GoogLeNet-Good LeNet 致敬LeNET
GoogLeNet 致敬LeNET
直到论文看了一大半,才发现这个名字其实不是GoogleNet。。。
Inception architecture
Main idea is based on finding out how an optimal local structure in a convolutional vision network can be approximated and covered by readily available dense components.
基本结构就是组合多个卷积核的输出,按通道拼接在一起得到最终的输出

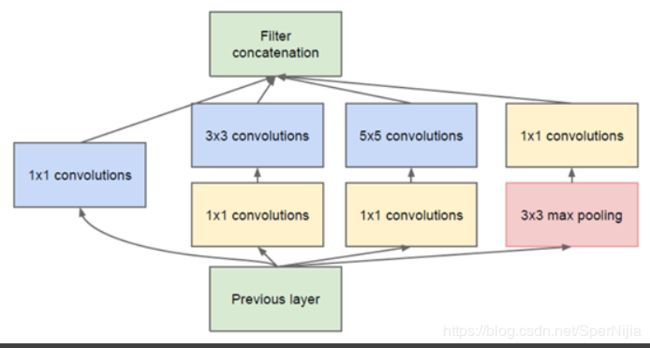
在第一代Inception的时候,被限制使用三种类型的filter: 1 × 1 , 3 × 3 , 5 × 5 1\times1,3\times3,5\times5 1×1,3×3,5×5 ,同时根据以往工作的经验,加入池化层会有一个好的影响,所以平行的加入了一个 3 × 3 3\times3 3×3的最大池化层。
这样做的话会有一个问题,对于 5 × 5 5\times5 5×5的filter 直接对上一层的输入进行计算,这样的花销有点大
所以就衍生出了优化版本,在 5 × 5 和 3 × 3 5\times5和3\times3 5×5和3×3的filter 之前加入一个 1 × 1 1\times1 1×1的filter,同时也在这些模块后加入Relu,这个可以降低输入数据的通道数或者说是深度:
-
池化层的stride为2
-
有些卷积层需要进行padding,保证输出数据的宽高一致
-
这种结构更多的时候会放在高层,在底层的时候还是使用传统的卷积结构
-
如果结构设计的妥当的话,使用inception结构会比不适用加快2-3倍。
完整GoodNet结构
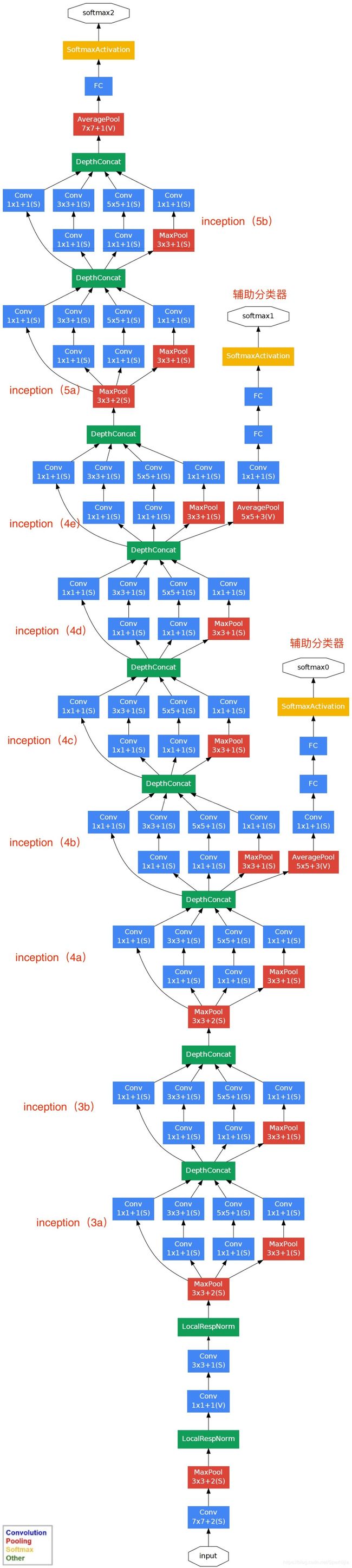
- input:224* 224 * 3
- 分别在4a和4d加入了两个辅助分类器 auxiliary classifier,以权重0.3 加到最终的loss中。在测试时候,去掉这些辅助分类器
- 对于辅助分类器中全连接层dropout设置为0.7,主线上的dropout设置为0.4
- inception都加入了合适的填充,来保证输出的一致性
pytorch 代码实现
class Inception(nn.Module):
def __init__(self,in_c,c1,c2,c3,c4):#为每条线路里面的通道数
super(Inception,self).__init__()
#线路1 单个1×1的卷积
self.p1=nn.Conv2d(in_c,c1,kernel_size=1)
#线路2 1×1 接 3×3
self.p2_1=nn.Conv2d(in_c,c2[0],kernel_size=1)
self.p2_2=nn.Conv2d(c2[0],c2[1],kernel_size=3,padding=1)
#线路3 1×1 接5×5
self.p3_1=nn.Conv2d(in_c,c3[0],kernel_size=1)
self.p3_2=nn.Conv2d(c3[0],c3[1],kernel_size=5,padding=2)
#线路4 3×3最大池化 接 1×1 卷积
self.p4_1=nn.MaxPool2d(kernel_size=3,padding=1,stride=1)#这里要指定一下stride 否则与kernelsize一样
self.p4_2=nn.Conv2d(in_c,c4,kernel_size=1)
def forward(self,x):
p1=F.relu(self.p1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
d2l.GlobalAvgPool2d()
)
net = nn.Sequential(b1, b2, b3, b4, b5,
d2l.FlattenLayer(), nn.Linear(1024, 10))
nn.Sequential(b1, b2, b3, b4, b5,
d2l.FlattenLayer(), nn.Linear(1024, 10))