作者:蒋天园Date:2020-05-27来源: 3D目标检测深度学习方法之voxel-represetnation内容综述(一)
前言
笔者上一篇文章有介绍了3D目标检测中比较重要的数据预处理的两个方面的内容,其一是几种representation的介绍,分别是point、voxel和grap三种主要的representation,具体的可以表示为如下(这里的grids即是voxel)。上一篇文章也分析了这三种representation的优缺点:(1)point-sets保留最原始的几何特征,但是MLP感知能力不及CNN,同时encoder部分下采样采用了FPS(最远点采样)(目前就采样方法的研究也挺多,均匀采样,随机采样或者特征空间采样其异同都是值得思考研究的),FPS采样对比voxel的方法会更加耗时(2)voxel的方法在精度和速度上都是独树一帜的,但是不可避免的会有信息丢失,同时对体素参数相对比较敏感。(3)grah的表示在3D目标检测上,在CVPR20上才提出来,就Graph的backbone时间消耗比较久,比point的方法还要就更多,但是直观上看graph的结构增加了边信息更加容易机器感知。
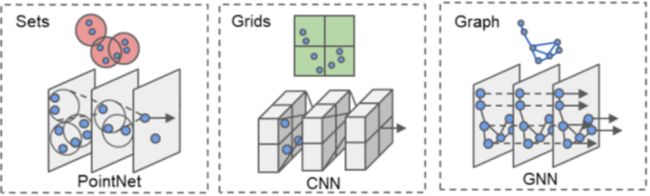
本文的主要内容是就只其中representation的方法的发展和目前仍然存在的问题做一个概述。后续再结合笔者学习给介绍一点可能会不是很清晰的知识。
1. voxel representation 背景知识介绍
这一小节,笔者将按照网络前馈过程逐个介绍如何将point信息转化为voxel信息,再通过深度学习网络特取到高维信息,再到二维rpn的设计。
1.1 point2voxle过程
上一篇文章有讲到过,这里复制过来:1. 设置Voxelization参数(每个voxel可以存放点的个数(max_points_number),voxel长宽高的大小(whl))2. 对依次每一个点,根据其对应的坐标(x,y,z)得到该点在voxel的索引。3. 根据索引判断该voxel种是否已经存在max_points_number个点,如果存在,则将该点直接丢弃,如果不满足,则将该点加入到该voxel中。4. 计算voxel特征为了方便理解笔者做了一个简单的示意,如下下图的过程则是Voxelization的过程,如果max_points_number设置为3,那么红色点如果是比较后加入到对应的voxel,那么就会被丢弃。

这里我们可以注意到笔者提到的信息损失则是来自于第三步的点的丢失。
1.2 voxel 特征提取
voxel特征提取的含义就是将point的特征转化为voxel特征,是紧紧承接上一步的内容,上一步得到了很多的voxel,每一个voxel中包含了少于max_points_number个点,这一步就是如何根据voxel中的point特取得到voxel特征,这里笔者介绍两种常用的特征提取方法:(1)MLP提取,即是对voxel中的点采用几层全连接层将voxel中的Point信息映射到高维,最后再在每个特征维度上使用maxpooling()得到voxel的特征,但是这种方法必须保证每一个voxel中的点数一样,所以所有的voxel就仅仅只有两种状态,要么是空的,要么是有max_points_number个点的(可以采用重采样的方式保证每一个voxel的点数一样多),一般来说这种特征提取的方式每一个voxel的点数比较多(2)均值特征。顾名思义,即是将voxel的point的特征(坐标+反射强度)直接取平均,目前这是比较优的point_fea2voxel_fea的方法
经过上述的voxle特征,我们就得到了每一个voxel的特征,就可以采用感知能力强大的CNN结构了。
1.3 voxel backbone
这一部分,在我们得到了voxel 特征后,就是进一步提取到更加全局的特征,上文中的voxel特征仅仅是在一个voxel中的特征,甚至连local feature都没有很好的提取到,就voxel backbone的发展经历了下面的两个阶段。
1.3.1 3DCNNbackbone
voxel-based的方法开始起步的时候,采用的voxel特征提取是上述中的第一种MLP提取方式,所对应的backbone的方法也就是采用比较容易实现的3D CNN,如下图笔者做一了一个简单的示意,通过voxel特征提取我们得到了point2voxel的特征,下图中左边表示的内容(C表示特征维度),其中空的voxel表示在原始空间没有点的在该voxel内,3D CNN则是对这样一个(H,W,L,C)的四维张量做3D空间中的卷积,笔者示意图的kernel大小为(222)(一般情况下是333的大小),真实情况中空的voxel比示意图中还要多得多,这我们在日常生活中也是可以体验到的。下图中的黄色kernel也是三维的,经过4次stride=2的卷积再加一次额外的高度维的stride=2的卷积后得到了右图的feature map ,但是这个时候任然是三维的feature map.

