The Direct3D 11 Graphics Pipeline
Direct3D 11图形管线
个人电脑一般都有两个处理器:CPU和GPU,你需要对每一个处理器编写代码。这两个部件拥有完全不同的架构和指令集。在图形编程中,你需要对两个处理器都都编写软件,对于CPU应用程序使用通用的语言,比如C++,对于GPU则使用HLSL。DirectX是系统之间的桥梁。大部分关于图形编程的文章都集中讲述CPU部分或者GPU部分,但是这两部分都是非常难懂的。本书两个部分都会讲解。
在DirectX里面我们主要学习Direct3D。简单来说,Direct3D是用于绘制3D图形的系统,定义了一连串步骤用于把图形展示到显示器上。这些步骤被称为Direct3D图形管线(如图1.1)。如图所示,这些箭头指示了数据从一个阶段流向下一个阶段。跨越图右边的大矩形指定了显存里面的资源,双向箭头指明了某个阶段和资源之间的可以读写。可编程(使用HLSL)阶段使用圆角矩形表示。下面详细讲述管线的每一个阶段。
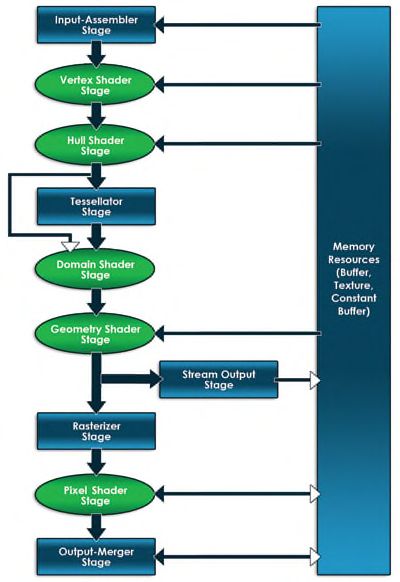
图1.1 The Direct3D 11 graphics pipeline。
The Input-Assembler Stage(IA)
The input-assembler 阶段是图形管线的入口点,在些阶段提供你想要渲染的objects的vertex和index数据。IA 阶段把这些数据组装成primitives(比如点,线,三角形)并将相就的输出发送到Vertex Shader阶段。那究竟什么是Vertex?
Vertex Buffers
一个Vertex至少是三维空间中的一个点。比如在一条线段中,单个的Vertex是线段的一个端点:对如三角形则是三个点中的一个(如图1.2)。但是我说一个Vertex至少是一点,因为Vertex并不仅仅只是一个坐标点。一个Vertex可能包含了Color,Normal(对于光照计算很有用),Texture coordinates,甚至更多。所有这些数据通过Vertex buffer应用于input-assembler阶段。除了坐标位置,Direct3D允许程序员完全自己定义一种vertex。你可以定义你自己的Vertices所包含的数据,并通过input layout告诉Direct3D该vertex格式。第三部分,“Rendering with DirectX“,描述了怎么调用API设置Vertex buffers和input layout;你现在只需要知道这些专业术语即可。
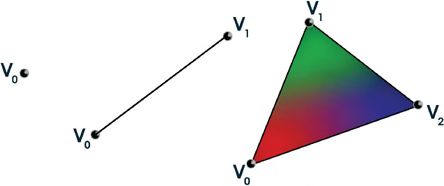
图1.2 3D primitives:point(左边),line(中间),triangle(right)。
Index Buffers
Index buffers是输送到IA阶段的第二种(可选的)数据类型。Indices标识了Vertex buffer中的一些特定vertices,并用于减少可重用vertices的重复。如下图所示,你想到渲染一个矩形(更普遍的说,一个四边形)。一个四边形最少可以用四个vertices来定义。但是,Direct3D并不支持把四边形作为一种primitive(而且也不需要,因为所有的多边形都可以分解成多个三角形)。为了渲染四边形,可以把它分成两个三角形,每一个都有三个vertices(如图1.3)。现在vertices由4个变成了6个,包括两个重复的vertices。使用index buffer,可以在vertex buffer中指定4个唯一的vertices(而不是6个vertices)和6个indices。
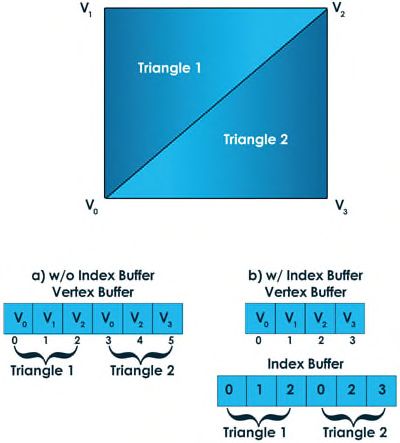
图1.3 Vertices and indices for a 3D quadrilateral
你现在可能会想,”增加一个index buffer怎么减少数据的总大小?”比如,如果你的vertex数据仅由一个3D坐标点(x,y,z)组成,每个部分都是一个32位的浮点数(每个部分4 bytes),那么每个vertex就是12 bytes。没有index buffer的情况下,vertex buffer包含的数据大小为72 bytes(6 vertices * 12 bytes/vertex = 72 bytes)。加上index buffer的情况下,vertex buffer变成了48 bytes(4 vertices * 12 bytes/vertex)。如果indices使用16位的整型数,那么index buffer总共包含12 bytes(6 indices*2 bytes/index = 12 bytes)。把vertex和index buffers的总大小加起来就是60 bytes(48-byte vertex buffer + 12-byte index buffer)。你可能觉得并没有减少多少内存。但考虑到传输额外的vertex data-可能是16-byte color,12-byte normal,以及8 bytes of texture coordinates。那么在两个三角形之间每一个共享的vertex都可以节省36 bytes的额外空间。当加载拥有成千上万个vertices的meshed时这种节省会更多。此外,你不仅仅只考虑内存,你同样需要考虑CPU和GPU之间的总线。你所使用数据的每一个bit都要从图形总线(比如PCI Express)上从应用层传输到显卡上。这种总线传输很慢(相对CPU到RAM或者GPU到VRAM),因为减少传输的数据量是非常重要的。
Primitive Types
当你提供一个vertex buffer至input-assembler阶段,必须定义这些vertices的topology,这是管线用来解析vertices的方式。Direct3D支持以下几种基本的primitive类型:
Point list
Line list
Line strip
Triangle list
Triangle strip
Point list是一系列无联系,被独立渲染的点的集合。相反,Line list把一对点连接成线段。但是这些线段并没有连接成Line strip。另外,Line strip 并不是由一对对的vertices,而是一种点连接的序列。图1.4阐述了这些topologies。

图1.4 Point list(左),line list(中),以及line strip(右)。
Triangle list是我们将要使用的最普遍的一种topology。在Triangle list模式下,每组三个verteices被解释成一个独立的triangle。任何共用的vertices都是重复的(与我们讨论的index buffers不同)。相比之下,Triangle strip把vertices解释成一系列连接的triangles,在这个种模式下,共用的vertices不重复。图1.5描述了这两种topologies。
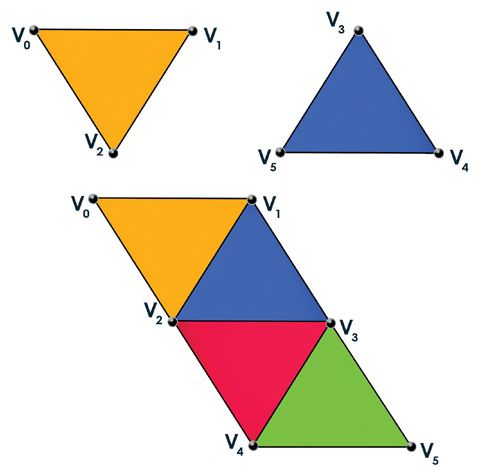
图1.5 Triangle list(上图)和 triangle strip(下图)。
Triangle Strip Vertex Winding Order
注意,对于图1.5中描述的Triangle strip,vertices的编号并没有明确每组的3个vertices怎么渲染。在图中,总共6个vertices构成了4个triangles。Direct3D以如下的次序绘制triangles:
Triangle 1:V0,V1,V2
Triangle 2:V1,V3,V2
Triangle 3:V2,V3,V4
Triangle 4:V3,V5,V4
直观的说,你可能会以数字升序排列的方法分组vertices,但Direct3D并不这么做,因为按数字排序的triangles会变成无序的。Direct3D以顺时针方向绕着triangles可以帮助处理背面消除。第二部分,“Shader Authoring with HLSL“,将会讨论这些。Primitives with Adjacency
从DirectX 10版本开始,Direct3D支持包含邻接数据的primitives。对于这种primitives,不仅需要专门用于基本primitive的vertices,还需要用于包围基本primitive的邻接vertices。图1.6描述了这个概念。
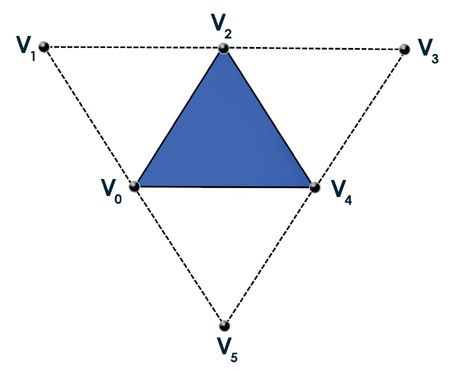
图1.6 Triangle list with adjacency
Control Point Patch Lists
Direct3D 11增加了control point path lists,用于支持使用管线的Tessellation阶段。我们将于第21章,“Geometry and Tessellation Shaders“,讨论path lists。
The Vertex Shader Stage(VS)
Vertex shader 阶段处理通过input-assemeble阶段解释的primitives。这种处理基于每一个vertex。这是管线里面第一个可编程阶段。事实上,一个vertex shader总是需要在Vertex shaderb阶段提供。那到底什么是shader呢?
Shader是一段小的程序(你也可以称之为一个函数)由你编写并由GPU执行。Vertex shader对每一个传递到管线的vertex起作用(这是shader的输入),执行一系列指令并把输出传送到下一个活动的阶段。正如前面提到的,vertex shader的输入vertex至少是一个坐标点。一般来说,vertex shader以某种方式变换vertex,并输出经过修改的或重新计算的数据。列表1.1列出了可能是我们能创建出的最简单的vertex shader。
列表1.1 Your First Vertex Shader
float4 vertex_shader(float3 objectPosition : POSITION) : SV_Position
{
return mul(float4(objectPosition, 1), WorldViewProjection);
}注意:你觉得简单吗?不要对这个vertex shader的语法有任何压力。作为一名C/C++程序员,这个应该看起来像一个函数,但是显然这里面混合了一些特别的东西。我们将于第二部分学习这些语法。
Tessellation Stages
作为Direct3D 11的一个新性,硬件Tessellation是一个直接在GPU上给objects增加细节的过程。一般来说,更多的几何细节(更多的vertices)会产生更真实的渲染效果。如图1.7所示。该图片显示了一个在不同级别细节下的3D模型,低,中,高三个级别的细节(LODs)。传统上,LODs由艺术家创造,特定的LODs是基于object到camera的距离来渲染的。

图1.7 A 3D model with low, medium, and high levels of detail(LODs)。
注意:不需要渲染离观察者很远的高分辨率object,因为所有增加的细节都会丢失。你可以根据object的距离一致的选择细节的级别,距离越远,细节的级别越低。
vertex shaders要处理的确vertices越少,渲染的速度越快。
在一个传统的LOD系统口目,模型都是有固定的细节数量(也限多边形数量)。硬件Tessellation让你能够动态细分一个object,并且不会增加传输给input-assembler阶段的额外几何图元的成本。这便允许一个动态的LOD系统,以及更少的使用显卡总线(都是有利的)。在Direct3D 11 中,下面这三个阶段与Tessellation阶段保持一致:
The hull shader 阶段(HS)
The tessellator 阶段
The domain shader 阶段(DS)
Hull shader和domain shader阶段都是可编程的;tessellator阶段是不可编程的。在第21章包含tessellation主题的更多细节。
The Geometry Shader Stage (GS)
vertex shaders只处理单个vertices,与此不同的是,geometry shaders处理完整的primitives(比如points,points,lines,以及triangles)。此外,geometry shaders还可以从管线里面增加或删除几何图元。这种特性可以做出一些非常有趣的应用。例如,你可以创建一个particle effects system(粒子效果系统),这时单个的vertex就代表每一个particle(粒子)。在geometry shader阶段,可以围绕中心点创建四边形,并进行纹理映射。这种objects一般被称为point sprites(点精灵)。
与GS阶段相连的是stream-output(SO)阶段。在此阶段,vertices里的数据流从geometry shader输出并存储到内存中。在multipass rendering(多道渲染)的情况下,这些数据可以在随后的通道中读回到管线,或者CPU读取。相对于tessellation阶段,geometry shader阶段是可选的。在第四部分,“Intermediate-Level Rendering Topics”,将讨论geometry shaders和multipass rendering更多的细节。
与GS阶段相连的是stream-output(SO)阶段。在此阶段,vertices里的数据流从geometry shader输出并存储到内存中。在multipass rendering(多道渲染)的情况下,这些数据可以在随后的通道中读回到管线,或者CPU读取。相对于tessellation阶段,geometry shader阶段是可选的。在第四部分,“Intermediate-Level Rendering Topics”,将讨论geometry shaders和multipass rendering更多的细节。
The Rasterizer Stage (RS)
到当前所处的管线阶段,我们主要讨论vertices以及由vertices组合成primitives的说明。Rasterizer阶段把这些primitives转化一张光栅化图片,也被称为bitmap。一个光栅图像以像素(颜色)的二维数组表示,通常构成计算机屏幕的某些区域。
Rasterizer阶段定义了像素应该怎样渲染,以及怎么把这些像素传送到Pixel shader阶段。在像素进行渲染的同时,rasterizer在每个primitive之间传输每一个vertex进行插值。例如,一个triangle primitive有三个vertices,每个vertex至少包括一个坐标点还可能带有color, normal, texture coordinates的数据。该vertex数据用于光栅化计算两个像素之间的插值。图1.8说明了vertex colors的概念。图中triangle的三个点被分别赋值了红,绿,蓝的vertex color。注意triangle中的像素相对相近的三个vertices是如何变化的。正是rasterizer阶段产生了就些插值的colors。
Rasterizer阶段定义了像素应该怎样渲染,以及怎么把这些像素传送到Pixel shader阶段。在像素进行渲染的同时,rasterizer在每个primitive之间传输每一个vertex进行插值。例如,一个triangle primitive有三个vertices,每个vertex至少包括一个坐标点还可能带有color, normal, texture coordinates的数据。该vertex数据用于光栅化计算两个像素之间的插值。图1.8说明了vertex colors的概念。图中triangle的三个点被分别赋值了红,绿,蓝的vertex color。注意triangle中的像素相对相近的三个vertices是如何变化的。正是rasterizer阶段产生了就些插值的colors。

图1.8 Rasterizer interpolation for a triangle with red,green,and blue colors specified for the three vertices。
The Pixel Shader Stage (PS)
仅管从技术上来说pixel shader阶段是可选的,但是你还是需要提供一个pixel shader。这个阶段对rasterizer阶段输入的每个像素都执行shader代码,并输出color值。这允许程序员控制每一个渲染到屏幕上的像素。Pixel shader使用每个经过插值的vertex数据,全局变量,以及texture数据产生输出数据。列表1.2展示了一个为每个像素输出纯红色的shader代码。
float4 pixel_shader() : SV_Target
{
return float4(1, 0, 0, 1);
}The Output-Merger Stage (OM)
Output-Merger阶段产生最终的渲染像素。此阶段不是可编程的(不能编写shader),但是你需要通过自定义的管线阶段控制他的工作方式。OM阶段通过组合pixel shader阶段的输出数据和render target中已经存在的数据生成最终的像素。这种方式允许通过color blending实现object的透明效果。第8章,“将会讨论blending。
OM阶段还要通过depth testing(深度测试)和stencil testing(模板测试)确定最终渲染时可见的像素。Depth testing根据render target上已经被绘制的数据来确定当前的像素是否需要绘制。请看图1.9,一些objects离camera的距离比其他的objects近,但是都有着相关的屏幕空间。这些objects遮挡了在他们后面objects的全部或部分。Depth testing 根据object和camera之间的距离相应的绘制像素到render target。一般情况下,如果render target上已经有的像素比当前像素到camera的距离更近,当前像素就被丢弃(不会写到render target)。
OM阶段还要通过depth testing(深度测试)和stencil testing(模板测试)确定最终渲染时可见的像素。Depth testing根据render target上已经被绘制的数据来确定当前的像素是否需要绘制。请看图1.9,一些objects离camera的距离比其他的objects近,但是都有着相关的屏幕空间。这些objects遮挡了在他们后面objects的全部或部分。Depth testing 根据object和camera之间的距离相应的绘制像素到render target。一般情况下,如果render target上已经有的像素比当前像素到camera的距离更近,当前像素就被丢弃(不会写到render target)。
Stecil testing使用一个mask(掩模)来确定更新哪个像素。这在概念上类似于在纸片上或塑料板上绘画,或在一个物理平面上打印图案。在第三部分,“Rendering with DirectX”将会详细讲述depth和stencil testing。
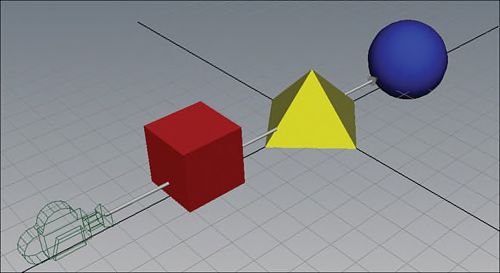
图1.9 A scene illustrating depth testing, with some objects occluding others。
注意:
Rasterizer阶段也会使用另一种称为Clipping(裁剪)的过程确定哪些像素会渲染到屏幕上。Rasterizer阶段确定为不会显示到屏幕上的像素不会被发送到pixel shader阶段,并且在管线的以后操作阶段被丢弃。
Rasterizer阶段也会使用另一种称为Clipping(裁剪)的过程确定哪些像素会渲染到屏幕上。Rasterizer阶段确定为不会显示到屏幕上的像素不会被发送到pixel shader阶段,并且在管线的以后操作阶段被丢弃。
Summary
在本章,你知道了DirectX是一组API,涉及一系列游戏相关的主题,包括2D和3D渲染,输入,声音,以及通用的GPU编程。DirectX从90年代中期一直在不断发展,至今已经是经过重大修改的DirectX 11版本。本章概述了Direct3D的图形管线,从input-assembler阶段一直到output-merger阶段。介绍了vertex和index buffer,primitive topologies,vertex和pixel shaders以及tessellation。
这只是刚开始,接下来的章节将会更深入的讨论这些主题。
这只是刚开始,接下来的章节将会更深入的讨论这些主题。