【笔记4-1】近期论文笔记--基于常识的问答数据集CommonsenseQA
COMMONSENSEQA: A Question Answering Challenge Targeting Commonsense Knowledge
- (一)论文概述
- (二)相关研究
- (三)数据集生成
- (1)CONCEPTNET提取过程
- (2)众包问题
- (3)增加额外的干扰项
- (4)验证问题质量
- (5)添加上下文
- (四)数据集分析
- CONCEPTNET中的概念和关系
- 题目的形成
- 常识技能
- (五)Baseline model
- (六)实验结果
- (七)总结
COMMONSENSEQA: A Question Answering Challenge Targeting Commonsense Knowledge (Alon Talmor, Jonathan Herzig, Nicholas Lourie, Jonathan Berant)
论文:https://arxiv.org/pdf/1811.00937.pdf
数据集:www.tau-nlp.org/commonsenseqa
Baseline model:github.com/jonathanherzig/commonsenseqa
(一)论文概述
数据集提出的动机:当人们回答问题时,往往会利用自身了解的知识结合特定的背景。但目前的机器阅读理解集中在回答一些文章内容相关的问题,不需要一般知识背景。于是,为了研究基于先验知识的问答,作者提出了COMMONSENSEQA,一个用于常识性问答的新数据集。
为了获取超出关联之外的常识,作者从CONCEPTNET (Speer et al., 2017)中提取了与单个源概念具有相同语义关系的多个目标概念。群体工作者被要求写单项选择题,其中包含源概念,并依次区分每个目标概念。这鼓励工作人员创建具有复杂语义的问题,这些问题通常需要先验知识。数据生成过程概括如下图,之后会在第三部分对这一过程进行详细介绍。
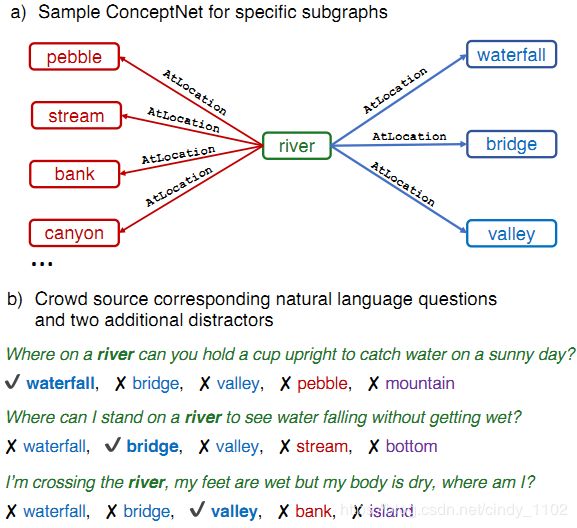
通过这个过程,共创建了12247个问题,并用大量的baseline model说明了这一任务的难度。最好的baseline是基于BERT-large的模型 (Devlin et al., 2018),获得56%的准确率,远低于人类89%的表现。
该论文的贡献如下:
- 提出一个新的以常识为中心的QA数据集,包含12247个示例。
- 提出一种从概念网生成大规模常识性问题的新方法。
- 在COMMONSENSEQA上对最先进的NLU模型进行的实证评估,结果表明人类的表现远远超过当前的模型。
(二)相关研究
机器常识是关于开放世界的知识和推理能力,被认为是自然语言理解的关键组成部分。尽管有过很多相关研究,但是探究机器的常识理解能力依旧较为困难。
相关研究:
- 寻找能用自然语言解释环境的程序(McCarthy, 1959)
- 利用世界模型加深对语言的理解(Winograd, 1972)
- 常识性表征和推理程序(麦卡锡和海斯,1969;Kowalski和Sergot, 1986)
- 大规模常识知识库(Lenat, 1995;Speer等,2017)
- 要求正确解决指代消解实例对, Winograd Schema Challenge (Levesque, 2011)
- COPA(Choice of Plausible Alternatives)500个开发500个测试问题。问两个选项中哪一个最能反映与前提相关的因果关系 (Roemmele et al., 2011)
- JHU Ordinal Commonsense Inference要求一个1-5的标签,表示一种情况可能导致另一种情况(Zhang et al., 2017)
- Story Cloze Test(也称为ROC Stories)将故事真实结尾与难以置信的假结尾进行对比(Mostafazadeh et al., 2016)
- SWAG 选择对初始事件之后发生的事情的正确描述(Zellers et al., 2018b)。
- 预先训练的LM在目标任务上微调,在Story Cloze Test和SWAG上实现了非常高的性能(Radford等,2018;Devlin等,2018)
(三)数据集生成
该数据集生成的一个重点是开发一种生成问题的方法,这些问题可以在没有上下文的情况下由人类轻松回答,且需要常识。生成选择题的过程概括如下:
- 从CONCEPTNET中提取子图,每个子图有一个源概念和三个目标概念。
- 要求众包工作者为每个子图编写三个问题(每个目标概念一个),为每个问题添加两个额外的干扰因素,并验证问题的质量。
- 通过查询搜索引擎和检索web片段为每个问题添加上下文。

更具体地说,各个步骤的实现如下:
(1)CONCEPTNET提取过程
CONCEPTNET是一个图形知识库 G ⊆ C × R × C G\subseteq C\times R\times C G⊆C×R×C,其中节点C表示自然语言概念,边R表示常识关系。三元组 ( c 1 , r , c 2 ) (c_1,r,c_2) (c1,r,c2)包含常识,如(gambler, CapableOf, lose money)CONCEPTNET包含3200万个三元组。为了选择三元组的一个子集进行众包,采取以下步骤:
- 使用一般关系(例如,RelatedTo)或NLP中已经很好地研究过的关系(例如,IsA)过滤三元组。共使用22种关系。
- 过滤其中一个概念超过四个单词或不是英语的三元组。
- 当 c 1 , c 2 c_1,c_2 c1,c2之间的距离过低时,去掉该三元组。
最终选出来236208个三元组 ( q , r , a ) (q,r,a) (q,r,a),称第一个概念为问题概念,第二个为答案概念。目标是生成包含问题概念的问题,其答案就是答案概念。
