我以前还没接触Redis的时候,听到大数据组的小伙伴在讨论Redis,觉得这东西好高端,要是哪天我们组也可以使用下Redis就好了,好长一段时间后,我们项目中终于引入了Redis这个技术,我用了几下,感觉Redis也就那么回事啊,不就是get set吗?当我又知道Redis还有自增、自减操作,而且这些操作还是原子性的,秒杀就可以用这个技术,我就觉得我已经熟悉Redis了。相信有不少curd boy是和以前的我一个想法:Redis不就是get set increment吗?其实不然,Redis远远没有我们想象中的那么简单,今天我就在此献丑来谈谈Redis。
关于Redis是什么,如何安装等问题就不阐述了,我们直接进入正题吧。
Redis五种数据类型及应用场景
Redis有五种数据类型,即 string,list,hash,set,zset(sort set),我想这点只要稍微对Redis有点了解的小伙伴都应该清楚。下面,我们就来讨论下这五种数据类型的应用场景。
string
这个类型相信是大家最熟悉的了,但是千万不要小瞧它,它可以做很多事情,也可以牵出一系列的问题。
我们先从最简单的入手:
localhost:6379> set coderbear hello
OK
localhost:6379> get codebear
"hello"
这两个命令相信大家都知道,我就不解释了,我们再来用下strlen这个命令:
localhost:6379> strlen codebear
(integer) 5
哦,我明白了strlen这个命令可以获得Value的长度啊,hello的长度是5,所以输出就是5。这个解释对不对呢?不着急,我们慢慢往下看。
我们使用append命令为codebear这个key追加点东西:
APPEND codebear 中国
如果我们再次使用strlen命令会输出什么呢?当然是7啊,虽然我数学不好,但是10以内的数数,我还是no problem的,但是当我们再次执行strlen命令,你会发现一个奇怪的现象:
localhost:6379> strlen codebear
(integer) 11
纳尼,为什么是11,是不是我们的打开方式不对,要不再试下?不用了,就算再试上三生三世,你看到的输出还是11。这是为什么呢?这就牵扯到二进制安全问题了。
二进制安全
所谓的二进制安全就是只会严格的按照二进制的数据存取,不会妄图以某种特殊格式解析数据。Redis就是二进制安全的,它存取的永远是二进制数据,也可以说存取的永远是字节数组。
我们来get下codebear康康:
get codebear
"hello\xe4\xb8\xad\xe5\x9b\xbd"
你会发现好端端的"hello中国",存储到Redis竟然变成这样了,因为我们的Xshell客户端使用的是UTF-8,在UTF-8下,一个中文通常是三个字节,两个中文就是6个字节,所以在Redis内部"hello中国"占了5+6=11个字节。
如果你还不信,我们把Xshell的编码改成GBK看看,在GBK的世界里,一个中文通常占两个字节,所以:
localhost:6379> set codebeargbk 中国
OK
localhost:6379> get codebeargbk
"\xd6\xd0\xb9\xfa"
localhost:6379> strlen codebeargbk
(integer) 4
所以说,醒醒吧,小伙计,在Redis里面是不可能存中文的,我们之所以在程序里面可以轻轻松松的拿到中文,只是因为API做了解码的操作。
没想到一个String还牵出二进制安全的问题,看来真是不能小瞧任何一个知识点啊,这也就是常说的搜索地狱,当你查找一个问题,发现这个问题的答案又出现了一个你不懂的东西,于是你又开始看那个你不懂的东西,然后又冒出另外一个你不懂的概念,于是...说多了都是泪啊。
我们经常用Redis做缓存,用到的就是set get这两个命令了,我们还可以用Redis做秒杀系统,在绝大部分情况下,用的也是String这个数据类型,让我们继续往下看:
localhost:6379> set codebearint 5
OK
localhost:6379> incr codebearint
(integer) 6
也许你没用过incr命令,但是可以从结果和命令名称猜出incr这个命令是干嘛的把,没错,就是自增,既然有自增,还可以做自减:
localhost:6379> decr codebearint
(integer) 5
刚才是6,调用了decr 命令后,又变成5了。
好了,又有一个问题,String是字符串啊,它怎么可以做加法或减法的操作?
我们用type命令来检查下codebearint 这个key的类型是什么:
localhost:6379> type codebearint
string
没错,是如假包换的String类型啊。
我们再来看一个东西:
localhost:6379> object encoding codebear
"raw"
localhost:6379> object encoding codebearint
"int"
原来在Redis的内部还会为这个key打上一个标记,来标记它是什么类型的(这个类型可和Redis的五种数据类型不一样哦)。
bitmap
有这么一个需求:统计指定用户一年之中登录的天数?这还不简单,我建个登录表,不就可以了吗?没错,确实可以,但是这代价是不是有点高,如果有100万个用户,那么这登录表要有多大啊。这个时候,bitmap就横空出世了,它简直是解决此类问题的神器。
我们先来看看什么是bitmap,说穿了,就是二进制数组,我们来画一张图说明下:

这就是bitmap了,由许许多多的小格子组成,格子里面只能放1或者0,说的专业点,那一个个小格子就是一个个bit。
String就很好的支持了bitmap,提供了一系列bitmap的命令,让我们来试试:
setbit codebear 3 1
(integer) 0
localhost:6379> get codebear
"\x10"
这是什么意思呢,就是说现在有8个小格子,第四个格子里面放的是1(索引从0开始嘛),其他都是0,就像这样的:
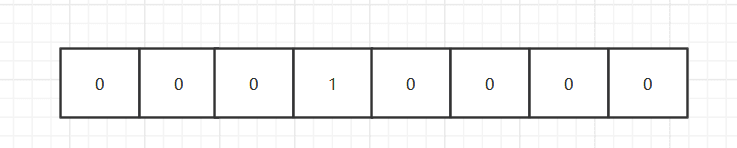
让我们计算下,大小应该是多少,1 2 4 8 16 ,没错,用十进制表示是16,而我们get codebear输出的是“\x10”,“\x”代表是十六进制,也就是16进制的10,16进制的10就是十进制的16了。
我们再用下strlen命令看下:
localhost:6379> strlen codebear
(integer) 1
看来只占据了一个字节,让我们继续:
localhost:6379> setbit codebear 5 1
(integer) 0
bitmap就变成了下面这个酱紫:

大小用十进制表示就是20。
我们继续看下strlen:
localhost:6379> strlen codebear
(integer) 1
还是只占据了一个字节,我们明明已经存储了两个数据了,是不是非常神奇。
让我们继续:
localhost:6379> setbit codebear 15 1
(integer) 0
localhost:6379> strlen codebear
(integer) 2
从这里可以看出bitmap是可以扩展的,由于现在我在第16个格子里面放了1,所以bitmap扩展了,现在strlen是2。
那么我想知道现在16个格子里面有多少格子是1的,怎么办呢?用bitcount命令:
localhost:6379> bitcount codebear
(integer) 3
到了这一步,是不是豁然开朗了,用bitmap可以轻松统计指定用户一年之中登录的天数。
我们假设codebear第一天登录过,第二天登录过,最后一天登录过:
localhost:6379> setbit codebear 0 1
(integer) 0
localhost:6379> setbit codebear 1 1
(integer) 0
localhost:6379> setbit codebear 364 1
(integer) 0
localhost:6379> bitcount codebear
(integer) 3
继续用strlen来看看,记录了全年登录过的日子占据了多少字节:
localhost:6379> strlen codebear
(integer) 46
仅仅46个字节,就算每年都登录,也只占用46个字节,我不知道这样的数据存在数据库应该是多大的,但是我想远远不止46个字节把,如果有100万个用户,也就不到50M,哪怕这100万个用户天天登录占据的字节也是这些。
我们再把上面的需求改下:统计指定用户在任意时间窗口内登录的天数?
bitcount命令后面还可以带两个参数,即 开始 和 结束:
localhost:6379> bitcount codebear 0 2
(integer) 2
我们还可以把第二个参数写成-1,代表直到最后一位,即:
localhost:6379> bitcount codebear 0 -1
(integer) 3
bitmap的强大远远不止这些,我们再来康康第二个需求:统计任意日期内,所有用户登录情况:
- 统计任意一天内登录过的用户
- 统计任意几天内登录过的用户
- 统计任意几天内每天都登录的用户
脑阔疼啊,这特么的是人干的事情吗?别急,这一切都可以用bitmap来实现。
第一个需求,很好实现,假设用户codebear的userId是5,用户小强的userId是10,我们可以建立一个key为日期的bitmap,其中第四个、第九个小格子是1,代表userId是5、userId是1的用户在这一天登录过,然后bitcount下就万事大吉,如下所示:
localhost:6379> setbit 20200301 4 1
(integer) 0
localhost:6379> setbit 20200301 9 1
(integer) 0
localhost:6379> bitcount 20200301
(integer) 2
要实现下面两个需求,得用新的命令了,直接看结果吧:
localhost:6379> setbit 20200229 9 1
(integer) 1
localhost:6379> bitop and andResult 20200301 20200229
(integer) 2
localhost:6379> bitcount andResult
(integer) 1
localhost:6379> bitop or orResult 20200301 20200229
(integer) 2
localhost:6379> bitcount orResult
(integer) 2
下面来解释下,首先又创建了一个key为20200229的bitmap,其中第10个小格子为1,代表用户Id为10的用户在20200229这一天登录过,接下来对key为20200301和20200229的bitmap做与运算,结果也是一个bitmap,并且把结果放入了andResult这个key中,下面就是熟悉的bitcount命令了,康康有多少个小格子为1的,结果是1,也就是这两天,每天都登录的用户有一个。
既然有与运算,那么就有或运算,下面就是或运算的命令,求出了这两天有两位用户登录。
这样后面两个需求就轻松搞定了。
还有大名鼎鼎的布隆过滤器也是用bitmap实现的,关于布隆过滤器在以前的博客也介绍过。
看了那么多的例子,大家有没有发现一个问题,所有的运算都在Redis内部完成,对于这种情况,有一个很高大上的名词:计算向数据移动。与之相对的,把数据从某个地方取出来,然后在外部计算,就叫数据向计算移动。
list
Redis的list底层是一个双向链表,我们先来康康几个命令:
localhost:6379> lpush codebear a b c d e
(integer) 5
localhost:6379> lrange codebear 0 -1
1) "e"
2) "d"
3) "c"
4) "b"
5) "a"
push,我懂,推嘛,但是前面+个l是什么意思呢,前面的l代表左边,lpush就是在左边推,这样第一个推进去的,就是在最右边,lrange是从左开始拿出指定索引范围内的数据,后面的-1就是代表拿到最后一个为止。
既然可以在左边推,那么必须可以在右推啊,我们康康:
localhost:6379> rpush codebear z
(integer) 6
localhost:6379> lrange codebear 0 -1
1) "e"
2) "d"
3) "c"
4) "b"
5) "a"
6) "z"
还有两个弹出命令也很常用,我们来使用下:
localhost:6379> lpop codebear
"e"
localhost:6379> lrange codebear 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
5) "z"
localhost:6379> rpop codebear
"z"
localhost:6379> lrange codebear 0 -1
1) "d"
2) "c"
3) "b"
4) "a"
lpop是弹出左边第一个元素,rpop就是弹出右边第一个元素。
如果我们使用lpush,rpop或者rpush,lpop这样的组合,就是先进先出,就是队列了;如果我们使用lpush,lpop或者rpush,rpop这样的组合,就是先进后出,就是栈了,所以Redis还可以作为消息队列来使用,用到的就是list这个数据类型了。
相信大家一定都玩过论坛,后面发帖的,帖子通常在前面。为了性能,我们可以把帖子的数据放在Redis中的list里面,但是总不能无限往list里面扔数据吧,一般前面几页的帖子翻看的人会多一些,再往后面的帖子就很少有人看了,所以我们可以把前面几页的帖子数据放在list中,然后设定一个规则,定时去list删数据,我们就可以用到list的ltrim吗,命令:
localhost:6379> ltrim codebear 1 -1
OK
localhost:6379> lrange codebear 0 -1
1) "c"
2) "b"
3) "a"
这个ltrim有点奇怪,它是保留索引范围之内的数据,删除索引范围之外的数据,现在给定的第一个参数是1,第二个参数是-1,就是要保留从索引为1到结束的数据,所以索引为0的数据被删除了。
hash
现在有一个产品详情页,里面有产品介绍,有价格,有温馨提示,有浏览数,有购买人数等等一堆信息,当然我们可以把整个对象都用String来存储,但是可能有一些地方只需要产品介绍,尽管是这样,我们还是必须得把整个对象都拿出来,是不是有点不太划算呢?hash就可以解决这样的问题:
localhost:6379> hset codebear name codebear
(integer) 1
localhost:6379> hset codebear age 18
(integer) 1
localhost:6379> hset codebear sex true
(integer) 1
localhost:6379> hset codebear address suzhou
(integer) 1
localhost:6379> hget codebear address
"suzhou"
如果我们是存储整个对象,现在想修改下age,怎么办?要把整个对象全部拿出来,然后再赋值,最后又得放回去,但是现在:
localhost:6379> hincrby codebear age 2
(integer) 20
localhost:6379> hget codebear age
"20"
set
set是一种无序,且去重的数据结构,我们可以用它去重,比如我现在要存储所有商品的Id,就可以用set来实现,有什么场景需要存储所有商品的Id呢?防止缓存穿透,当然防止缓存穿透有很多实现方案,set方案只是其中的一种。我们来康康它的基本用法:
localhost:6379> sadd codebear 6 1 2 3 3 8 6
(integer) 5
localhost:6379> smembers codebear
1) "1"
2) "2"
3) "3"
4) "6"
5) "8"
可以很清楚的看到我们存进去的数据被去重了,而且数据被打乱了。
我们再来看看srandmember这个命令有什么用?
localhost:6379> srandmember codebear 2
1) "6"
2) "3"
localhost:6379> srandmember codebear 2
1) "6"
2) "2"
localhost:6379> srandmember codebear 2
1) "6"
2) "3"
localhost:6379> srandmember codebear 2
1) "6"
2) "2"
localhost:6379> srandmember codebear 2
1) "8"
2) "3"
srandmember 后面可以带参数,后面跟着2,就代表随机取出两个不重复的元素,如果想取出两个可以重复的元素,怎么办呢?
localhost:6379> srandmember codebear -2
1) "6"
2) "6"
如果后面跟着负数,就代表取出的元素可以是重复的。
如果后面跟的数字大于set元素的个数呢?
localhost:6379> srandmember codebear 100
1) "1"
2) "2"
3) "3"
4) "6"
5) "8"
localhost:6379> srandmember codebear -10
1) "8"
2) "1"
3) "1"
4) "1"
5) "6"
6) "1"
7) "1"
8) "2"
9) "6"
10) "8"
如果是正数的话,最多把set中所有的元素都返回出来,因为正数是不重复的,再多返回一个出来,就重复了,如果是负数,那么不影响,后面跟着几,就返回多少个元素出来。
我们做抽奖系统,就可以用到这个命令了,如果可以重复中奖,后面带着负数,如果不能重复中奖,后面带着正数。
set还可以计算差集、并集、交集:
localhost:6379> sadd codebear1 a b c
(integer) 3
localhost:6379> sadd codebear2 a z y
(integer) 3
localhost:6379> sunion codebear1 codebear2
1) "a"
2) "c"
3) "b"
4) "y"
5) "z"
localhost:6379> sdiff codebear1 codebear2
1) "b"
2) "c"
localhost:6379> sinter codebear1 codebear2
1) "a"
上面的命令就不过多解释了,这有什么用呢,我们可以利用它来做一个“骗取融资”的推荐系统:你们的共同好友是谁,你们都在玩的游戏是哪个,你可能认识的人。
zset
set是无序的,而zset是有序的,其中每个元素都有一个score的概念,score越小排在越前面,还是先来康康它的基本使用把:
localhost:6379> zadd codebear 1 hello 3 world 2 tree
(integer) 3
localhost:6379> zrange codebear 0 -1 withscores
1) "hello"
2) "1"
3) "tree"
4) "2"
5) "world"
6) "3"
localhost:6379> zrange codebear 0 -1
1) "hello"
2) "tree"
3) "world"
现在我们就创建了一个key为codebear 的zset,往里面添加了三个元素:hello ,world ,tree,score分别为1,3,2,后面用zrange取出结果,发现已经按照score的大小排好序了,如果后面跟着withscores,就会把score一起取出来。
如果我们想看看tree排在第几位,我们可以用zrank命令:
localhost:6379> zrank codebear tree
(integer) 1
因为是从0开始的,所以结果是1。
如果我们想查询tree的score是多少:
localhost:6379> zscore codebear tree
"2"
如果我们想取出从大到小的前两个,怎么办:
localhost:6379> zrange codebear -2 -1
1) "tree"
2) "world"
但是这样的结果是有些错误的,从大到小的前两个,第一个元素是world,又该如何呢:
localhost:6379> zrevrange codebear 0 1
1) "world"
2) "tree"
像排行榜,热点数据,延迟任务队列都可以用zset来实现,其中延迟任务队列在我以前的博客有介绍过。
谈到szet,可能还会引出一个问题,Redis中的zset是用什么实现的?跳表。
关于跳表,在这里就不展开了,为什么要用跳表实现呢,是因为跳表的特性:
读写均衡。
Redis为什么那么快
这是一个经典的面试题,几乎面试谈到Redis,80%都会问这问题,为什么Redis那么快呢?主要有以下原因:
- 编程语言:Redis是用C语言编写的,更接近底层,可以直接调用os函数。
- 基于内存:因为Redis的数据都是放在内存的,所以更快。如果放在硬盘,性能要看两个指标:寻址(转速),吞吐。寻址是毫秒级别的,一般来说,吞吐在500M左右,就算服务器性能再牛逼,也不会有几个G的吞吐,而放在内存,是纳秒级别的。
- 单线程:因为Redis是单线程的,所以避免了线程切换的消耗,也不会有竞争,所以更快。
- 网络模型:由于Redis的网络模型是epoll,是多路复用的网络模型。(关于epoll后面会展开讨论)
- Redis数据结构的优化:Redis中提供了5种数据类型,其中zset用跳表做了优化,而且整个Redis其实也都用hash做了优化,使其的时间成本是O(1),查找更快。
- Redis6.0推出了I/O Threads,所以更快。(关于I/O Threads后面会展开讨论)
Redis有什么缺点
这就是一个开放式的问题了,有很多答案,比如:
- 因为Redis是单线程的,所以无法发挥出多核CPU的优势。
- 因为Redis是单线程的,一旦执行了一个复杂的命令,后面所有的命令都被堵在门外了。
- 无法做到对hash中的某一项添加过期时间。
Redis为什么可以保证原子性
因为Redis是单线程的,所以同时只能处理一个读写请求,所以可以保证原子性。
Redis是单线程的,到底该如何解释
我们一直在强调Redis是单线程的,Redis是单线程的,但是Redis真的完全是单线程的吗?其实不然,我们说的Redis是单线程的,只是Redis的读写是单线程的,也就是work thread只有一个。
什么是I/O Threads
I/O Threads是Redis 6.0推出的新特性,在以前Redis从socket拿到请求、处理、把结果写到socket是串行化的,即:

而Redis6.0推出了I/O Threads后:
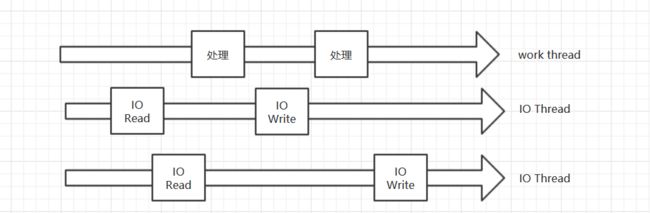
可以看到I/O Thread有多个,I/O Thread负责从socket读数据和写数据到socket,work thread在处理数据的同时,其他I/O Thread可以再从socke读数据,先准备好,等work thread忙完手中的事情了,立马可以处理下个请求。
但是work thread只有一个,这点要牢记。
什么是epoll
epoll是一种多路复用IO模型,在说epoll之前,不得不说下传统的IO模型,传统的IO模型是同步阻塞的,什么意思呢?就是服务端建立的socket会死死的等待客户端的连接,等客户端连接上去了,又会死死的等待客户端的写请求,一个服务端只能为一个客户端服务。
后来,程序员们发现可以用多线程来解决这个问题:
- 当第一个客户端连接到服务端后,服务端会启动第一个线程,以后第一个客户端和服务端的交互就在第一个线程中进行。
- 当第二个客户端连接到服务端后,服务端又会启动第二个线程,以后第二个客户端和服务端的交互就在第二个线程中进行。
- 当第三个客户端连接到服务端后,服务端又会启动第三个线程,以后第三个客户端和服务端的交互就在第三个线程中进行。
看起来,很美好,一个服务端可以为N个客户端服务,但是总不能无限开线程把 ,在Java中,线程是有自己的独立栈的,一个线程至少消耗1M,而且无限开线程,CPU也会受不鸟啊。
虽然后面还经历了好几个时代才慢慢来到了epoll的时代,但是我作为一个curd boy,api boy就不去研究的那么深了,现在我们跨过中间的时代,直接来到epoll的时代吧。
我们先来认识下epoll的方法,在linux中,可以用man来看看OS函数:
man epoll
在介绍中有这么一段话:
* epoll_create(2) creates a new epoll instance and returns a file descriptor referring to that instance. (The more recent epoll_create1(2) extends
the functionality of epoll_create(2).)
* Interest in particular file descriptors is then registered via epoll_ctl(2). The set of file descriptors currently registered on an epoll
instance is sometimes called an epoll set.
* epoll_wait(2) waits for I/O events, blocking the calling thread if no events are currently available.
虽然我英语实在是烂,但是借助翻译,还是可以勉强看懂一些,大概的意思是:
- epoll_create创建了一个epoll示例,并且会返回一个文件描述符。
- epoll_ctl用于注册感兴趣的事件。
- epoll_wait用于等待IO事件,如果当前没有感兴趣的IO事件,则阻塞,言外之意就是如果发生了感兴趣的事件,这个方法便会返回。
下面还给出了一个demo,我们来试着看下:
epollfd = epoll_create1(0);//创建一个epoll实例,返回一个 epoll文件描述符
if (epollfd == -1) {
perror("epoll_create1");
exit(EXIT_FAILURE);
}
ev.events = EPOLLIN;
ev.data.fd = listen_sock;
// 注册感兴趣的事件
// 第一个参数为epoll文件描述符
// 第二个参数为动作,现在是要添加感兴趣的事件
// 第三个参数为被监听的文件描述符
// 第四个参数告诉内核需要监听什么事件
// 现在监听的事件是EPOLLIN,表示对应的文件描述符上有可读数据
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listen_sock, &ev) == -1) {
perror("epoll_ctl: listen_sock");
exit(EXIT_FAILURE);
}
// 一个死循环
for (;;) {
// 等待IO事件的发生
// 第一个参数是epoll文件描述符
// 第二个参数是发生的事件集合
// 第三个参数不重要
// 第四个参数是等待时间,-1为永远等待
// 返回值是发生的事件的个数
nfds = epoll_wait(epollfd, events, MAX_EVENTS, -1);
if (nfds == -1) {
perror("epoll_wait");
exit(EXIT_FAILURE);
}
// 循环
for (n = 0; n < nfds; ++n) {
// 如果发生的事件对应的文件描述符是listen_sock
if (events[n].data.fd == listen_sock) {
// 建立连接
conn_sock = accept(listen_sock,
(struct sockaddr *) &addr, &addrlen);
if (conn_sock == -1) {
perror("accept");
exit(EXIT_FAILURE);
}
setnonblocking(conn_sock);// 设置非阻塞
ev.events = EPOLLIN | EPOLLET;// 设置感兴趣的事件
ev.data.fd = conn_sock;
// 添加感兴趣的事件,为 EPOLLIN或者EPOLLET
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, conn_sock,
&ev) == -1) {
perror("epoll_ctl: conn_sock");
exit(EXIT_FAILURE);
}
} else {
do_use_fd(events[n].data.fd);
}
}
}
由于本人没有学习过C语言,有些注释的不对的地方请多担待,但是自认为大概就是这么个意思。
如果学过Java中的NIO的话,看到上面的代码应该会觉得似曾相似。
epoll到底是个什么鬼呢,说的简单点,就是告诉内核我对哪些事件感兴趣,内核就会帮你监听,当发生了你感兴趣的事件后,内核就会主动通知你。
这有什么优点呢:
- 减少用户态和内核态的切换。
- 基于事件就绪通知方式:内核主动通知你,不牢你费心去轮询、去判断。
- 文件描述符几乎没有上限:你想和几个客户端交互就和几个客户端交互,一个线程可以监听N个客户端,并且完成交互。
epoll函数是基于OS的,在windows里面,没有epoll这东西。
好了,关于epoll的介绍就到这里了,又出现了三个新名词:用户态、内核态、文件描述符,就先不解释了,以后写NIO的博客再说吧。那时候,会更详细的介绍epoll。
Redis的过期策略
一般来说,常用的过期策略有三种:
- 定时删除:需要给每个key添加一个定时器,一到期就移除数据。优点是非常精确,缺点是消耗比较大。
- 定期删除:每隔一段时间,就会扫描一定数量的key,发现过期的,就移除数据。优点是消耗比较小,缺点是过期的key无法被及时移除。
- 懒删除:使用某个key的时候,先判断下这个key是否过期,过期则删除。优点是消耗小,缺点是过期的key无法被及时移除,只有使用到了,才会被移除。
Redis使用的是定期删除+懒删除的策略。
管道
如果我们有好多命令要交给Redis,第一个方案是一条一条发,缺点不言而喻:每条命令都需要经过网络,性能比较低下,第二个方案就是用管道。
在介绍管道之前,先要演示一个东西:
[root@localhost ~]# nc localhost 6379
set codebear hello
+OK
get codebear
$5
hello
我们往Redis发送命令,不一定必须要用Redis的客户端,只要连接上Redis服务器的端口就可以了,至于get codebear命令后面输出了$5是什么意思,就不在这里讨论了。
管道到底怎么使用呢,有了上面的基础,其实也很简单:
[root@localhost ~]# echo -e "set codebear hello1234 \n incr inttest \n set haha haha" | nc localhost 6379
+OK
:1
+OK
命令与命令之间用\n分割,然后通过nc发送给Redis。
我们再来康康是否成功了:
[root@localhost ~]# nc localhost 6379
get inttest
$1
1
get codebear
$9
hello1234
get haha
$4
haha
需要注意的,虽然多条命令是一起发送出去的,但是整体不具有原子性。
各大操作Redis的组件也提供了管道发送的方法,如果下次在项目中需要发送多个命令不妨试下。
发布订阅
当我们有个消息需要以广播的形式推送给各个系统,除了采用消息队列的方式,还可以采用发布与订阅的方式,在Redis中就提供了发布订阅的功能,我们来看下如何使用。
首先,我们要创建一个订阅者,订阅名称为hello的channel:
localhost:6379> subscribe hello
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "hello"
3) (integer) 1
然后,要创建一个发布者,往名称为hello的channel发送消息:
localhost:6379> publish hello goodmorning
(integer) 1
最后,再回到订阅者,发现接收到了消息:
1) "message"
2) "hello"
3) "goodmorning"
但是需要注意,如果先发布消息,订阅者再去订阅,是收不到历史消息的。
是不是特别简单,在我还不知道有ZooKeeper的时候,我觉得可以用Redis的发布订阅功能来做配置中心。
内存淘汰
如果Redis内存满了,再也容纳不下新数据了,就会触发Redis的内存淘汰策略,在redis.conf有一个配置,就是用来配置具体的内存淘汰策略的:
maxmemory-policy volatile-lru
它有好几个配置,在讲具体的配置前,要先说两个名词,如果这两个名词不了解的话,那么每个配置的含义真是只能死记硬背了。
- LRU:最少使用淘汰算法:如果这个key很少被使用,被淘汰
- LFU:最近不使用淘汰算法:如果这个key最近没有被使用过,被淘汰
下面就是具体的配置了,我们一一来看:
- volatile-lru:在设置了过期时间的key中,移除最近最少使用的key
- allkeys-lru:在所有的key中,移除最近最少使用的key
- volatile-lfu:在设置了过期时间的key中,移除最近不使用的key
- allkeys-lfu:在所有的key中,移除最近不使用的key
- volatile-random:在设置了过期时间的key中,随机移除一个key
- allkeys-random:随机移除一个key
- volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除
- noeviction:神马也不干,直接抛出异常
在生产环境中,到底应该使用哪个配置呢?
可以说网上的答案千差万别,但是可以统一的是一般不会选择noeviction,所以这个问题还是用万金油的答案,一个完全正确的废话答案:看场景。
本篇博客到这里就结束了,还有很多东西没有提到,先抛开主从、集群,光单机版的Redis就还有持久化、事务、协议、modules、GEO、hyperLogLog等等,还有Redis的延伸问题——缓存击穿、缓存雪崩、缓存穿透等等问题,都没有提到,等以后再和大家唠唠嗑把。