随机森林原理详解 random forest 代码+参数讲解
事实上随机森林的基本单元决策树很早就被提出来了,只不过单个决策树效果不好。这个情况和神经网络差不多。
到了2001年Breiman把分类树组合成随机森林(Breiman 2001a),即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。在运算没有增加的情况下,精度提高了不少。
进入正题
随机森林由两个部分组成
随机 和 森林
森林简单来说就是很多颗树,而这个树就是决策树。
所以现在的问题可以有以下三个:什么叫决策树,树树之间怎么组成森林,又怎么个随机法?
现在先来回答第一个问题:
决策树,简单来说就是用来决策的树状结构。
emmm像这样的:
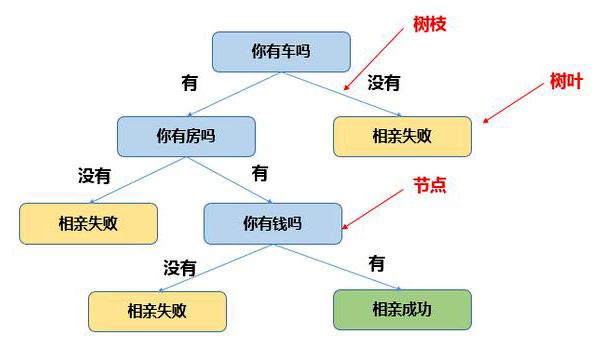
用更专业(装逼)的话来说就是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二。
第二个问题:树树之间怎么组成森林?
森林四步走,精度九十九
第一步:设有N个样本,有放回地随机选择n个样本。
第二步:设每个样本有M个属性,在每个决策树进行分裂时,随机抽样m个属性,m远小于M。然后运用某种评价指标评价每个属性,选择最佳属性作为分裂属性。
第三步:对于每个节点而言都要按照第二步来走,一直到评价指标遍历所有抽样出来的属性都无法得到改进为止。每棵树都尽可能生长没有剪枝。
第四步:重复前面三个步骤就变成了随机森林。
最后的结果会像这样:
那么接下来这个森林怎么用呢?就是说怎么用来预测呢?
我们都知道每棵树都会给出一个结果,那么怎么将这些结果变成一个结果?
总体来说有四个方法:
bagging:通俗而言就是盲人摸象,对大象的总体每次有放回地抽样给盲人摸,而没有放回的就叫pasting
boosting:通俗而言接力赛,不断学习上一个人的经验,最后汇总结果。最常见的应用是自适应提升(adaboost)和梯度提升(gradient
boosting)。stacking:这个就比较复杂,没有什么形象的说法。简单来说就是对每个基础学习模型,都进行一次将训练集分成五份取四份作为模型输入然后输出预测,同时对测试进行预测。将五份预测的测试集取平均作为新的测试集。将模型的五个训练集输出合并为一个新特征作为模型的新训练集。那么再用元模型对新训练集训练,用训练好的模型对测试集输出预测。
voting:顾名思义就是投票,对分类问题来说,投票还有软投票和硬投票,硬投票指的是少数服从多数;软投票指的是对各分类的概率取平均,概率最高的分类为输出分类。
在随机森林中使用的就是bagging,从第一步的描述就可以看出来。
现在还有一个问题就是上面提到的评价指标是什么东西?
