也是深度学习应用在真实商业场景中的先例之一。从那时起,有很多的机器学习工具被开发出来,帮助我们更好的做人工智能的产品。
3. 机器学习前途未卜
现在有很多人工只能相关的初创公司,它们中大多数都是将机器学习用于它们的产品(如提供业务分析或客户支持等产品),而不是做机器学习工具的初创公司(创建工具来帮助其他人实现产品)。用投资人的话来说,他们大多数都是在人工智能的垂直领域。在 2019 年福布斯排行榜中,50 家人工智能公司,其中只有 7 家是做机器学习工具的公司。
当你去一家公司,告诉他们,使用你的产品可以减少一半客户支持的投入,因此应用类的产品能够更好的售卖、商业化。但是机器学习相关的工具却很难卖出去,但是这些工具对人工智能的影响非常大,因为他们的目标不是做某一个单一的应用程序,而是在做一个生态。许多公司可以提供相似的人工智能产品,但是在创建机器学习产品的流程中,通常很少有工具能够共存。
经过我广泛的搜索调查,我却只能找到大约 200 多个人工智能的工具,与传统软件相比,这点工具是非常微不足道的。如果你想找一个传统 Python 应用程序的测试工具,花两分钟时间,你在 Google 上至少能找到 20 个。但是如果你想找一个测试机器模型的工具,你就很难能够找到了。
4. 机器学习运维面临的问题
很多传统软件开发的工具也可以用于人工智能产品的开发中,但是,人工智能产品中有很多独有的挑战,它们需要特有的工具去处理。
对于传统的软件工程师来说,写代码是最难的一部分。但对于机器学习来说,写代码只是挑战中很小的一部分。开发一个可以在商业中使用的模型非常困难,并且成本很高。大多数公司并不会将重点放在模型的开发上,而是使用现有的模型。
对于机器学习来说,使用更多、更好的数据,能够实现更好效果的应用程序。大多数的公司都将重点放在数据优化上,而不是机器学习算法的优化上。由于数据的快速变化,我们的机器学习应用程序也需要快速的进行发布。在很多机器学习应用的场景中,你需要每天都进行模型更新。
机器学习算法的大小也是一个问题。一个大型的 BERT 模型有 340M 的参数,整个算法大小约为 1.35GB。即使这个模型可以在你用户的设备(如手机)上安装,这个模型在新的样本上进行推理所花费的时间也有可能使得应用程序毫无用处。举个例子:在使用输入法的时候,算出建议字符花费的时间比你手动输入的时间还长,那自动完成的模型就一点用都没有。
Git 使用了一行一行的比较形式,比较两个文本文件的差异,因此他对传统软件程序开发非常友好。然而它并不适用数据集以及模型之间的差异比对。又如 Pandas 能够很好的进行数据处理,但是它不支持在 GPU 上运行。
CVS 等基于行的数据格式,非常适合在数据量小应用程序中使用。但如果你的应用程序有许多功能,并且这些功能只需要使用数据中的一个子集,这种情况下,使用基于行格式的方式仍需要加载所有的数据。PARQUET 和 OCR 等列格式的工具,针对上述的场景进行了相应的优化。
机器学习产品在发布上也面临着很多问题:
- 监控: 如何知道你的数据分布发生了变化,你需要重新训练模型?例如:Dessa,Alex Krizhevsky 基于 AlexNet 开发的,在 2020 年被 Square 收购
- 数据标签:如何快速的给新的数据打标,或将已经存在的数据进行重新打标来支持新的模型训练?例如:Snorkel
- 持续集成、持续交付: 如何保证你的模型在每一次修改后都能够按照预期的进行工作,你不可能花费好几天的时间去等待训练收敛的结果?例如:Argo
- 交付: 如何打包并发布你的新模型?例如:OctoML
- 模型压缩:如何将你的机器学习模型进行压缩,让他能够在客户的设备上运行? 例如:Xnor.ai 这家公司,由艾伦研究所拆分出来,专注模型压缩的初创企业,在 2018 年 5 月,估值 6200 万美元,获得 1460 万美元的融资。在 2020 年 1 月, 苹果以 2 亿美元收购了它,并关闭了它的网站。
- 推理优化: 如何提高你的模型推理速度?多步融合?低精度?减小模型可以使推理速度变得更快。例如:TensorRT
- 边缘设备: 硬件涉及让机器学习算法能够更快速的运行在更廉价的设备上。例如:Coral SOM
- 隐私:如何使用用户的数据进行训练并且保证用户的隐私?如何让你的应用程序满足 GDPR ? 例如:PySyft
我根据这些机器学习工具主要解决的问题绘制了下图:
