Point RCNN论文翻译及图解
文章目录
- Abstract:
- 1.Introduction
- 2.Related Work
- 3.PointRCNN for Point Cloud 3D Detection
- 3.1 Bottom-up 3D proposal generation via point cloud segmentation
- 3.2 Point cloud region pooling
- 3.3 Canonical 3D bounding box refinement
- 图解
Abstract:
该论文的方法分成了两步:
- stage-1:自底而上地生成3D proposals。从已经分为前景点和背景点的点云中直接生成一些高质量的3D proposals。(之前的方法都是从 RGB图 或 将点云映射到俯瞰图 或 映射成voxels等)
- stage-2:阶段2的子网络将每个proposals的池化的点转换到正规坐标系,从而学习更好的局部空间特征,然后和阶段1学到的每个点的全局语义特征结合,来进行准确的box微调和置信度预测。
1.Introduction
现在的2D检测算法已经能处理图像中的大幅度的视角(viewpoints)和背景簇(backgroudn clutters)的变化,但是基于点云的3D目标检测仍然面对着来自不规则的数据形式和3D目标的六个自由度的巨大搜索空间的挑战。
现在的自动驾驶中,最常使用的3D传感器是LiDAR传感器,通过生成点云来捕捉场景的3D结构。基于点云的3D检测的困难主要在于点云的不规则性(irregularity),3D检测的SOTA的方法,要么是将点云投射到俯视图来利用2D检测的框架,要么投射到前视图,要么是变成规则的3D voxels (如下图a)。但是这些都不是最佳的,而且还会遇到在量化(quantization)过程中信息缺失的问题。
Qi等人并没有将点云转换成voxels或其他的规则的数据结构来进行特征学习,而是提出PointNet,直接从点云数据来学习3D表示,用这个可以进行点云的分类和分割。
如下图b所示,他们后续的工作在3D目标检测中应用了PointNet,从2D RGB检测的结果获得了被截取的截椎点云(cropped frustum point cloud),然后基于这个来估计3D bounding box。
但是这种方法过于依赖2D检测的表现,而且没有利用3D信息来生成鲁棒的bounding box proposals.

3D目标在自动驾驶的场景中能很好的分隔开,因为3D bounding box都是带注释的,这点和2D image检测不同。3D目标检测的训练数据直接提供3D目标分割的语义掩码,而2D目标检测的bounding box只能为语义分割提供弱监督。
基于这些观测,我们提出了新颖的两阶段3D目标检测框架,命名为PointRCNN,能够后直接操作3D点云,还能实现鲁棒且精准的3D检测表现。如下图c所示。

我们提出的框架包含两个阶段:
- 第一阶段:
目的:用一个自底而上的方法生成3D bounding box proposals
方法: 通过利用3D bounding box来生成ground-truth分割掩码,第一阶段分割前景点,同时在这些被分割出来的点中生成少些bounding box proposals。
优势:避免了 在整个3D空间使用大量的anchor box和保存大量的计算。 - 第二阶段:
目的:进行标准的3D box微调
方法:在3D proposals生成之后,用一个点云区域池化的操作来池化来自第一阶段的要被学习的点。和现存的3D方法不同,现存的3D方法都是直接估计全局box坐标,而作者的方法是将被池化的3D点转换到正则坐标,并且和来自阶段1的被池化的点的特征还有分割掩码结合,从而学习相对坐标微调。
优势:充分利用了第一阶段分割和推荐子网络提供的全部信息。
为了学习更有效的坐标微调,作者还提出了针对推荐生成和微调的完全基于bin的3D box回归损失,随后的消融实验(ablation experiments)表明,这个收敛更快而且相比其他3D box回归损失有更好的召回率
作者的贡献:
