又一次全球第一!| 凌云时刻

凌云时刻 · 极鲜速递


导读:揭秘阿里云对象存储OSS可用性SLA背后的技术体系。
作者 | 云布道师 罗庆超
来源 | 凌云时刻(微信号:linuxpk)
1. 概述

2020年6月,阿里云对象存储OSS通过十年积累的技术红利,将可用性SLA(Service Level Agreement) 提升10倍,做到了全球第一的核心竞争力,是其他的云厂家的10~20倍。

其中, OSS 的标准型(同城冗余)存储,SLA 从 99.95% 提升到 99.995%,简单理解就是如果 10万 个请求中只要有5个请求返回服务端错误,OSS 将会赔付。
2. OSS可用性SLA说明
 2.1 常见的可用性指标(年故障时长)
2.1 常见的可用性指标(年故障时长)
业界对可用性的描述,通常采用年故障时长。比如,数据中心机房划分为不同等级,如 T1~T4 机房,它们的可用性指标如下所示。
T1 机房:可用性 99.671%、年平均故障时间 28.8 小时
T2 机房:可用性 99.741%、年平均故障时间 22 小时
T3 机房:可用性 99.982%、年平均故障时间 1.6 小时
T4 机房:可用性 99.995%、年平均故障时间 0.4 小时
网络服务的可用性,通常也会折算为不能提供服务的故障时间长度来衡量,比如典型的5个9可用性就表示年故障时长为5分钟,如下表所示。

对于实例型云服务,典型如阿里云的 ECS,它提供了一台计算实例,该实例的可用性直接与可用时间相关,所以它也是采用年故障时长来定义可用性。
2.2 对象存储OSS可用性SLA指标
对象存储是资源访问型云服务,它不提供实例而是 Serverless 化的 API 调用,按照“年故障时长”计算可用性是不合适的。所以,阿里云对象存储 OSS 选择“失败请求数:总请求数”的错误率严苛逻辑来计算可用性。
![]() 2.2.1 每5分钟粒度计算错误率
2.2.1 每5分钟粒度计算错误率
每5分钟错误率 = 每5分钟失败请求数/每5分钟有效总请求数*100%
计算请求错误率时,将计算请求的时间范围拉长,对云服务有利。
时间越长,总请求数越多,会导致错误率降低。为了更好的从客户角度计算错误率,按照5分钟的粒度来计算。高可用系统设计关键是冗余,而 5 分钟是业界典型的机器故障恢复时间,能够快速修复机器,可以将降低系统的错误率。
 2.2.2 基于服务周期内的5分钟错误率计算可用性
2.2.2 基于服务周期内的5分钟错误率计算可用性
服务可用性=(1-服务周期内∑每5分钟错误率/服务周期内5分钟总个数)*100%
对象存储 OSS 按月收费,因此服务周期就是自然月。
服务可用性,就是将服务周期内的每5分钟错误率求和,然后除以服务周期内 5 分钟总个数(按照自然月 30 天算,该值为 30*24*60/5=8640),然后用 1 减去平均错误率,就可得到该月的可用性。
根据此公式,如果每 5 分钟错误率过高,将会导致可用性下降;因此,提升每 5 分钟的请求成功率,将是提升可用性关键。
2.2.3 对比年故障时长和请求错误率模型
按照全年 26 分钟故障为基础,年故障时长模型可用性为99.995%。而 OSS 的请求错误率模型下,按每5分钟错误率来算,26 分钟至少有5个每5分钟错误率为100%,其他的每5分钟假设全部为0(没有错误),因此可用性最多为 1-5*100%/8640 = 1-0.058% = 99.942%,从而 OSS 的请求错误率模型更加严格。

2.2.4 OSS 可用性SLA承诺
基于上述可用性计算,用户可以得到自然月内的实际可用性。按照 OSS 可用性 SLA 承诺,如果没有达标,将进行赔付,真正做到“你敢用、我敢赔”,从而提升客户业务的可用性。

2.3 云厂商对象存储可用性SLA对比分析
看 AWS、AZURE、GCS、阿里云、腾讯云、华为云等厂家的对象存储可用性 SLA,看出阿里云对象存储可用性 SLA 是其他厂家的 10~20 倍,而且采用最严苛的5分钟粒度计算,保证客户第一。
其中,某传统存储转向做公共云的厂家,仍然采用传统线下存储的“可用时间方式”来计算可用性,确实还是延续原有的思路。
3. OSS可用性体系建设
阿里云对象存储 OSS 是历经十年研发的云服务,始终把可用性的建设作为核心竞争力来构建,从而形成了如下的可用性体系。

3.1 本地冗余和同城冗余架构
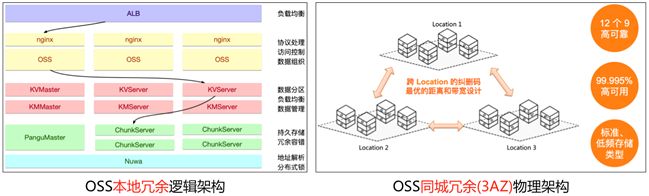
OSS提供了本地冗余存储(部署在一个 AZ)、同城冗余(部署在三个 AZ)存储类型,它们的逻辑架构相同,主要包含如下模块:女娲一致性服务、盘古分布式文件系统、OSS 元数据(有巢分布式 KV 索引)、OSS 服务端、网络负载均衡等。
同城冗余存储(3AZ)则是在物理架构上是提供机房级别的容灾能力,将用户数据副本分散到同城多个可用区。当出现火灾、台风、洪水、断电、断网等灾难事件,导致某个机房不可用时,OSS 仍然可以提供强一致性的服务能力。故障切换过程用户业务不中断、数据不丢失,可以满足关键业务系统对于 RTO(Recovery Time Objective)和 RPO(Recovery Point Objective)为 0 的强需求。同城冗余存储,可以提供 99.9999999999%(12个9)的数据设计可靠性以及99.995%的服务设计可用性。
3.2 IDC冗余设计
要实现更高的可用性,就必须在物理层做好冗余设计,包括如下的技术:
同城冗余多 AZ的距离和时延设计。在公共云部署时,会遵循阿里云IDC与网络架构设计规则及AZ选址标准,特别是要满足 OSS 的多 AZ 设计要求时,会严格要求时延和距离。
供电、制冷冗余。OSS对象存储是多区域部署的云服务,几乎每年都会遇到自然灾害、供电异常、空调设备故障等问题,在数据中心建设时要做好双路市电和柴油发电机备电的设计,以及连续制冷能力。
网络冗余。OSS作为公共云服务,既要提供外部的互联网访问、VPC网络访问,还要提供分布式系统的内部网络连接,它们都需要做好冗余设计。
外部网络。互联网接入多运营商的BGP和静态带宽,实现公网访问的冗余。同时,VPC 网络的接入则通过阿里云网络的冗余。
内部网络。OSS是分布式存储,由多台服务器组成,采用内部网络将多台服务器连通起来,通过数据中心的机柜级交换机、机柜间交换机、机房间交换机的分层设计实现冗余,即使某台网络设备故障,系统仍然能够正常工作。
服务器。OSS采用貔貅服务器系列优化性价比,基于分布式系统和软件定义存储的需求,硬件上采用通用服务器(commodityserver),并提供冗余的网络接口,无需采用传统存储阵列双控冗余设计的定制硬件。
3.3 分布式系统设计
3.3.1 女娲一致性服务
女娲是阿里云飞天系统底层核心模块之一,从2009年飞天建立起开始自主开发,女娲对外提供一致性,分布式锁,消息通知等服务。同业界类似功能的开源软件(ZooKeeper、ETCD)相比,女娲在性能、可扩展性、和可运维性上有明显的优势。

女娲服务采用两层架构,后端是一致性维护的功能模块,前端是达到分流效果的前端机。
前端机通过 VIP 做负载均衡。主要实现两个功能:第一点,负责维护众多客户端的长连接通信,从而保证客户端请求能够均衡到后端;第二点,向客户端隐藏后端的切换过程,同时提供高效的消息通知功能。
后端由多个服务器组成 PAXOS 组,形成一致性协议核心。对客户端提供的资源(文件,锁等),在后端都有归属的 Paxos Group仲裁,它采用 PAXOS 分布式一致性协议进行同步,保证资源的一致性和持久化。为了提供更好的扩展能力,后端提供了多个 Paxos Group。
因此,通过多 VIP 冗余、前端机透明切换、冗余的一致性仲裁 Paxos Group,实现故障时的快速切换,从而在一致性协调时提供高可用性。
3.3.2 盘古分布式文件
盘古2.0是第二代自研开发的分布式存储系统,在高性能、大规模、低成本等方面深度挖掘了系统的极限能力,支持更丰富的接入形态,进一步提升了系统的部署运维自动化智能化能力,同时继承了1.0在高可靠、高可用、数据强一致性等方面的积累优势。
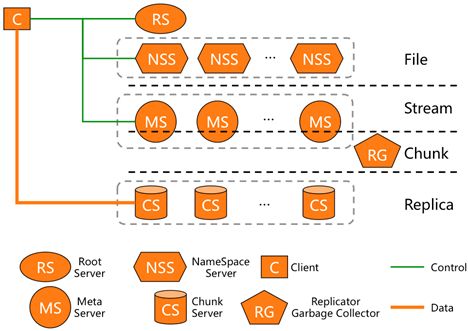
如上图描述的架构所示,各层元数据(RootServer、NameSpaceServer、MetaServer)都提供了冗余设计,故障时可以快速切换,对于数据(ChunkServer)来说通过 None-Stop-Write 特性解决服务器、磁盘故障时的快速切换,从而在分布式存储层提高可用性。
3.3.3 对象服务有巢分布式KV元数据快速切换
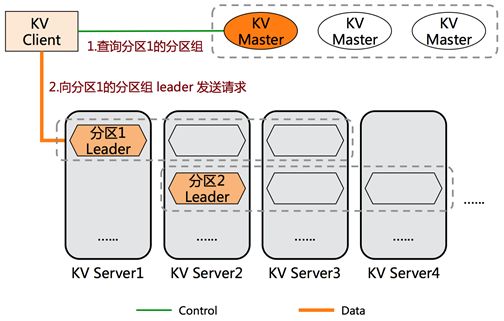
有巢分布式 KV 为 OSS 对象存储提供分布式Key-Value 元数据功能,作为阿里云最早研发的的 KV 系统,历经多年 OSS 的业务打磨,它在大规模集群下有非常深厚的技术积累。2014 年实现了多实例冗余的特性,把KV 分解为由多个副本成的分区组(partition group),该分区组通过一致性协议选举出 Leader 节点对外提供服务,当 Leader 节点故障或出现网络分区时,能够快速选出新的 Leader 节点并接管该分区的服务,从而提升 OSS 元数据服务的可用性,如下图所示。
3.3.4 对象服务QoS
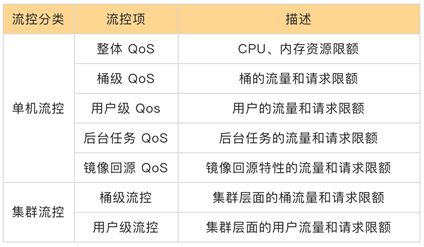
OSS服务层聚焦数据组织和功能实现,由于底层盘古和有巢的分布式能力,OSS 服务层按照无状态方式设计,从而故障时可以快速切换,提高可用性。但是,由于 OSS是多租户模型设计,做好 QoS 的监控和隔离,是保障租户可用性的关键。
3.3.5 网络负载均衡
OSS要承接海量的访问请求,因此接入层采用负载均衡,通过绑定VIP提供高可用服务,并且和 OSS 的前端机(FrontEnd)集群对接,任何模块故障都能能够快速切换,保证可用性。OSS 基于阿里云网络团队的负载均衡技术,提供了大流量、高性能访问能力。

3.4 安全防护
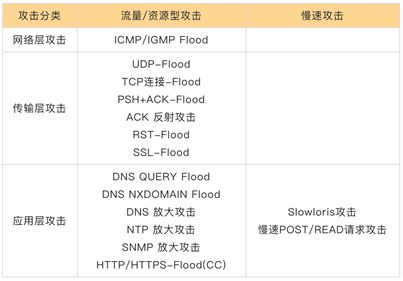
OSS提供 HTTP/HTTPS 的数据访问服务,会受到来自“互联网和VPC网络”的安全攻击,典型为DDoS (Distribution Deny ofService),安全攻击防护是保障 OSS 可用性的重要工作。
安全攻击的一个目的,就是让 OSS 之上的业务受损失,让整体的可用性降低。
安全攻击的两种方法,就是拥塞 OSS 有限的带宽入口(拥塞带宽)、耗尽 OSS 的计算资源(耗尽资源)。
安全攻击的三类攻击方式,针对拥塞带宽的网络流量型攻击(L3/L4 DDoS),针对耗尽资源的4层CC攻击(链接资源)、7层CC攻击(应用资源)。
细化的攻击分类,如下表所示。
3.5 智能运维
3.5.1 赤骥
赤骥是阿里云存储服务的管控平台,面向开发、运维、运营等内部用户,目前已经介入对象存储、文件存储、表格存储、日志服务和函数计算五大产品,提供实时数据监控、智能运维管理、秒级的响应报警、安全审计保障等功能,致力于用精准、高效、智能的管控系统为产品运行保驾护航。
为了更好的管控 OSS 可用性指标,赤骥从问题的发现、定位、恢复三个纬度,按照监控报警、分析诊断、问题解决分解设计,提高运维能力。同时,赤骥提供了月度 SLA 管理功能,监控月度 SLA 不达标名单以及不达标原因,从而支撑 SLA 的不断优化。
3.5.2 OSS brain
OSSBrain 是智能运维平台,它的目标和使命是用数据+算法来保障OSS稳定运行,赋能线上运维及运营。它通过分析线上数据,提供智能决策,包括机器隔离、线上主动预警、用户画像、异常检测、资源调度、用户隔离等。通过快速敏捷的智能运维、快速的隔离错误,从而提高可用性。
3.6 高可用解决方案
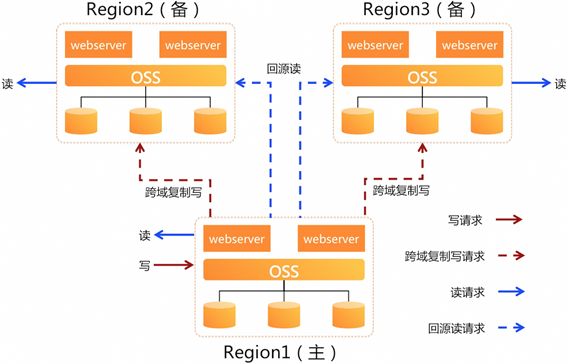
OSS是区域级服务,区域故障将会导致服务不可用,为了提供更高的业务可用性,OSS 提供了异地多活架构的高可用解决方案,如下所示。
写入时只写主区域,开发便捷。利用 OSS 跨区域复制能力,将数据复制到备区域,从而备区域有全量的数据。
读取时可根据地域就近读取,降低延迟。由于写入时只写数据到主区域,数据是异步复制到备区域,所以用户读备区域数据时,可能数据还未复制完成,此时可通过 OSS 镜像回源功能从主区域读取数据。
从而,可在不同的区域级故障场景时,实现快速切换,提供容灾秒级 RPO(Recovery Point Objective),保证业务应用连续性。
备区域不可用,上层业务快速切换到另外 2 个区域,并将流量均分,业务能立即恢复,切换也非常方便。
主区域不可用,则选择新的主区域(如选择区域2),并开通区域2到区域3的跨域复制,从而业务可以将写请求切换到新的主区域,读请求也切换到剩下的区域;同时,基于OSS 的版本控制 和 业务无更新写,实现了主区域故障切换的数据一致性。
3.7 管理机制
除了上述的各种技术保障外,还有如下的管理机制来提升可用性。
库存管理。公共云服务是重资产模式,需要自己管理供应链库存,智能预测资源需求,按需提供服务是可用性的基本保证。
水位管理。对象存储是云存储服务,监控容量水位、带宽水位、QPS 等水位能力,进行动态的智能调度,可以优化系统的可用性。
稳定性文化。从开发、设计、测试、运维等环节制定稳定性制度,追求卓越的可用性能力。
双十一锤炼和百万级用户打磨。OSS 长期参与阿里集群双十一业务支撑,在业务洪峰的不断锤炼下,持续淬炼产品的架构、特性、稳定性。在阿里云的公共云服务体系下,有百万级用户的打磨,支撑各行各业的负载。经年累月的技术积累,总结了持续提升可用性的机制。
4. OSS可用性未来工作
尽管OSS 将可用性 SLA 提升 10 倍,但是技术无止境,未来将在升级异常、超级热点、高频攻击等场景下继续优化可用性。
END

往期精彩文章回顾

帮您管好云:阿里云混合云管理平台发布
阿里云蒋江伟:我们致力于为世界提供70%的算力
搭载敏捷飞天底座 阿里云专有云敏捷版全面升级
性能飙升160%!阿里云发布第七代ECS、云原生数据库PolarDB-X等重磅新品
不能错过!CIO不可不知的“数据经济学”
重磅发布!阿里云混合云:全栈建云、智能管云、极致用云
IT人的地摊不就是开源么
云计算摆摊的可行性分析
eBPF Internal: Instructions and Runtime
啥是数据湖?老子(zǐ)告诉你

长按扫描二维码关注凌云时刻
每日收获前沿技术与科技洞见