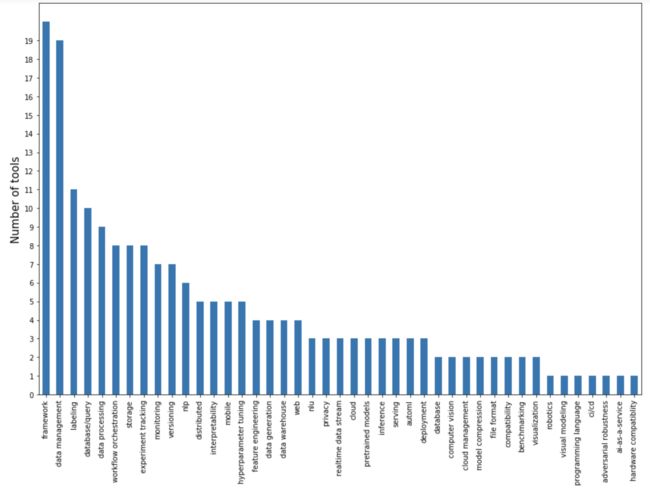
这些工具很大一部分都聚焦在数据处理上:数据管理、标记、数据查询、数据处理、数据生成等。这些数据处理工具旨在构建一个平台,数据处理是项目中资源最密集的阶段。如果有人在你的平台上,给你提供数据,你就能很容易为他们提供预先构建的训练模型。
建模和训练模型主要是框架来实现的。而深度学习框架竞争已经逐渐趋于冷却,现主要是 Pythorch 和 TenserFlow 之间的竞争。以及一些基于这两个框架的更高层次的框架之间的竞争,它们围绕这两个框架来处理特定的任务: NLP 与 NLU 以及多模态问题。这些框架都是分布式训练框架。这还有一个新的框架 JAX,很多讨厌 TenserFlow 的 Google 开发者都使用它。
现在有很多独立的工具用于一些实验跟踪,并且流行的框架中都内置有他们自己的实验跟踪的功能。超参数是一个非常重要的功能,有些人注意到他们也不奇怪,但是他们似乎都没有抓住重点,超参数的瓶颈并不是设置参数,而是高效的计算能力。
另一个没有被解决的重要问题是在部署与服务上,在这一方面缺乏解决方案的原因在于研究人员与运维人员之间缺少沟通。在有能力从事人工智能研究的公司中(通常是大公司),研发团队与运维团队几乎都是分开的,两个团队之前的合作只能通过(产品、项目)经理来实现。而在小公司中,员工能看到全局,但是他们会受到产品需求的限制。只有少数初创公司,这些公司聘请了有经验的运维工程师和有经验的研究人员一起协同办公,成功的解决了这一问题。并且这些初创公司占据了人工智能很大一部分市场。
5. 开源与开放核心
在 202 个工具中,其中有 109 个是开源软件(OSS)。即使有些工具不是开源的,他们大多数也会附带一些开源的工具。
这里有几个开源软件的原因: 一是所有支持开放源代码的人多年来一直都在说的原因,透明、协作、灵活,但这一个原因似乎只是一个道德上的约束。另一个是,客户并不想在看不到源代码的情况下使用新的工具,因为在看不到源代码的情况下,如果这个工具被关闭,他们将不得不重写代码,实现这个功能。
开源并不意味着不盈利,也不意味着免费。开放源代码的维护很费时,并且成本也很高。据说, TenserFlow 团队有接近 1000 人。公司不会在没有商业目标的情况下提供开源软件。如果有更多的人使用他们的开源工具,就会有更多的人了解他们,信任他们的技术,并且会购买他们的专有工具,并且也能让更多的人希望加入他们公司。
Google 通过推广 TenserFlow,希望能够让更多的人使用他们的云服务。NVIDIA 维护 cuDF 库也是希望有更多的人来买他们的 GPU。Databricks 免费提供 MLflow,但出售他们的数据分析平台。Netflix 最近成立了专门的机器学习团队,发布他们自研的 Metaflow 框架,用以吸引人才。自然语言处理工具 SpaCy 是免费的,但是 Prodigy 却是收费的。
开放源代码已经变成了一种行业标准,创业公司很难从中找到一种可行的商业模式。任何一个刚起步的公司,都必须与现有的开源工具进行竞争。如果你也仅仅只开放核心,你需要仔细思考,哪些特性是要包含在开源软件中,而哪些是要放在付费的版本中。既要让用户不觉得你贪婪,也要能够让免费用户付费。
6. 总结
关于人工智能的泡沫是否会破灭,人们也是议论纷纷。现在,人工智能上很大一部分投资都在自动驾驶上,但是到现在仍然没有一款完全自主驾驶的汽车出现。一些人认为投资者将会对人工智能失去希望, Google 也冻结了在机器学习上的人员招聘, Uber 解雇了一半的人工智能研究团队。有传闻说,学习机器学习相关的人员远多于机器学习相关的工作岗位。
现在是进入人工智能领域的好时机吗?我相信,现在是有在炒作人工智能的概念,但在某一个时刻,会冷静下来。有可能这个时间点已经发生了。我不相信机器学习会消失,有能力进行机器学习研究的公司会越来越少,但是绝不会缺乏将机器学习现有的工具引入产品的公司。
如果必须在人工智能专家和工程师之间做一个选择,那么请选择工程师。对于工程师来说,学习人工智能相关知识会很容易,但是对于人工智能专家来说,成为一个很好的工程师要困难得多。如果你是一个优秀的工程师,并且能够为构建人工智能工具而努力,我会由衷地感谢你。
致谢:感谢 Andrey Kurenkov 在我撰写本文时所做出的指导。感谢 Luke Metz 的审校。