- 提出了一个基于点云的自底而上的生成3D边界框推荐的算法,该算法通过将点云分成前景物体和背景,来生成了少些高质量的3D proposals。被学习的点代表来自分割后,这样不仅有利于生成推荐的生成,而且对后面的box的生成也很有好处。
- 被提出的标准的3D边界框微调利用了第一阶段生成的高召回率的推荐框,而且用鲁棒的基于bin的loss来学习预测在正则坐标系中的box坐标微调
- 胜过了SOTA
2.Related Work
3D object detection from 2D images:
这是一些从image估计3D边界框的方法:
- [24, 15] 利用3D和2D边界框之间的几何约束来恢复3D目标位置。
- [1, 44, 23]利用3D目标和CAD模型的相似性。
- Chen et al. [2, 3]用公式表示物体中的3D几何信息作为一个函数来给预定义的3D框评分。
但是这些工作只能产生粗糙的3D检测结果,原因是缺少深度信息,而且很容易被外观改变影响结果。
3D object detection from point clouds:
SOTA 3D目标检测方法提出了很多方法来从稀疏的3D点云中学习不同的特征。
- [4, 14, 42, 17, 41]将点云投射到俯视图中,然后用2D CNN来学习点云的特征,之后再进行3D box生成。
- Song et al. [34] and Zhou et al. [43]将点聚到一块形成voxels,然后用3D CNN去学习voxels的特征来生成3D boxes。
但是,无论是俯视图还是voxels,都会因为数据量化而造成信息丢失,而且3D CNN的内存和计算方面都不高效。
- [25, 39]利用成熟的2D检测来从image生成2D proposals,并且在每个被裁剪的图像区域中减少了3D点的size。
- PointNet [26, 28] 利用点云特征来进行3D框预测。
但是,基于2D图像的推荐生成很有可能在一些只能在3D空间下才能很好观测的情况下失败。而且,这些失败还不能通过3D框预测来恢复。
正相反的是,作者的自底而上的3D推荐生成方法,直接从点云生成鲁棒的3D推荐,既高效又不需要量化(quantization free)。
Learning point cloud representations:
Qi等人没有将点云变成voxels或者多视点格式,而是提出了PointNet框架来直接从原始点云学习点云特征,在点云的分割和分类处理上又快又准。之后进行的工作[28, 12],通过考虑点云的局部结构来提高抽取特征的质量。
作者的工作将基于点的特征抽取拓展到了基于3D点云的目标检测中,因此形成了一个全新的二阶段3D检测框架(直接从原始点云生成3D框推荐和检测结果)。
3.PointRCNN for Point Cloud 3D Detection

3.1 Bottom-up 3D proposal generation via point cloud segmentation
现在的2D目标检测能分成两种:一种是一阶段的,通常更快但是直接估算目标边界框而没有微调;一种是二阶段的,在第二阶段微调proposals和confidence。然而, 直接将2D的二阶段方法拓展到3D是不现实的,因为3D的搜索空间非常大,而且点云也是不规则的形式。
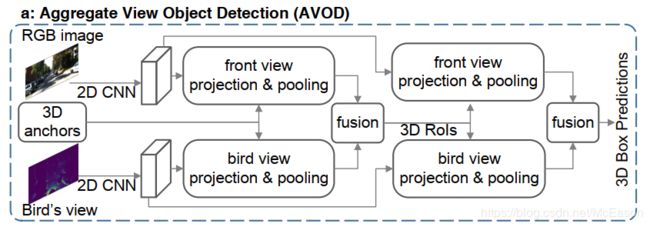
AVOD[14]在3D空间安置了80-100k个anchor boxes,而且再对视角中对每个anchor进行池化特征,以此来生成proposals。
FPointNet[25]从2D图像生成2D proposals,然后基于从2D区域裁剪出来的3D点来估计3D boxes,但是这样可能会忽略掉只有在3D空间才能观察到的物体。
作者提出了一种准确、鲁棒的基于全场景点云分割的3D proposals生成算法。作者观察到,在3D场景中,各个物体之间都是很自然的分隔开的,相互之间没有重叠。所有的3D物体的分割掩码都能通过他们的3D边界框注释直接获得,即,在3D框中的3D点可以被认为是前景点。
作者因此提出了在一个自底而上的方法中生成3D proposals。具体的,我们逐点地学习特征来分割原始点云,并且同时从已经分割好的前景点中生成3D proposals。基于这个自底而上的策略,我们的方法避免了使用一系列很多的在3D空间预定义的3D boxes,而且极大的限制了3D proposals生成的搜索空间。实验证明,我们的方法比基于3D anchor的推荐生成算法的召回率更高。
