text_cnn:文本分类实战(一)数据处理部分
文章目录
- 原理介绍
- 实战
原理介绍
这里就简单介绍几句原理,因为讲的细的blog超级多。(一共三个模块,这篇只是数据处理模块)
传统的CNN用来处理图像数据,通过卷积提取特征,方便处理。文本和图像的区别在于文本的特征相对较少,所以可以采用一维卷积进行特征提取。
步骤如下:
(一)文本拉伸成一个图片(矩阵):词嵌入,可以采用w2v
(二)卷积层:对矩阵进行卷积
(三)池化层:Max Pooling 使卷积后的特征数据变成一列(行)数据
(四)全连接,softmax
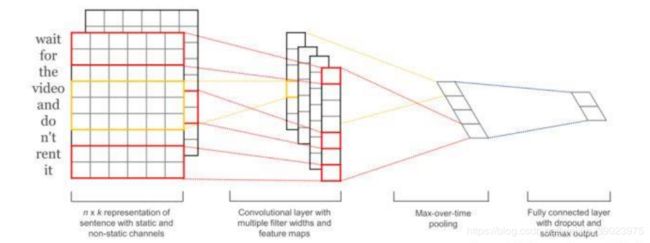
上图懂了,原理也差不多了,以经典的新闻分类为例,讲一下实战需要注意的的地方。
实战
工业上区别于学术,需要对数据进行预处理,是一个很大的工作量。(坑很多,谁处理谁知道)
数据处理模块data_process.py
先梳理一下整体数据处理流程:因为个人原因,习惯于pandas进行数据的存储和使用,所以我将原始的文本格式转换成xls(或者csv)形式,这样一行代码即可读进来数据。
df = pd.read_excel('data/train.xls')
// 如果不想要标签 header=None,index=None 建议保存
然后我们就可以取出x和y
train.xls预览如下图

x = df['text'] // 其中的标签,文本
y = df['class'] // 类别
当然这只是将数据读进来,还没有进行什么处理。我们希望将数据变成图片(矩阵)格式,那么我们要将读进来的文本先分词,我比较喜欢取出停用词,所以我们接下来要定义两个方法完成上述操作。
x = df['text']
y = df['class']
// 在这个基础上 我其实不太会用这个blog工具进行编辑,python是#是注释
// 方法1:拿到停用词列表(从本地)
def getstopword(stopwordpath):
stoplist = set()
for line in stopwordpath:
stoplist.add(line.strip())
return stoplist
// 方法2: 分词并去除停用词
def cutstopword(x,stoplist): // 这个x是一句话,不是这一列所有话!!! 如果还不懂,看下面如何使用该方法或者留言
seg_list = jieba.cut(x) // jieba简单 也可以使用hanlp 或者 stan
res = []
for item in seg_list:
if item not in stoplist and re.match(r'-?\d+\.?\d*', item) == None and len(item.strip()) > 0:
res.append(item)
return res
// 当定义完两个方法时,可以配合pandas进行数据处理:如下
df['word_list']=df['text].apply(cutstopword,args=(stoplist,)) // 创建新列存储处理后的数据!不是在此处用,仅举例
分词与停用词去除结束之后,因为要使用词嵌入,所以需要训练一个word2vec模型,这里采用了gensim框架来训练。代码框架如下
from gensim.models import Word2Vec
def train_w2v(x,n_dim) # x是数据,这个x是全部n_dim是词嵌入维度
imdb_w2v = Word2Vec(size=n_dim,min_count=5,seed=1)
imdb_w2v.bulid_voab(x)
# 训练模型
imdb_w2v.train(x,total_examples=imdb_w2v.corpus_count,epochs=30)
imdb_w2v.save('model/w2v_model.pkl')
return imdb_w2v # 存储是一个好习惯,不然浪费大量时间
#接下来就是包装一下
#其实这个方法需要注意,如果想要重新训练,比如调整嵌入维度等,要删除路径下的模型
def load_w2v(x,n_dim,path):
if os.path.exists(path):
imdb_w2v = Word2Vec.load(path)
else:
imdb_w2v = train_w2v(x,n_dim=n_dim)
return w2v_model
#总结:有取、没有训练
有了w2v模型之后,可以将数据转化。由于使用的是CNN,那么要求图片大小一致,也就是我们的矩形数据大小一致,所以不能直接那么转换了之后再堆成矩阵。 这里面有两种方式,其实都可以。方式一:wordlist先padding,长的剪短,短的补齐,之后再转化 。方式二:转化的过程中在补齐。
这里面有点说道,坑来了:如果数据集很大,现在将数据集转换成[None,padding_size,n_dim]大小的数据时,会出现memory error,如果我拼错了也不要介意,反正是由于内存报错了。所以在我出错之后,想着怎么解决一下,后来在写到batch时候,想通了,其实可以再取了batch之后,以每一个batch为单位转化,这样不会给内存造成太大压力。我之前的数据转换后是[50000,600,300],所以内存有压力时候,可以选择减小padding_size和n_dim
所以很重要的,不要先直接使用word2vec将分词后文本全部转化!!
不先转换但是方法可以写出来,留作batch时用
def tran_vecs(imdb_w2v,x,n_dim,padding_size=300):
batch_text = []
for text in x:
matrix = []
for i in range(padding_size):
try:
vec = imdb_w2v[text[i]]
matrix.append(vec)
except:
matrix.append([0]*n_dim)
batch_text.append(matrix)
return np.array(batch_text)
在对x,也就是文本处理完之后,我们还要对y(标签)进行处理,方式比较简单,一共需要两步,也就是定义两个方法。
# 我们现在的标签其实是文本,
# 第一步转换成数字
def cate_to_id():
categories = {'体育':0, '财经':9, '房产':3, '家居':2, '教育':4, '科技':8, '时尚':5, '时政':6, '游戏':7, '娱乐':1}
id = -1
if word in categories:
id = categories.get(word)
return id
# 第二步 one-hot
def one_hot():
return tf.ont_hot(y,num_classes) #也可以用keras 或者 自定义一个 反正一直都可以用
其实到这里,数据的处理差不多结束了,因为我选择的是用词去作为基本粒度,所以选择了w2v,也可以采用字作为基本粒度,再进行词嵌入。两种都可以,想尝试的可以试一下。只要list[text] 就可以变成字的粒度,不需要jieba.cut了。
然后还要自己写一个对外的接口啊 和 batch迭代的方法。
ok,数据处理部分就这么多,也借鉴了别人的方式吧,应该没侵权,都是自己手打的,完整代码打包会在最后一个模块给出,期间有些坑自己走过去才知道数据处理部分坑很多,下次也能更好地完成文本数据的处理,如果有问题或指教欢迎评论,谢谢。