要创建单选题,需要为问题创建干扰项。如果直接从CONCEPTNET中随机抽取作为干扰项,使用简单的表面线索很容易消除这类干扰。为了解决这个问题,创建问题集:对于每个问题概念q和关系r,选择三个不同的三元组 { ( q , r , a 1 ) , ( q , r , a 2 ) , ( q , r , a 3 ) } \{(q,r,a_1),(q,r,a_2),(q,r,a_3)\} {(q,r,a1),(q,r,a2),(q,r,a3)}即下图中的蓝色部分。
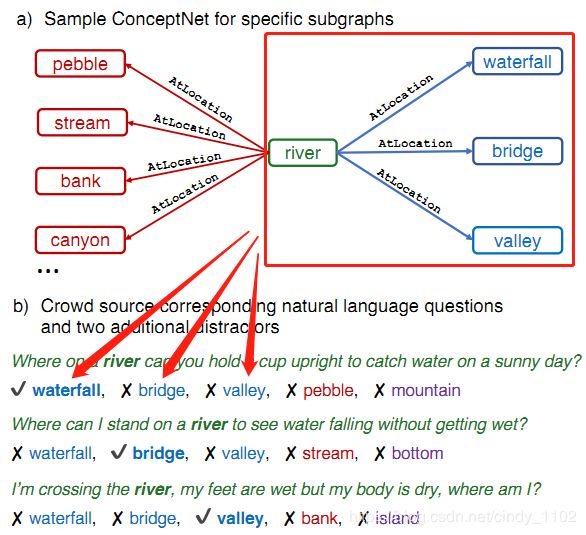
这将生成三个语义相似且与问题概念q有类似关系的回答概念,促使工作人员制定需要概念背景知识才能回答的问题。这个过程生成了大约130,000个三元组(43,000个问题集),可以为它们生成潜在的问题。
(2)众包问题
使用Amazon Mechanical Turk (AMT)的员工来生成和验证常识问题。AMT工作人员看到的是:每个问题集对应的问题概念和三个回答概念。
他们被要求制定三个问题,所有的问题都包含问题概念,每个问题都应该有且仅有一个答案。不鼓励员工提供简单的答案线索,他们被告知要避免使用与答案概念有密切联系的词,例如,答案是“door”时不要使用“open”这个词。为这一任务制定问题并非易事。因此只接受至少75%的问题通过了验证过程的注解者。
(3)增加额外的干扰项
为了使任务更加困难,为每个问题添加两个额外的错误答案。从与CONCEPTNET中的问题概念具有相同关系的一组回答概念中选择一个干扰因素(下图红色部分)第二个干扰由工作人员自己制定(下图紫色部分)工作人员被鼓励制定一个似乎合理的或与问题相关的干扰因素,但这一干扰很容易被人类认为是不正确的。因此最终每个问题都有五个备选答案,包括一个正确答案和四个干扰项。
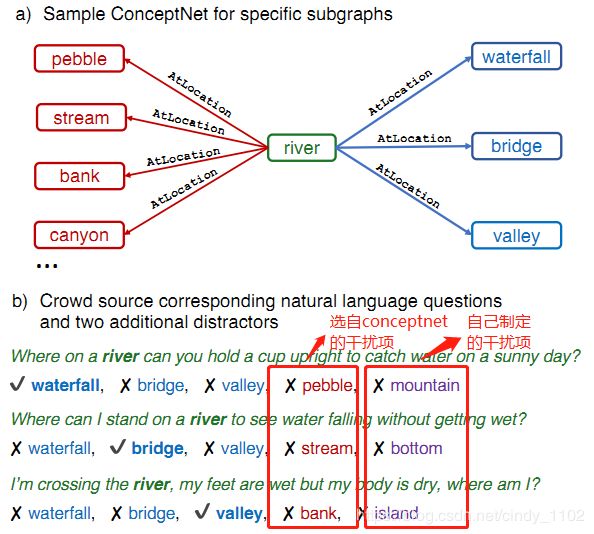
(4)验证问题质量
培训一组与前述工人不重合的工人来验证生成的问题。验证者将一个问题标注为无法回答,或者选择正确的答案。每个问题由2名工作人员验证,并且只使用由至少一名正确回答的工作人员验证的问题。这个过程会过滤掉15%的问题。
(5)添加上下文
检查web文本对于解决常识性问题是否有用,用以下方法将文本信息添加到每个问题:发出一个web搜索每一个问题及其候选回答,比如 ‘What does a parent tell their child to do after they’ve played with a lot of toys? +“clean room”’。为五个候选答案中的每一个取前100个结果片段,每个问题产生一个包含500个片段的上下文。在此背景下,可以研究阅读理解(RC)模型在COMMONSENSEQA上的表现。