Learning point cloud representations
为了学习有区别的逐点特征来描述原始点云,我们使用带有多尺度分组的PointNet++作为主干网络,这还有一些其他的可选网络,也能作为我们的主干:such as [26, 13] or VoxelNet [43] with sparse convolutions [9]。
Foreground point segmentation
前景点在预测和他们相关联的物体的位置和方向的时候能提供充足的信息。为了学习如何分割前景点,点云网络被迫捕捉前后关系来做出精准的逐点预测,而且这对生成3D box也有好处。我们设计的自底而上的3D proposal生成方法直接从前景点生成3D box proposals,即,前景分割和3D box proposal生成同时进行。
考虑到主干点云网络编码的点向特征,我们增加了一个用于估计前景掩码的分割头,还增加了一个用于生成3D proposals的box回归头。3D ground-truth boxes提供ground-truth分割掩码来给点分割使用。对于一个大尺度的外景来说,前景点的数量是远小于背景点的。因此我们使用焦点损失(focal loss)[19]来处理类不平衡问题:
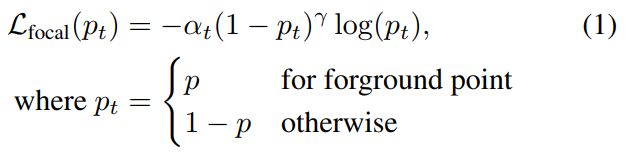
在训练点云分割的时候,设置 α t = 0.25 , γ = 2 \alpha_t = 0.25\ ,\gamma = 2 αt=0.25 ,γ=2。
Bin-based 3D bounding box generation
正如上面提到的,添加了一个box回归头来和前景点分割同时生成自底而上的3Dproposasl。在训练的时候,只要求box回归头能从前景点中回归出3D bounding box位置。注意,虽然没有从背景点中回归box,但是因为点云网络的感受野,这些背景点也为生成box提供了支持信息。
一个3D边界框在LiDAR坐标系中被表示成 ( x , y , z , h , w , l , θ ) (x,y,z,h,w,l,\theta) (x,y,z,h,w,l,θ),其中 ( x , y , z ) (x,y,z) (x,y,z)是目标中心位置, ( h , w , l ) (h,w,l) (h,w,l)是目标的size, θ \theta θ是俯视图下的目标方向。为了约束生成的3D box proposals,我们提出基于bin的回归损失来估算物体的3D bounding boxes。

为了估计一个目标的中心位置,如图3,我们将每个前景点周围的区域沿着 Z , X Z,X Z,X轴分裂成一系列的离散bin。具体来说,我们为当前前景点的每个 X , Z X,Z X,Z轴设置了一个搜索范围 S S S,每个一维搜索范围被划分成等长 δ \delta δ的bins来表示不同的物体在X-Z平面的中心 ( x , z ) (x,z) (x,z)。
我们发现,对X-Z轴使用基于bin的交叉熵损失分类,比直接用smooth L 1 L1 L1 loss回归,能得出更加精准鲁棒的中心定位结果。
对于 X , Z X,Z X,Z轴的定位loss由两部分组成:一部分是沿着每个X,Z轴的bin分类,一部分是在被分类好的bin中的残差回归。
对于沿着 Y Y Y轴的中心位置 y y y,我们直接使用smooth L 1 L1 L1 loss来回归,因为大部分物体的 y y y值都在一个很小的范围内,使用 L 1 L1 L1 loss足够获得精准的 y y y值。
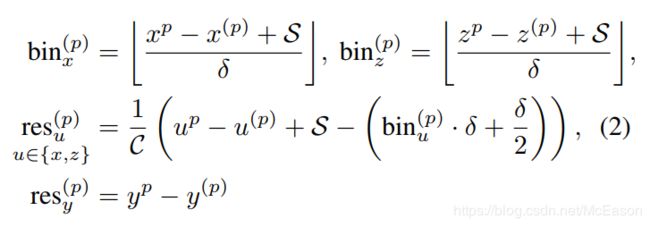
( x ( p ) , y ( p ) , z ( p ) ) (x^{(p)},y^{(p)},z^{(p)}) (x(p),y(p),z(p))是FPOI( foreground point of interest )的坐标。
( x P , y P , z P ) (x^P,y^P,z^P) (xP,yP,zP)是它对应的物体的中心坐标。
b i n x ( p ) , b i n z ( p ) bin^{(p)}_x,bin^{(p)}_z binx(p),binz(p)是沿着 X , Z X,Z X,Z轴分配的ground-truth bin。
r e s x ( p ) , r e s z ( p ) res^{(p)}_x,res^{(p)}_z resx(p),resz(p)是在被分配的bin中做进一步定位微调的ground-truth残差。
C C C是归一化的bin长度
Object属性设置:
对象的方向和size的估算方法和[25]差不多。我们将方向 2 π 2\pi 2π分到 n n n个bins中,然后在 x , z x,z x,z方向计算bin分类目标 b i n θ p bin^{p}_\theta binθp和残差回归对象 r e s θ ( p ) res^{(p)}_\theta resθ(p)。物体的size ( h , w , l ) (h,w,l) (h,w,l)通过计算关于整个训练集的每个类的平均目标尺寸来直接回归得到。
相关参数初始化\设置:
在推理阶段,对于基于bin的预测参数, x , z , θ x,z,\theta x,z,θ,我们首先选择有最高的预测置信度的bin中心,并且添加预测残差来获得微调的参数。对于其他的直接回归的参数,包括 y , h , w , l y,h,w,l y,h,w,l,我们将预测残差添加到到他们的初始值。
训练损失函数:
不同的训练损失项下的整个3D边界框的回归损失 L r e g L_{reg} Lreg能被如下表示:

N p o s N_{pos} Npos是前景点的数量。
b i n u ^ ( p ) \widehat{{bin}_u}^{(p)} binu (p)和 r e s u ^ ( p ) \widehat{{res}_u}^{(p)} resu (p)是前景点 p p p的被预测的bin分配和残差。
b i n u ( p ) {bin}^{(p)}_u binu(p)和 r e s u ( p ) res^{(p)}_u resu(p)是上面已经计算过的ground-truth对象。
F c l s F_{cls} Fcls是分类的交叉熵损失。
F r e g F_{reg} Freg是smooth L 1 L1 L1 loss。
训练和推理的NMS:
为了移除冗余的proposals,我们对基于鸟瞰的定向IoU使用NMS,来生成少些高质量的proposals。
训练的时候,设置鸟瞰IoU的阈值是0.85,NMS保留前300个proposals来给阶段2的子网络训练。
推理的时候,设置鸟瞰IoU的阈值是0.8,NMS保留前100个proposals给阶段2的微调子网络使用。
3.2 Point cloud region pooling
要做的事情:
获取了3D边界框推荐之后,我们的目标是基于之前生成的box推荐来微调 box定位和方向。
为了学习每个proposals更具体的局部特征,我们建议根据每个3D推荐来池化来自阶段1的3D点以及它们对应的点特征。
扩大3D推荐框:
对于每个3D推荐框, b i = ( x i , y i , z i , h i , w i , l i , θ i ) b_i = (x_i,y_i,z_i,h_i,w_i,l_i,\theta_i) bi=(xi,yi,zi,hi,wi,li,θi),我们稍微放大一下,创造一个新的3D框 b i e = ( x i , y i , z i , h i + η , w i + η , l i + η , θ i ) b^e_i=(x_i,y_i,z_i,h_i+\eta,w_i+\eta,l_i+\eta,\theta_i) bie=(xi,yi,zi,hi+η,wi+η,li+η,θi)来从他的环境中编码额外的信息,其中 η \eta η是一个用来放大box的大小的固定值。
判断点在不在扩大的box内:
对于每个点 p = ( x ( p ) , y ( p ) , z ( p ) ) p=(x^{(p)},y^{(p)},z^{(p)}) p=(x(p),y(p),z(p)),执行一个内/外测试来判断这个点在不在被扩大的推荐框 b i e b^e_i bie中。如果在的话,这个点和他的特征就会被保留用来微调 b i b_i bi.
和内部的点 p p p相关的特征包括:
- 他的3D点坐标 ( x ( p ) , y ( p ) , z ( p ) ) ∈ R 3 (x^{(p)},y^{(p)},z^{(p)})\in\R^3 (x(p),y(p),z(p))∈R3
- 他的激光反射强度 r ( p ) ∈ R r^{(p)}\in\R r(p)∈R
- 他的来自阶段1的预测分割掩码 m ( p ) ∈ { 0 , 1 } m^{(p)}\in\{0,1\} m(p)∈{0,1}
- 他的来自一阶段的 C C C维学习点特征表示 f ( p ) ∈ R c f^{(p)}\in\R^c f(p)∈Rc
我们通过包含分割掩码 m ( p ) m^{(p)} m(p)来区分在扩大的box里是前景点还是背景点。学习点特征 f ( p ) f^{(p)} f(p)通过学习编码有价值的信息,用于分割和生成proposals。在接下来的阶段中,我们将消除那些没有内部点的proposals。
3.3 Canonical 3D bounding box refinement

如图b所示,每个proposals的池化点和他们的相关特征都被喂进阶段二的子网络,来微调3D框位置还有前景目标置信度。
Canonical transformation:
为了利用我们第一阶段的高召回率的推荐框,并且仅估计推荐框参数的残差,我们将属于每个proposals的池化点转换为相应3D proposal的正则坐标系。
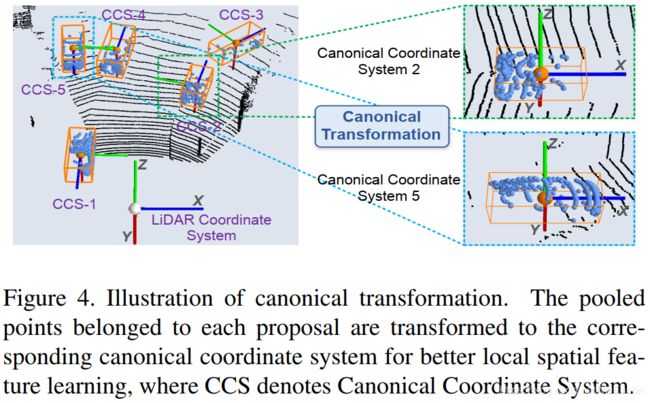
如上图所示,一个3D proposals的正则坐标系表示:
- 原点在推荐框的中间
- 局部的 X ′ X' X′和 Z ′ Z' Z′轴近似平行于地平面, X ′ X' X′指向proposals的头部方向,另一个 Z ′ Z' Z′轴垂直于 X ′ X' X′
- Y ′ Y' Y′轴与LiDAR坐标系保持一致
推荐框的全部的池化点的坐标 p p p都应该通过合适的旋转和位移来转换成正则坐标系 p ~ \widetilde{p} p 。使用建议的正则坐标系统可以使box微调阶段更好地学习每个proposals的局部空间特征。
Feature learning for box proposal refinement:
微调子网络的组成:
微调子网络,由已经转换的局部空间点特征 p ~ \widetilde{p} p 和他们的来自阶段1的全局语义特征 f ( p ) f^{(p)} f(p)组成,进行更好的box和confidence微调。
正则变化的缺陷及解决方案:
尽管正则变换能够实现鲁棒的局部空间特征学习,但不可避免地会丢失每个对象的深度信息。例如,由于LiDAR传感器的固定角度扫描分辨率,远处的物体通常比附近的物体拥有更少的点。为了补偿深度信息的丢失,我们给传感器的加入距离,即, d ( p ) = ( x ( p ) ) 2 + ( y ( p ) ) 2 + ( z ( p ) ) 2 d^{(p)}=\sqrt{(x^{(p)})^2+(y^{(p)})^2+(z^{(p)})^2} d(p)=(x(p))2+(y(p))2+(z(p))2,我们将这个东西加入到点 p p p的特征中。
proposals的所有特征都得到后,进行的操作:
对于每个proposals,首先将其关联点的局部空间特征 p ~ \widetilde{p} p 和额外特征 [ r ( p ) , m ( p ) , d ( p ) ] [r^{(p)},m^{(p)},d^{(p)}] [r(p),m(p),d(p)]连接到几个全连接的层上,将它们的局部特征编码为与全局特征 f ( p ) f^{(p)} f(p)相同的维数。然后将局部特征和全局特征连接起来,按照[28]的结构喂进网络,得到有区别的特征向量,进行置信分类和box微调。
Losses for box proposal refinement:
gt与proposal对应:
我们对proposals微调采用类似的基于bin的回归损失。如果一个ground-trurh box和一个3D box proposals的IoU大于0.55,那么就把这个gt box分给3D box proposals来学习box微调。
3D proposals和相应的3D ground-truth boxes都被转换成正则坐标系,因此:
3D proposal b i = ( x i , y i , z i , h i , w i , l i , θ i ) b_i=(x_i,y_i,z_i,h_i,w_i,l_i,\theta_i) bi=(xi,yi,zi,hi,wi,li,θi)