常见的指标有
ID3用的是信息增益,C4.5用的是信息增益率,而CART用的是Gini系数
ID3算法十分简单,核心是根据“最大信息熵增益”原则选择划分当前数据集的最好特征。熵由是什么东西呢?熵就是消灭不确定性所需要的信息量。什么叫信息量呢?信息量的概率是这样的,发生概率越小的事件所包含的信息越多。数学公式
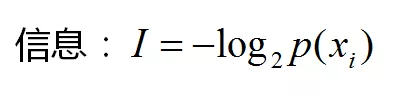
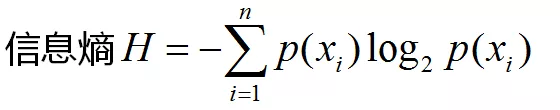
信息增益就是,分裂前后信息熵的增加。
C4.5是Ross Quinlan在1993年在ID3的基础上改进而提出的。.ID3采用的信息增益度量存在一个缺点,它一般会优先选择有较多属性值的Feature,因为属性值多的Feature会有相对较大的信息增益?(信息增益反映的给定一个条件以后不确定性减少的程度,必然是分得越细的数据集确定性更高,也就是条件熵越小,信息增益越大).为了避免这个不足C4.5中是用信息增益比率(gain ratio)来作为选择分支的准则。信息增益比率通过引入一个被称作分裂信息(Split information)的项来惩罚取值较多的Feature。除此之外,C4.5还弥补了ID3中不能处理特征属性值连续的问题。但是,对连续属性值需要扫描排序,会使C4.5性能下降
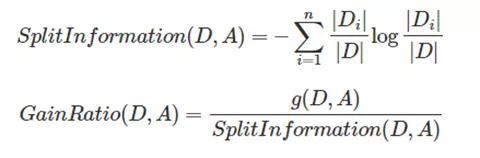
Di/D为第i个分类的出现频率
CART(Classification and Regression tree)分类回归树由L.Breiman,J.Friedman,R.Olshen和C.Stone于1984年提出。ID3中根据属性值分割数据,之后该特征不会再起作用,这种快速切割的方式会影响算法的准确率。CART是一棵二叉树,采用二元切分法,每次把数据切成两份,分别进入左子树、右子树。而且每个非叶子节点都有两个孩子,所以CART的叶子节点比非叶子多1。相比ID3和C4.5,CART应用要多一些,既可以用于分类也可以用于回归。CART分类时,使用基尼指数(Gini)来选择最好的数据分割的特征,gini描述的是纯度,与信息熵的含义相似。CART中每一次迭代都会降低GINI系数。下图显示信息熵增益的一半,Gini指数,分类误差率三种评价指标非常接近。回归时使用均方差作为loss function。基尼系数的计算与信息熵增益的方式非常类似,公式如下

ps.其实学过经济学的都应该知道基尼系数,就是描述不平等现象的一个指标。其中通常认为上世纪70年以来的科技浪潮加速了收入不平等现象。可以预见人工智能这个浪潮。。。不说了咳咳。。
现在让我们从新看一下那四步,我们会发现多了一个叫剪枝的东西。
剪枝是为了解决决策树容易过拟合而发展过来的技术。俗称怕他长歪了。
剪枝分为两种:前剪枝和后剪枝
前剪枝:
树到达一定高度
节点下包含的样本点小雨一定数目
信息增益小雨一定的阈值
节点下所有样本都属于同一个类别
后剪枝:
降低错误剪枝 REP(Reduced Error Pruning)
悲观错误剪枝 PEP(Pessimistic Error Pruning)
基于错误剪枝 EBP(Error Based Pruning)
代价-复杂度剪枝 CCP(Cost Complexity Pruning)
最小错误剪枝 MEP(Minimum Error Pruning)
拿 CCP 举例,CART用的就是CCP剪枝,其余的剪枝方法可以网上google一下. CCP剪枝类实际上就是我们之前讲到的最小化结构风险,对决策树,结构风险定义为:
其中: C(T)为模型对训练数据的误差.对分类树,可以采用熵,基尼指数等等.对回归树,可以采用平方误差,∣T∣ 为树的叶子节点个数,
α为两者的平衡系数。
当然随机森林是没有剪枝的!!为什么呢我个人认为随机森林事实已经存在前剪枝了,因为决策树并不能遍历样本所有特征,等于限制了决策树的复杂度。
简单总结一下:
优点:
1.快,非常快,由于每棵树都是独立的,意味着可以同时训练,加快速度。
2.不用处理缺失值,同时也不用对高维数据降维
3.能够输出特征重要性
4.精度也不错,不容易过拟合