最终收集的数据概述如下:

(四)数据集分析
CONCEPTNET中的概念和关系
COMMONSENSEQA建立在CONCEPTNET上,包含dog, house, row boat之类的概念,概念之间由Causes,CapableOf,Antonym等关系连接。Person(3.1%) People(2.0%) Human(0.7%) Water(0.5%) Cat(0.5%)是最常见的5个问题概念。下表给出了主要关系以及由此产生的问题的百分比。

题目的形成
提问者被要求创造具有高度语言变异的题目。122个提问者参与问题构造,而超过85%的问题由10名工人提出。下图分析了命题中第一、二词的分布情况。只有44%的第一个单词是wh类单词。在大约5%的问题中,提问者使用名字来创造一个上下文故事,7%使用“如果”来提出一个假设问题。这表明问题语言的高度可变性。
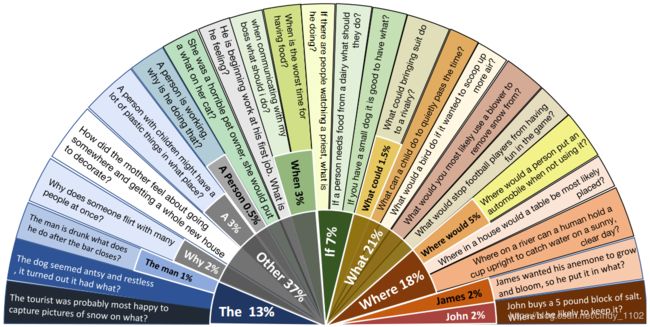
常识技能
为了分析COMMONSENSEQA所需的常识类型,从开发集中抽取100个例子进行分析。每个问题都标注了用于回答问题的常识技能的类型。允许每个问题有多个常识性技能,平均每个问题有1.75个技能。下图提供了三个示例,每个注释包含一个回答概念节点,以及出现在问题或潜在概念中的节点。关系边上的标签表示连接两个节点的常识技能。
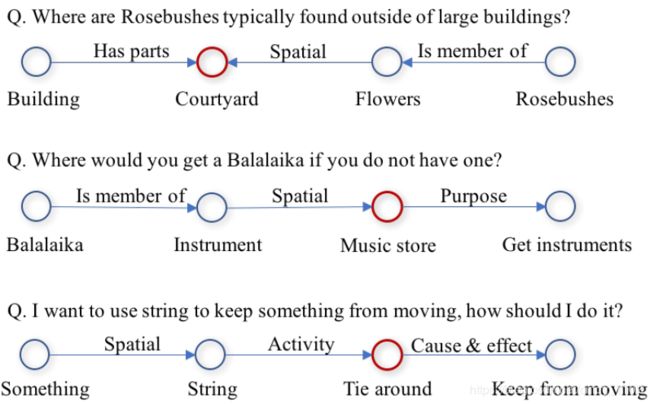
基于LoBue和Yates(2011)的分析,定义常识技能,并对数据中的现象进行轻微修改。下表给出了技能类别、定义以及在分析示例中的出现频率。

(五)Baseline model
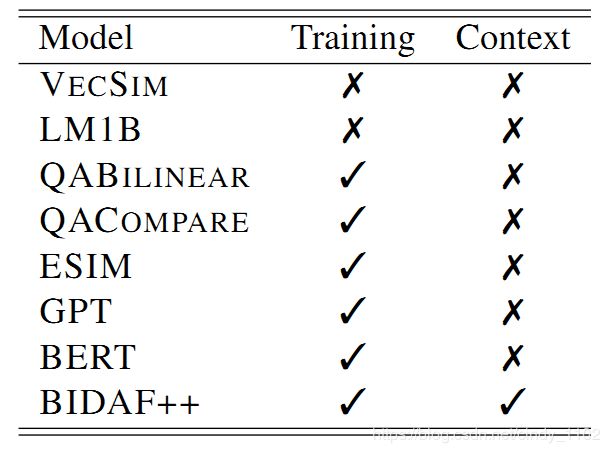
作者的目标是收集一个常识性问题的数据集,问题对于人类来说很容易,但对于当前的NLU模型来说却很难。为了评估这一点,使用多个基线进行了实验。下表总结了各种基线类型,并根据以下标准分类:(a)是否基于COMMONSENSEQA完成了训练或模型进行了充分的预训练,(b)是否使用了上下文。
- VECSIM:选择与问题余弦相似度最高的答案,其中问题和答案由预先训练的词嵌入的平均值表示。
- LM1B:采用Jozefowicz等人(2016)的大型语言模型(LM)。使用模型的两种变体,在(LM1B-CONCAT)中,将每个答案连接起来。在(LM1B-REP)中,先根据问题的前两个单词对问题聚类。然后识别出覆盖开发集35%的五个高频前缀(如“what is”)。将符合其中一个前缀的问题重新措辞为包含答案的陈述句。如把问题“What is usually next to a door?”和应试者的回答“wall”改写成“Wall is usually next to a door”。不以上述前缀开头的问题按LM1B-CONCAT将答案连接起来。两种情况都以LM概率最大的方式返回答案。
