使用简单的多线程爬取豆瓣流浪地球全部影评
首先导入相关库,获取一条影评,从简单入手,理清思绪。
- 第一页的地址为:https://movie.douban.com/subject/26266893/reviews?sort=time&start=0
- 添加请求头,get地址获取数据,记得utf-8编码或者获取对象的text
url = 'https://movie.douban.com/subject/26266893/reviews?sort=time&start=100'
header = {
'Cookie': 'bid=lLZNvSc0MPY; douban-fav-remind=1; __utmz=30149280.1575010669.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ll="118218"; __utmz=223695111.1575179654.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=yKYkxSPwLDqAfambC2V6Dw91mFGwzufT; __utmc=30149280; __utmc=223695111; _pk_ses.100001.4cf6=*; __utma=30149280.1105343936.1574835189.1575353617.1575360430.7; __utma=223695111.1613809916.1575179654.1575353617.1575360431.4; __utmb=223695111.0.10.1575360431; push_doumail_num=0; push_noty_num=0; __utmt=1; __utmv=30149280.20754; ap_v=0,6.0; douban-profile-remind=1; dbcl2="207548288:U+/c0tS58L0"; ck=HC6F; __utmb=30149280.6.10.1575360430; _vwo_uuid_v2=D4DE996F03E12664A05752ABC9C201239|f10372f5df1d7749be57dba51704c1ce; __gads=Test; _pk_id.100001.4cf6=50f5ed34d7c7b05f.1575179654.4.1575361223.1575354265.',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
Response = re_data.text
re_data = requests.get(url,headers=header)
3.匹配出第一条评论的跳转url,与评价等级,评价时间
selector = etree.HTML(Response)
dis_url = selector.xpath("//div[@class='main-bd']/h2/a/@href")[0]
start = selector1.xpath("//header/span[1]/@title")[0]
data_time = selector1.xpath("//header/span[2]/text()")[0]
本来想get跳转url然后匹配出数据,但是点展开后发现会有一个动态请求,且每个评论的动态文件都是full
所以直接拼接url地址,获取动态json数据
d_url = dis_url+'full'
但这里发现去get的话打印出来的是Response<404>,请求头没问题,那么url有问题,果然仔细看的话动态请求的数据url还多了个’j’ 真的是天坑…'
4.拼接完整的url地址,把数据转换成列表插入字符,在转换成字符串
list_url = list(d_url)
list_url.insert(25,'j')
list_url.insert(26,'/')
str_url = ''.join(list_url)
5.get url 匹配json数据
hearder2 = {
'Referer':'https://movie.douban.com/subject/26266893/reviews?sort=hotest',
'Cookie':'bid=lLZNvSc0MPY; douban-fav-remind=1; __utmz=30149280.1575010669.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ll="118218"; __utmz=223695111.1575179654.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=yKYkxSPwLDqAfambC2V6Dw91mFGwzufT; __utmc=30149280; __utmc=223695111; push_doumail_num=0; push_noty_num=0; __utmv=30149280.20754; douban-profile-remind=1; dbcl2="207548288:U+/c0tS58L0"; ck=HC6F; _vwo_uuid_v2=D4DE996F03E12664A05752ABC9C201239|f10372f5df1d7749be57dba51704c1ce; __gads=Test; ap_v=0,6.0; _pk_id.100001.4cf6=50f5ed34d7c7b05f.1575179654.7.1575379311.1575372983.; _pk_ses.100001.4cf6=*; __utma=30149280.1105343936.1574835189.1575372985.1575379311.10; __utmb=30149280.0.10.1575379311; __utma=223695111.1613809916.1575179654.1575372985.1575379311.7; __utmb=223695111.0.10.1575379311',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36X-Requested-With: XMLHttpRequest'
}
com = requests.get(str_url,headers=hearder2)
json_data = com.json()
selector = etree.HTML(json_data['body'])
#作者
author = selector.xpath('//*[@id="link-report"]/div[1]/@data-author')
#内容
content = selector.xpath('//*[@id="link-report"]/div[1]/p/text()')
现在所有字段已经匹配出来了,大概思路也知道,准备循环获取完整个页面数据,在跳转到下一个页面循环获取数据,直到没有
定义一个函数多线程操作
1用浏览器浏览影评点击下一页可以发现url地址由https://movie.douban.com/subject/26266893/reviews?sort=time&start=0
变为了https://movie.douban.com/subject/26266893/reviews?sort=time&start=20,
就可以定一个for循环,循环地址
import requests,parsel,json
from threading import Thread
from lxml import etree