to
b ~ i = ( 0 , 0 , 0 , h i , w i , l i , 0 ) \widetilde{b}_i=(0,0,0,h_i,w_i,l_i,0) b i=(0,0,0,hi,wi,li,0)
3D ground-truth box b i g t = ( x i g t , y i g t , z i g t , h i g t , w i g t , l i g t , θ i g t ) b^{gt}_i=(x^{gt}_i,y^{gt}_i,z^{gt}_i,h^{gt}_i,w^{gt}_i,l^{gt}_i,\theta^{gt}_i) bigt=(xigt,yigt,zigt,higt,wigt,ligt,θigt)
to
b ~ i g t = ( x i g t − x i , y i g t − y i , z i g t − z i , h i g t , w i g t , l i g t , θ i g t − θ i ) \widetilde{b}^{gt}_i=(x^{gt}_i-x_i,y^{gt}_i-y_i,z^{gt}_i-z_i,h^{gt}_i,w^{gt}_i,l^{gt}_i,\theta^{gt}_i-\theta_i) b igt=(xigt−xi,yigt−yi,zigt−zi,higt,wigt,ligt,θigt−θi)
训练时box位置和size:
训练的对象的第 i i i个bo推荐框的中心位置, ( b i n Δ x i , b i n Δ z i , r e s Δ x i , r e s Δ z i , r e s Δ y i ) (bin^i_{\Delta x},bin^i_{\Delta z},res^i_{\Delta x},res^i_{\Delta z},res^i_{\Delta y}) (binΔxi,binΔzi,resΔxi,resΔzi,resΔyi),设置方法和公式2相同,只是我们使用更小的搜索范围 S S S来微调3D proposal的位置。
关于训练集中的每个类的平均物体尺寸,我们仍然直接回归尺寸残差 ( r e s Δ h i , r e s Δ w i , r e s Δ l i ) (res^i_{\Delta h},res^i_{\Delta w},res^i_{\Delta l}) (resΔhi,resΔwi,resΔli),这样做是因为被池化的稀疏点通常不能提供足够的proposal尺寸信息 ( h i , w i , l i ) (h_i,w_i,l_i) (hi,wi,li)。
训练时微调方向:
对于微调方向,关于ground-turth方向我们假定角度是不同的, θ i g t − θ i \theta^{gt}_i-\theta_i θigt−θi的范围是 [ − π 4 , π 4 ] [-{\pi \over 4},{\pi \over 4}] [−4π,4π],这是因为IoU大于0.55的。因此,我们把 π 2 \pi \over 2 2π分成离散的bin和bin的尺寸 w w w,并且预测基于bin的方向目标:

所以,整个二阶段子网络的全部loss如下:
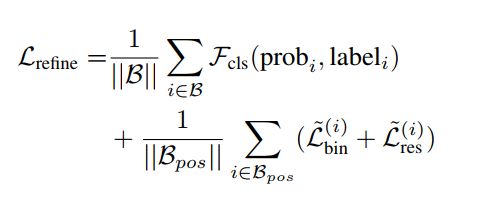
β \beta β是来自一阶段的3D proposals几何
B p o s B_{pos} Bpos存放着positive的回归proposals
p r o b i prob_i probi是估算的 b ~ i \widetilde{b}_i b i的置信度
l a b e l i label_i labeli是对应的label
L ~ b i n ( i ) \widetilde{L}^{(i)}_{bin} L bin(i)和 L ~ r e s ( i ) \widetilde{L}^{(i)}_{res} L res(i)和公式3中的相似,但是使用的是上面提到的通过 b ~ i g t \widetilde{b}^{gt}_i b igt和 b ~ i \widetilde{b}_i b i计算的新的对象
最后应用鸟瞰IoU阈值0.01的有方向的NMS去除重叠的边界框,并且生成被检测对象的三维边界框。
图解
参考博客地址
第一次看3D检测论文,实在是没看懂,只是整理下论文和参考的博客的内容,希望有大佬能指正教我
