kaggle房价预测(TOP10%)
房价预测
- 一、数据背景
- 1. 数据来源
- 2. 分析目的
- 3. 分析思路
- 二、理解数据
- 1. 导入数据集
- 2. 查看数据集
- 3. 删除离群值
- 三、数据预处理
- 1. 合并数据集
- 2. 处理缺失值
- 2.1 字符类型缺失值填充
- 2.2 数值类型缺失值填充
- 3. 目标变量及特征变量纠偏
- 3.1 目标变量纠偏
- 3.2 特征变量纠偏
- 4. 构建新的特征
- 5. 对特征编码
- 四、模型预测
- 1. 环境配置
- 2. 拆分训练集与测试集
- 3. 构建模型
- 3.1最大投票法
- 3.1加权平均法
- 6. 结果保存
一、数据背景
1. 数据来源
此数据集来源于kaggle房屋价格预测数据集,用于回归预测。其目的是根据提供的特征变量预测房屋最终的销售价格,评判标准为均方根误差RMSE。
2. 分析目的
根据提供的特征变量预测目标变量SalePrice的取值。(房屋最终的销售价格)
3. 分析思路

二、理解数据
1. 导入数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#导入训练集
train=pd.read_csv('train.csv')
#导入测试集
test=pd.read_csv('test.csv')
train.shape,test.shape
#out:((1460, 81), (1459, 80))
可以看出,训练集有1460条记录,测试集有1459条记录,训练集和测试集各占50%,共有80个特征。
2. 查看数据集
#设置显示所有的列名称
pd.set_option('display.max_columns',None)
train.head()

train.info()
test.info()
display(train.describe())
display(test.describe())

通过info和describe可以看出数据的第一列是ID,最后一列是SalePrice,且数据存在着大量的缺失值。
用corr查看各特征之间的相关性,再用heatmap(热力图)可视化
corrmat=train.corr()
figure,ax=plt.subplots(figsize=(12,8))
sns.heatmap(corrmat,square=True,vmax=.8) #square=True正方形显示
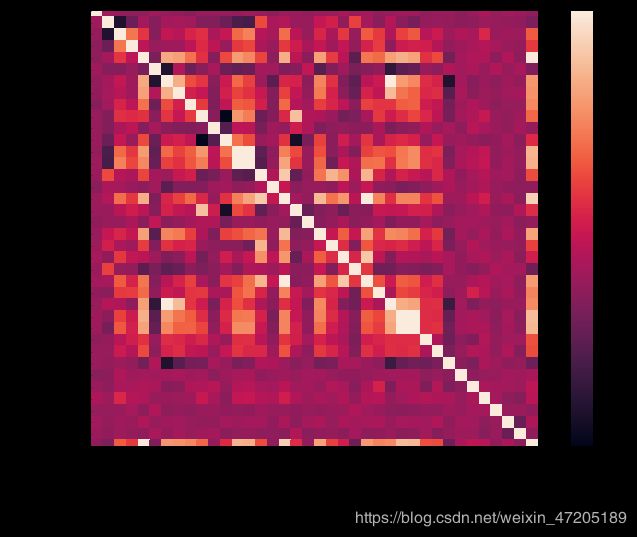
可以看出和特征GarageArea和GarageCars,以及特征TotalBsmtSF和1stFlrSF之间相关度较高,要注意多重共线性的问题。OverallQual、GrLivArea与SalePrice有较强的相关关系,继续筛选出与SalePrice相关性最高的前10个特征。
cols=corrmat.nlargest(10,'SalePrice')['SalePrice']
cols
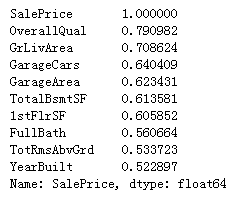
OverallQual、YearBuilt、TotalBsmtSF、 GrLivArea四个变量对房价有重要意义,那么根据这四个变量和目标值之间的关系绘制散点图检查异常值点。
figure,ax=plt.subplots(2,2,figsize=(16,12))
sns.scatterplot(x=train['OverallQual'],y=train['SalePrice'],ax=ax[0,0])
sns.scatterplot(x=train['YearBuilt'],y=train['SalePrice'],ax=ax[0,1])
sns.scatterplot(x=train['TotalBsmtSF'],y=train['SalePrice'],ax=ax[1,0])
sns.scatterplot(x=train['GrLivArea'],y=train['SalePrice'],ax=ax[1,1])

3. 删除离群值
- 对于GrLivArea与SalePrice的关系图,有两个离群的 GrLivArea 值很高的数据,我们可以推测出现这种情况的原因。或许他们代表了农业地区,也就解释了低价。 这两个点很明显不能代表典型样例,所以我们将它们定义为异常值并删除。
- 同理,对于OverallQual、YearBuilt、TotalBsmtSF也存在一些不合理的离群点,在这里考虑将其删除。
#删除离群点
train.drop(train[(train['OverallQual']<5) & (train['SalePrice']>200000)].index,inplace=True)
train.drop(train[(train['YearBuilt']<1900) & (train['SalePrice']>400000)].index,inplace=True)
train.drop(train[(train['YearBuilt']>1980) & (train['SalePrice']>700000)].index,inplace=True)
train.drop(train[(train['TotalBsmtSF']>6000) & (train['SalePrice']<200000)].index,inplace=True)
train.drop(train[(train['GrLivArea']>4000) & (train['SalePrice']<200000)].index,inplace=True)