- QABilinear :使用双线性模型 q W a i T qWa_i^T qWaiT 对答案 a i a_i ai 进行评分,其中q和 a i a_i ai为平均预训练词嵌入量,W为学习参数矩阵。利用候选答案上的softmax层训练具有交叉熵损失的模型。
- QACompare:问题q与候选答案 a i a_i ai 之间的交互为 h = r e l u ( [ q ; a i ; q ⨀ a i ; q − a i ] W 1 + b 1 ) h = relu([q;a_i;q\bigodot a_i;q-a_i]W_1 + b_1) h=relu([q;ai;q⨀ai;q−ai]W1+b1)。然后,使用前馈层 h W 2 + b 2 hW_2 + b_2 hW2+b2 预测答案得分。采用平均预训练词嵌入和softmax对模型进行训练。
- ESIM:一个强大的NLI模型(Chen et al., 2016)。将输出层的大小改为候选答案的数量,并应用softmax进行交叉熵损失训练。
- BIDAF++:使用检索到的谷歌web作为上下文。在原模型基础上使用自注意力和ELMo。选择概率最高的答案。
- GPT:预训练LM用于执行广泛的任务。将该模型应用到COMMONSENSEQA,将每个问题及其候选答案编码为一系列分隔符分隔的序列。如问题If you needed a lamp to do your work, where would you put it?,应试者的回答bedroom,变为[start] If … ? [sep] bedroom [end]。每个[end]上的隐藏表示通过线性变换转换为logits,通过softmax生成最终答案概率。使用预训练LM和超参数进行微调,batch size=10。
- Bert:使用一个mask语言建模目标,目标是预测未标记文本中mask的单词。将每个问题-答案对线性化为分隔符分隔的序列 “[CLS] If … ? [SEP] bedroom [SEP]” 然后微调预训练bert-large的权重。每个[CLS]的隐藏表示通过softmax层创建预测。
(六)实验结果
各个baseline model的实验结果:
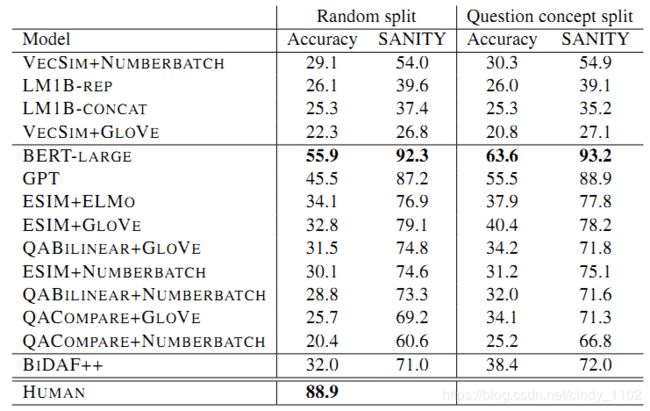
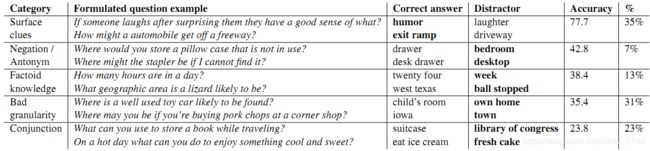
Bert-large的结果分析:
(七)总结
该文章介绍了一个新的QA数据集COMMONSENSEQA,包含12247个示例,旨在测试常识知识。文章描述了使用CONCEPTNET大规模生成困难问题的过程,对数据集进行了详细的分析,说明了数据集的独特性,并在一组强大的baseline model上进行了广泛的评估。最好的模型是针对任务进行调优的预训练LM,精度为55.9%,比人工精度低几十个点。这个数据集有望帮助常识性知识在NLU系统中的集成。