缺点:
1.精度高,但是现在已经不够高
2.噪音过大的情况,可能会过拟合
如果说现在随机森林还有(在数据竞赛里面)用的话,主要用于
1.特征选择
2.预测缺失值
如果有人知道随机森林在实际业务场景还有用处的话,可以告知一下我。
随机森林要讲的东西说得差不多了,下面用sklearn来实现一下:
from sklearn.ensemble import RandomForestClassifier
X_train,X_test=[[0,1],[1,0]],[1,1]
y_train=[1,0]
rf=RandomForestClassifier(random_state=021)
rf.fit(X_train,y_train)
results = rf.predict(X_test)
#或者我们可以输出起预测概率
results_proba = rf.predict_proba(X_test)
#因为我们可以通过软投票的方法来再组成一个强学习器
下面介绍一下参数:
n_estimators: 森林里面决策树的数量,一般用来降低偏差
criterion: 就上面我们介绍的评价指标,默认是gini系数
max_depth:树的深度,一般用来降偏差
min_samples_split:前剪枝的一种,节点最小样本数,默认为2,防止过拟合
min_samples_leaf:叶节点最小样本数,默认为1,同样是前剪枝,防止过拟合
max_features:
每次bagging时的最大特征数,默认为auto,即最大特征数的开方。其他可以选的有,绝对特征数(如果输入为整数),百分比特征数(如果输入为0-1),对数特征数(log2),不抽样(None)。max_leaf_nodes:最大叶节点数,默认为None,防止过拟合
min_impurity_descrease: 不纯度阈值,默认为0,防止过拟合
booststrap:是否有放回,默认为Ture,实际上如果选择False那么就会变成pasting
oob_score:袋外分数,事实上每次对有放回抽样,那么肯定存在一些样本没有被抽到,那么没有被抽到的样本称为袋外样本,用训练好的模型预测袋外样本所得到的分数即为out
of bag score。默认为Falsen_jobs:即多少个进程来训练和预测,默认为None,应该调为-1,即不限制。
random_state:随机种子,一般用来复现分数,可以随便选一个,我选了我的学号hhh
verbose: 就是每隔多少输出一次信息,默认为0,一般设为100
warm_start: 是否热启动,即使用上次的模型进行训练,默认否
class_weight:
是否对分类进行加权,如果是不平衡样本的话需要进行操作否则不需要。因为所以存在某一个类特别多的话,那么抽样出来的样本全部都是那个类别,模型也只能学习到那个类别,从而泛华能力不强。如果不平衡样本可以选择balanced,或者自己传入一个字典。
随机森林再最随机一点就是Extremely Randomized Trees极端随机森林
对于随机森林,进行了行列随机。而进一步,ERT对于特征的分裂点也进行了随机。可谓真~随机森林,与随机森林比偏差增大,方差减少。
讲完上面的bagging+决策树
下面就可以讲一下boosting+决策树
其中
自适应boosting+决策树=adaboost
梯度boosting+决策树=GBDT
会重点讲GBDT,因为顺着GBDT会衍生出niubility的Xgboost和lightGBM。
一些细节:
会有样本在随机抽样时,没有被抽到吗?会的话,会有多少?
当然是有的,考虑有N个样本,抽取M次后,求某个样本没有被抽到的概率。
(1 - 1/N)^M
那么N、M趋于无穷大时,等于1/e约等于0.368,也就是说至少有36.8%的样本是没有被看过的。
那么对于特征也同理,但是现实中特征的维度通常是有限的。所以M趋于无限大时,不被抽到的概率会趋于零。
而我之前错误的理解认为,特征抽取是一次性的,后来看视频才发现也是一次一次抽的。每抽取一个样本,再随机抽取其中一些特征进行训练。
所以对于随机森林模型,一定要对大样本进行大的森林训练,否则可能会学习不完整。