train.reset_index(drop=True,inplace=True)
三、数据预处理
#ID没用,将其删除
train.drop('Id',inplace=True,axis=1)
test.drop('Id',inplace=True,axis=1)
1. 合并数据集
将训练集和测试集合并为一个数据集,这样可以同时对训练集和测试集数据进行数据清洗和特征工程。
#合并训练集和测试集数据,同时处理数据
feature_train=train.drop('SalePrice',axis=1)
feature_test=test
feature=pd.concat([feature_train,feature_test])
feature.reset_index(drop=True,inplace=True)
2. 处理缺失值
- 对于缺失值较多的特征,尽量不删除,以免漏掉不必要的信息
- 填充均值、众值都会在一定程度上给数据集产生不必要的噪音,有些缺失值可以在数据集中寻找规律
- 对于字符串缺失值使用None填充,数值型填充0。
2.1 字符类型缺失值填充
#特征的类型错误,将数值类型改为字符串类型
feature['MSSubClass']=feature['MSSubClass'].astype(str)
feature['MoSold']=feature['MoSold'].astype(str)
feature['YrSold']=feature['YrSold'].astype(str)
下面对缺失值进行填充:
- 查看官方文档说明对特征的解释后,依次对以下特征填充(在多数情况下的值)。
from sklearn.impute import SimpleImputer
feature['Functional']=SimpleImputer(strategy='constant',fill_value='Typ').fit_transform(feature['Functional'].values.reshape(-1,1))
feature['Electrical']=SimpleImputer(strategy='constant',fill_value='SBrkr').fit_transform(feature['Electrical'].values.reshape(-1,1))
feature['KitchenQual']=SimpleImputer(strategy='constant',fill_value='TA').fit_transform(feature['KitchenQual'].values.reshape(-1,1))
- 用众值填充字符串
feature['Exterior1st']=SimpleImputer(strategy='most_frequent').fit_transform(feature['Exterior1st'].values.reshape(-1,1))
feature['Exterior2nd']=SimpleImputer(strategy='most_frequent').fit_transform(feature['Exterior2nd'].values.reshape(-1,1))
feature['SaleType']=SimpleImputer(strategy='most_frequent').fit_transform(feature['SaleType'].values.reshape(-1,1))
feature['MSZoning'] = feature.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
- 用None填充字符串
for i in feature.columns:
if feature[i].dtype==object:
feature[i]=SimpleImputer(strategy='constant',fill_value='None').fit_transform(feature[i].values.reshape(-1,1))
2.2 数值类型缺失值填充
- 同一街道往往有相同的街区面积属性,LotFrontage属性的缺失值填充
feature['LotFrontage']=feature.groupby('Neighborhood')['LotFrontage'].transform(lambda x:x.fillna(x.median()))
- 用0填充缺失值
numeric_columns=['int16','int32','int64','float16','float32','float64']
numeric=[]
for i in feature.columns:
if feature[i].dtype in numeric_columns:
numeric.append(i)
feature.update(feature[numeric].fillna(0))
3. 目标变量及特征变量纠偏
偏度(Skewness)
用来描述数据分布的对称性,正态分布的偏度为0。计算数据样本的偏度,当偏度<0时,称为负偏,数据出现左侧长尾;当偏度>0时,称为正偏,数据出现右侧长尾;当偏度为0时,表示数据相对均匀的分布在平均值两侧,不一定是绝对的对称分布,此时要与正态分布偏度为0的情况进行区分。当偏度绝对值过大时,长尾的一侧出现极端值的可能性较高。
- 对于右偏数据,可以使用ln(x)进行平滑处理
- 对于左偏数据,可以使用x的平方进行平滑处理
- boxcox可以自动帮我们选择最佳的函数变换方法
3.1 目标变量纠偏
sns.distplot(train['SalePrice'],bins=40,color='blue' )
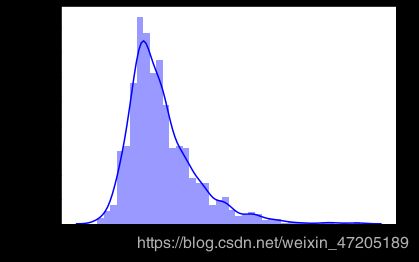
SalePrice不满足正态分布,使用log1p变换
train['SalePrice']=np.log1p(train['SalePrice'])
sns.distplot(train['SalePrice'],bins=40,color='blue')
y=train['SalePrice']
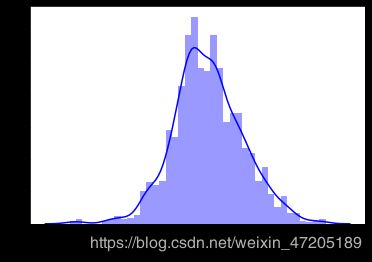
3.2 特征变量纠偏
#计算各数值型特征变量的偏度
from scipy.stats import skew
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
skew_feature=feature[numeric].apply(lambda x: skew(x)).sort_values(ascending=False)
skew_feature

将阈值设为0.5,对特征变量使用boxcox1p变换
#进行boxcox1p转化
skew_feature_index=skew_feature[skew_feature>0.5].index
for i in skew_feature_index:
feature[i]=boxcox1p(feature[i],boxcox_normmax(feature[i]+1))
4. 构建新的特征
#增加每个房屋的地下室,一楼和二楼的总面积特征
feature['TotalSF']=feature['TotalBsmtSF'] + feature['1stFlrSF'] + feature['2ndFlrSF']
# 新增房屋改造时间与房屋出售时间间隔
feature['YearsSinceRemodel'] = feature['YrSold'].astype(int) - feature['YearRemodAdd'].astype(int)
# 房间的整体质量
feature['Total_Home_Quality'] = feature['OverallQual'].astype(int) + feature['OverallCond'].astype(int)
# 开放式门廊、围廊、三季门廊、屏风玄关总面积
feature["PorchArea"] = feature["OpenPorchSF"]+feature["EnclosedPorch"]+ feature["3SsnPorch"]+feature["ScreenPorch"] +feature['WoodDeckSF']
feature['Total_Bathrooms'] = (feature['FullBath'] + (0.5 * feature['HalfBath']) +
feature['BsmtFullBath'] + (0.5 * feature['BsmtHalfBath']))
# 增添几个特征用于描述房屋内是否存在这些区域空间
feature['haspool'] = feature['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
feature['has2ndfloor'] = feature['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
feature['hasgarage'] = feature['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
feature['hasbsmt'] = feature['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)
feature['hasfireplace'] = feature['Fireplaces'].apply(lambda x: 1 if x > 0 else 0)
feature.shape
#out: (2913, 89)
5. 对特征编码
#使用get_dummies进行One-Hot编码
final_feature=pd.get_dummies(feature)
final_feature.shape
#out: (2913, 342)
四、模型预测
1. 环境配置
from sklearn.model_selection import cross_val_score,KFold,learning_curve,GridSearchCV
from sklearn.linear_model import RidgeCV,LassoCV,ElasticNetCV
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import VotingRegressor
2. 拆分训练集与测试集
#将训练集和测试集分开
X=final_feature.iloc[:train.shape[0],:]
X_test=final_feature.iloc[train.shape[0]:,:]
X_test.shape,X.shape
#out: ((1459, 342), (1454, 342))
3. 构建模型
使用的回归算法有ElasticNet,Lasso,Ridge。
kfold=KFold(n_splits=10, shuffle=True, random_state=42)
e_alphas = [0.0001, 0.0002, 0.0003, 0.0004, 0.0005, 0.0006, 0.0007]
e_l1ratio = [0.8, 0.85, 0.9, 0.95, 0.99, 1]
ridge=make_pipeline(RobustScaler(),RidgeCV(alphas=np.arange(1,10,1),cv=kfold))
lasso=make_pipeline(RobustScaler(),LassoCV(alphas=np.linspace(0.0001,0.001,10),cv=kfold,random_state=42,max_iter=1e7))
elasticnet = make_pipeline(RobustScaler(), ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfold, l1_ratio=e_l1ratio))
print(np.sqrt(-cross_val_score(lasso,X,y,cv=kfold,scoring='neg_mean_squared_error')).mean())
print(np.sqrt(-cross_val_score(ridge,X,y,cv=kfold,scoring='neg_mean_squared_error')).mean())
print(np.sqrt(-cross_val_score(elasticnet,X,y,cv=kfold,scoring='neg_mean_squared_error')).mean())
#运行结果:
0.10704224825755086
0.10973603634317217
0.10715922467109365
可以看出,使用lasso回归训练出的RMSE为0.10704224825755086,低于岭回归和弹性网ElasticNet。画出模型的学习曲线,观察拟合的情况。
model=[ridge,lasso,elasticnet]
figure,ax=plt.subplots(1,3,figsize=(30,4))
for i in range(3):
train_sizes, train_scores, valid_scores=learning_curve(model[i],X,y, cv=5,random_state=10,scoring='neg_mean_squared_error')
train_std=-np.mean(train_scores,axis=1)
test_std=-np.mean(valid_scores,axis=1)
ax[i].plot(train_sizes,train_std,color='red',label='train_scores')
ax[i].plot(train_sizes,test_std,color='blue',label='test_scores')
plt.legend()

接下来尝试一下模型融合。
3.1最大投票法
最大投票方法通常用于分类问题。这种技术中使用多个模型来预测每个数据点。每个模型的预测都被视为一次“投票”。大多数模型得到的预测被用作最终预测结果。
from sklearn.ensemble import VotingRegressor
voting_model=VotingRegressor(estimators=[('ridge',ridge),('lasso',lasso),('elasticnet',elasticnet)])
print(np.sqrt(-cross_val_score(voting_model,X,y,cv=kfold,scoring='neg_mean_squared_error')).mean())
结果为0.107445348033501,比单个模型lasso的RMSE还高。
3.1加权平均法
平均法包括算术平均法和加权平均法。加权平均法是指为所有模型分配不同的权重,定义每个模型的预测重要性
首先训练模型:
elastic_model_full_data = elasticnet.fit(X, y)
lasso_model_full_data = lasso.fit(X, y)
ridge_model_full_data = ridge.fit(X, y)
为每个模型增加权重:
def blend_models_predict(X):
return ((0.35* elastic_model_full_data.predict(X))+(0.25* lasso_model_full_data.predict(X)) + (0.4* ridge_model_full_data.predict(X)))
计算RMSE
print(np.sqrt(mean_squared_error(y,blend_models_predict(X))))
结果为0.09622783039540445,非常惊喜!使用加权平均法比单个模型lasso的表现提升了不少。最终我们选择加权平均法。
6. 结果保存
submission = pd.read_csv('sample_submission.csv')
a=np.expm1(blend_models_predict(X_test))
submission['SalePrice']=a
submission.to_csv('submission3.csv',index=False)
最终结果在kaggle房屋预测5313个队伍中排名514名,TOP10%。