import pymongo
cli = pymongo.MongoClient('localhost',27017) #连接mongodb
def craw_one(start_num,end_num,length_num):
for i in range(start_num,end_num,length_num):
url = 'https://movie.douban.com/subject/26266893/reviews?sort=hotest&star=%s'%i
header1 = {
'Cookie': 'bid=lLZNvSc0MPY; douban-fav-remind=1; __utmz=30149280.1575010669.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ll="118218"; __utmz=223695111.1575179654.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=yKYkxSPwLDqAfambC2V6Dw91mFGwzufT; __utmc=30149280; __utmc=223695111; push_doumail_num=0; push_noty_num=0; __utmv=30149280.20754; douban-profile-remind=1; dbcl2="207548288:U+/c0tS58L0"; ck=HC6F; _vwo_uuid_v2=D4DE996F03E12664A05752ABC9C201239|f10372f5df1d7749be57dba51704c1ce; __gads=Test; ap_v=0,6.0; _pk_id.100001.4cf6=50f5ed34d7c7b05f.1575179654.7.1575379311.1575372983.; _pk_ses.100001.4cf6=*; __utma=30149280.1105343936.1574835189.1575372985.1575379311.10; __utmb=30149280.0.10.1575379311; __utma=223695111.1613809916.1575179654.1575372985.1575379311.7; __utmb=223695111.0.10.1575379311',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
}
re_data = requests.get(url,headers=header1)
s_selector = etree.HTML(re_data.text)
full_start =s_selector.xpath("//header/span[1]/@title")
full_data_time =s_selector.xpath("//header/span[2]/text()")
if not full_start:
return
for j in range(len(full_start)):
start1 = full_start[j]
data_time1 = full_data_time[j]
full_url = s_selector.xpath("//div[@class='main-bd']/h2/a/@href")[j]
d_url = full_url+'full'
list_url = list(d_url)
list_url.insert(25,'j')
list_url.insert(26,'/')
str_url = ''.join(list_url)
hearder2 = {
'Referer':'https://movie.douban.com/subject/26266893/reviews?sort=hotest',
'Cookie':'bid=lLZNvSc0MPY; douban-fav-remind=1; __utmz=30149280.1575010669.3.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; ll="118218"; __utmz=223695111.1575179654.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __yadk_uid=yKYkxSPwLDqAfambC2V6Dw91mFGwzufT; __utmc=30149280; __utmc=223695111; push_doumail_num=0; push_noty_num=0; __utmv=30149280.20754; douban-profile-remind=1; dbcl2="207548288:U+/c0tS58L0"; ck=HC6F; _vwo_uuid_v2=D4DE996F03E12664A05752ABC9C201239|f10372f5df1d7749be57dba51704c1ce; __gads=Test; ap_v=0,6.0; _pk_id.100001.4cf6=50f5ed34d7c7b05f.1575179654.7.1575379311.1575372983.; _pk_ses.100001.4cf6=*; __utma=30149280.1105343936.1574835189.1575372985.1575379311.10; __utmb=30149280.0.10.1575379311; __utma=223695111.1613809916.1575179654.1575372985.1575379311.7; __utmb=223695111.0.10.1575379311',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36X-Requested-With: XMLHttpRequest'
}
com = requests.get(str_url,headers = hearder2)
json_data = com.json()
selector = etree.HTML(json_data['body'])
#作者
author1 = selector.xpath('//*[@id="link-report"]/div[1]/@data-author')
#内容
content1 = selector.xpath('//*[@id="link-report"]/div[1]/p/text()')
db = cli['mydb']
my_col = db["my_col"]
data = {"作者":author1,"内容":content1,"评价等级":start1,"评价时间":data_time1}
print(data)
my_col.insert_one(data)
if __name__ == '__main__':
craw1= Thread(target=craw_one,args=(0,21440,40))
craw2 = Thread(target=craw_one,args=(20,21440,40))
craw1.setDaemon(True)
craw2.setDaemon(True)
craw1.start()
craw2.start()
craw1.join()
craw2.join()
print('执行完成')
线程不知道有没有用,没有比较,数据太大,应该学习协程了…
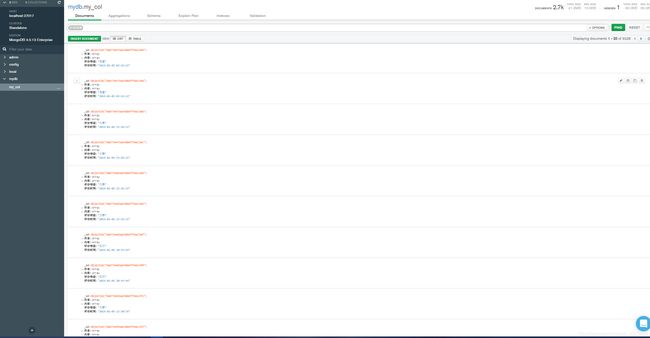
效果如图: