Flink数据流编程模型(Dataflow Programming Model)
目录
抽象层次(Levels of Abstraction)
程序与数据流(Programs and Dataflows)
Parallel Dataflows(并行数据流)
窗口(Windows)
时间(Time)
有状态操作(Stateful Operations)
容错检查点(Checkpoints for Fault Tolerance)
流中的批(Batch on Streaming)
原文链接
抽象层次(Levels of Abstraction)
Flink提供了不同层次的抽象来开发流/批处理(streaming/batch)应用程序。如下:
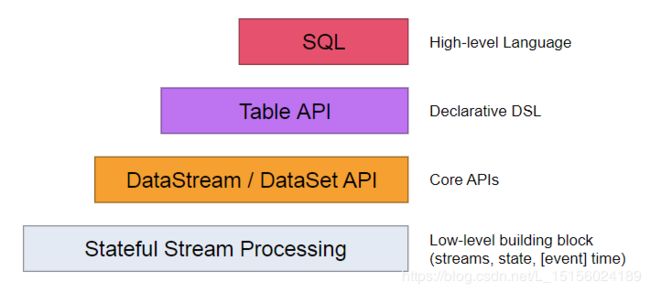
抽象级别从低到高依次是:Stateful Stream Processing —> DataStream/DataSet API —> Table API —> SQL。
(1)Stateful Stream Processing
它是整个抽象的最底层,通过过程函数(Process Function)嵌入到DataStream API中。它允许用户自由地处理来自一个或多个流(streams)的事件(events),并使用一致的容错状态(consistent fault tolerant state)。此外,用户可以注册事件时间和处理时间回调,让程序实现复杂的计算。
(2)DataStream/DataSet API
实际上,大多数应用程序不需要上面描述的低级抽象(指的是Stateful Stream Processing),而是根据核心API进行编程,如DataStream API(有界/无界流,bounded/unbounded streams)和DataSet API(有界数据集,bounded data sets)。这些连贯api为数据处理提供了常见的构建块,比如用户指定的各种形式的转换(transformations)、连接(joins)、聚合(aggregations)、窗口(windows)、状态(state)等。在这些api中处理的数据类型(Data types)在各自的编程语言中表示为类。
低层流程功能与DataStream API集成,使得仅对某些操作进行低层抽象成为可能。DataSet API在有界数据集上提供了额外的原语(primitives ),比如循环/迭代。
(3)Table API
它是一种以表为中心的声明式DSL,它可以动态更改表(在表示流时)。表API遵循(扩展的)关系模型:表附带一个模式(类似于关系数据库中的表),并且Table API提供了类似的操作,如选择(select)、投射(project)、连接(join)、分组(group-by)、聚合(aggregate)等。表API程序以声明的方式定义应该执行的逻辑操作,而不是确切地指定操作代码的外观。尽管表API可以通过各种类型的用户定义函数进行扩展,但它的表达式较少
(4)SQL
Flink提供的最高级抽象是SQL。这种抽象在语义和表达上与Table API相似,但是将程序表示为SQL查询表达式。SQL抽象与Table API密切交互,可以在Table API中定义的表上执行SQL查询。
程序与数据流(Programs and Dataflows)
Flink程序的基本构建块是流(streams )和转换(transformations)。从概念上讲,流(streams )是数据记录的流(flow)(可能是永无休止的),而转换(transformations)是将一个或多个流作为输入,并产生一个或多个输出流的操作。
当执行时,Flink程序被映射为流动的数据流(streaming dataflows),包括流和转换操作符。每个数据流(dataflow)从一个或多个源(sources )开始,以一个或多个接收(sinks)结束。数据流(dataflow)类似于任意有向无环图(DAGs)。尽管通过迭代构造允许特殊形式的环(cycles ),但为了简单起见,我们在大多数情况下将忽略这一点,也就是仍然看成有向无环图(笔者注)。下面看个例子:
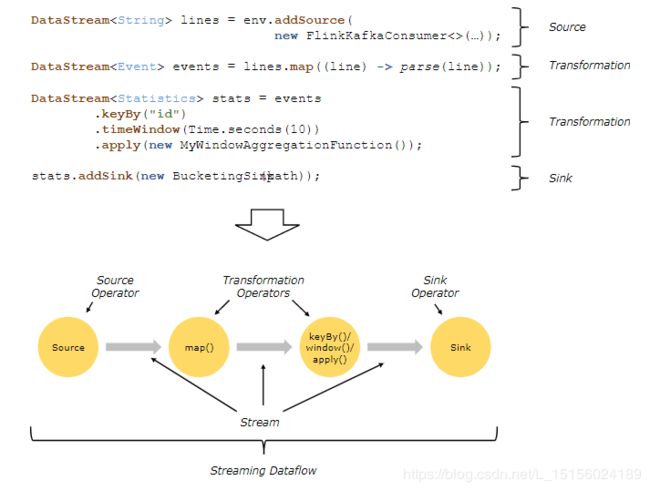
图的上半部分是程序,主要包含了三个部分:source、transfomation和sink。图的下半部分是程序对应的数据流(dataflow)。
笔者注:本文将DataStream和Dataflow都翻译为数据流, 从图中能看出它俩的本质区别,DataStream是真实数据记录的抽象,而Dataflow是程序对应的一个有向无环图。如无特殊标注,数据流指的都是DataStream。
Parallel Dataflows(并行数据流)
Flink中的程序本质上是并行(parallel )和分布式的(distributed)。在程序执行期间,一个流(stream)有一个或多个流分区(stream partitions),每个操作(operator )有一个或多个操作子任务(operator subtasks)。操作子任务相互独立,在不同的线程或者可能在不同的机器或容器上执行。
一个操作的并行度(parallelism )指的是操作子任务的数量。流的并行度是产生该流的操作符的并行度。同一个程序的不同操作可能具有不同的并行度。如图:
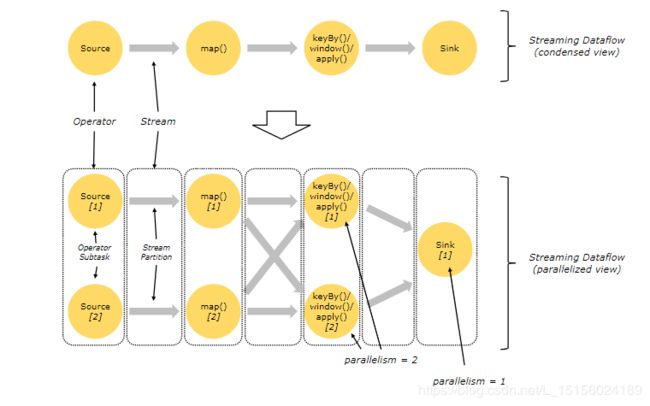
图的上半部分是简化的Dataflow,下半部分是从并行度角度分析的Dataflow。每个黄色实心圆表示一个操作子任务,灰色箭头表示流。看到,在sink之前并行度都是2,sink的并行度是1。
流可以以一对一模式(one-to-one pattern,也可以叫forwarding pattern)或重分布模式(redistributing pattern)在两个操作符之间传输数据。
(1)One-to-one streams
比如图中Source和map()之间的流就是一个One-to-one stream。它保持元素的分区(partitioning )和顺序(ordering )。这意味着map()操作符的子任务[1](也就是图中的map()[1])将看到与源操作符的子任务[1](也即是图中的Source[1])同样的元素,同样的顺序。
(2)Redistributing streams
比如图中的 map()和keyBy/window之间的流是一个redistributing stream。它更改了流的分区。根据所选择的转换,每个操作子任务(比如map)将数据发送到不同的目标子任务(比如keyBy)。
原文中认为keyBy/window和Sink之间也是一个Redistributing stream。但笔者认为,它应该归属于One-to-one stream,理由是它也是one-to-one,并没有发生Redistributing。
窗口(Windows)
聚合事件(例如计数、总和)在流中的工作方式与在批处理中不同。例如,不可能计算(count)流中的所有元素,因为流通常是无限的(无界的)。取而代之的是,流上的聚合是由窗口(windows)限定的,比如“最近5分钟的计数”,或者“最近100个元素的总和”。
窗口可以是时间驱动( time driven),例如每30秒统计一次,也可以是数据驱动的(data driven),比如每100个元素统计一次。窗口通常有如下三种,滚动窗口(tumbling windows)、滑动窗口(sliding windows)和会话窗口(session windows)。
(1)滚动窗口
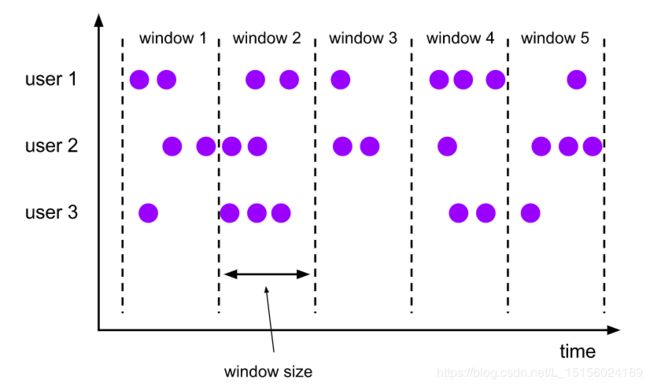
图中绘制了5个滚动窗口,每个窗口不重叠,无间隙。窗口大小相同。三个并行的用户user1、user2和user3数据被唯一的划分到某个窗口中参与计算。从示意图来看,后一个窗口可以通过滚动前一个窗口来生成。
(2)滑动窗口
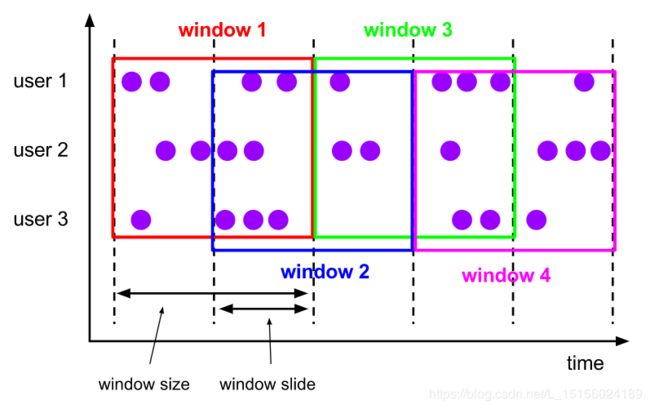
图中绘制了4个滑动窗口,滑动窗口有窗口大小(window size)和窗口滑动(window slide)两个要说构成。当window slide
(3)会话窗口
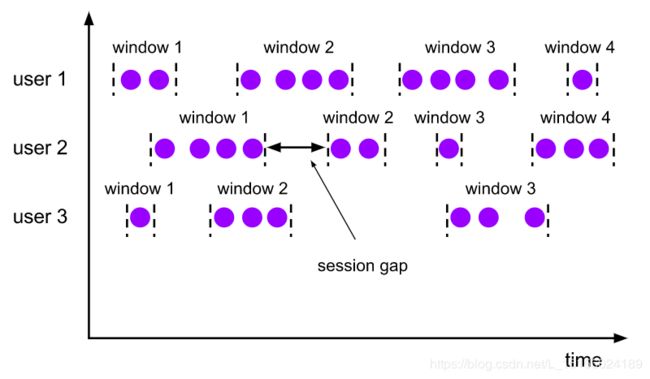
会话窗口没有重叠,也没有固定的开始和结束时间。会话窗口在一段时间内没有接收到元素会关闭,这段时间对应图中的session gap。如图,对于user1,有4个会话窗口,注意到每个窗口中的数据个数不同,窗口的长度也不同,窗口之间的session gap也不同。
时间(Time)
在一个流式程序中(比如定义上面的窗口)提及时间时,可以引用不同的时间概念(notions )。
(1)事件时间(Event Time)
事件发生或者被创建的时间。它通常用事件中的时间戳(timestamp )来描述,例如,由生产传感器或生产服务提供。
(2)摄入时间(Ingestion time)
事件进入Flink Dataflow的源操作符(Operator source)的时间,也就是进入上面Parallel Dataflows一节中的Dataflow图source的时间。可以简单理解成为进入Flink的时间。
(3)处理时间(Processing Time)
事件被处理的时间。
按照时间顺序,通常事件时间早于摄入时间,摄入时间早于处理时间。如图:
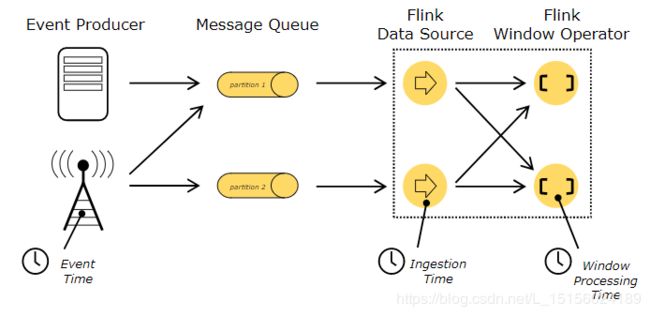
图中绘制了事件生产者(Event Producer),消息队列(Message Queue)和Flink DataFlow。
有状态操作(Stateful Operations)
虽然数据流(dataflow )中的许多操作一次只查看单个事件(例如事件解析器),但有些操作记住跨多个事件的信息(例如窗口操作符)。这些操作称为有状态操作。
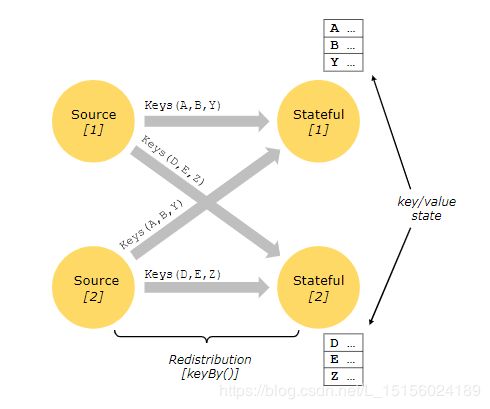
有状态操作的状态是在嵌入式键/值存储中维护的。状态是与有状态操作符读取的流一起严格分区和分发的。因此,只能在keyBy()函数之后的键流上访问键/值状态,并且仅限于与当前事件的键关联的值。对齐流和状态的键可以确保所有的状态更新都是本地操作,从而保证没有事务开销的一致性。这种对齐还允许Flink透明地重新分配状态和调整流分区。
容错检查点(Checkpoints for Fault Tolerance)
Flink结合使用流重放(stream replay)和检查点(checkpointing)来实现容错。检查点与每个输入流中的特定点以及每个操作符的对应状态相关。通过恢复操作符的状态并从检查点重播事件,流数据流可以从检查点恢复,同时保持一致性(精确的一次处理语义)。检查点间隔(checkpoint interval )是一种平衡执行期间容错开销和恢复时间(需要重放的事件数量)的方法。
流中的批(Batch on Streaming)
Flink将批处理程序( batch programs)作为流程序(streaming programs)的一种特殊情况来执行,这种流式有界的。因此,上面的概念以同样的方式适用于批处理程序,也适用于流程序,但有一些小的例外:
(1)批处理程序的容错不使用检查点(checkpointing)。恢复是通过完全重放流来实现的。这是可能的,因为输入是有界的。这推动了更多的成本恢复,但使常规处理更便宜,因为它避免了检查点。
(2)DataSet API 中的状态操作(Stateful operations )使用简化的内存/核外数据结构,而不是键/值索引。
(3)DataSet API引入了特殊的同步(基于超步的)迭代,这只能在有界流上实现。