经过下图的操作,即将高度维的特征直接压缩到特征维中,变成了二维的feature map。所以此后就可以直接采用二维RPN 网络结构对三维物体进行目标检测。这个会在后续的RPN Head的网络中讲到。

从上面的示意图和介绍中,我们不难发现至少有如下的几个问题:(1)3D卷积的kernel为三维kernel,因此会存在参数量巨大的问题,可能不好学习或者导致过拟合。(2)输入的整个场景的voxels含有很多空的voxel,但是在卷积过程需要将其的特征填充为0,是很占显存的,同时时间效率也降低。上述两点是目前解决的比较好的问题了,就笔者的理解,至少还有如下的两个问题有待解决,(3)backbone特征提取实际上是逐渐将H维度降低为2,最后再压缩为1,所提取到的特征更加偏向于BEV视图的特征,如何更好的利用点云的整体信息是可以考虑的,(4)从上面的图中可以看出,在输入场景中是有很多空backbone的,这虽然对3D CNN是一种显存的损失,但是却维持了三维物体的几何结构,但是经过Backbone的CNN过程,会导致原本是空的voxel变得有信息,从而丢失了几何结构信息,这是一个很值得考虑的问题。
1.3.2 稀疏卷积 backbone
上文提到的内容中提到过3D CNN存在一个比较重要的问题是空的voxels会导致显存的浪费,所以后续的研究者yanyan(SECOND(Sensors18))采用稀疏卷积减少显存占用,具体的可以参看second原文(SECOND: Sparsely Embedded
Convolutional Detection)或者笔者觉得 讲的也很清晰的文章3D backbone(3D Backbone Network for 3DObject Detection)。
其实稀疏卷积的含义就是只对含有点的voxel做卷积输入,如果是空的voxel就直接不参与卷积计算,但是实际上随着卷积过程的推进,由于卷积的膨胀性质,会出现更多的非空的voxel。这个问题后续引入了“流型卷积层”来缓解这个膨胀问题。
这里先给出SECOND中的结构图如下,实际上可以看的出来就是将3D卷积充分利用二维 map映射关系来做。
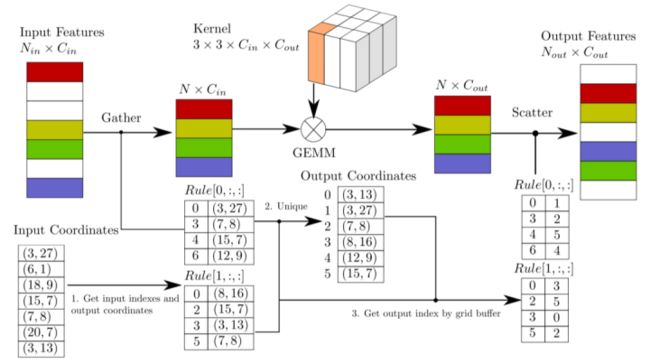
笔者这里画出一个简化的内容如下,实际上就是先将原始空间中的非空的voxel的空间索引记录起来,将其特征排成一列map,卷积操作也是通过计算索引来完成的,也就是说最终的结果仅仅是在二维中通过索引计算得到的,最后将final-feature-map通过最终的空间索引还回成voxel表达即可。一样的,为了使用二维RPN网络,一般的设计都是和上面一样将H层直接压缩到特征。

1.3.3 backbone 小结
上面介绍了两种按照先后顺序发展起来的backbone方法,其中3D CNN和voxel特征提取中提到的MLP特征提取相配合(因为但是3D CNN还没有稀疏卷积表达形式,所以考虑到显存消耗,在voxelization时参数设置比较粗糙,所以每一个voxel中的点比较多,采用MLP特征提取是比较合适的)。其中3D 稀疏卷积表达是当前流行的backbone设计基础结构,极大的解放了显存占用,因此可以在3D稀疏卷积上设计各种高效的Backbone结构。但是从CVPR19到CVPR20一段时间内的voxel -backbone都是采用如下的encoder的结构。这里直接截取PV-RCNN(CVPR20)的网络结构的一部分,看的出来3D稀疏卷积的部分仅仅是一个下采样卷积特征提取的过程,最后的To BEV也就是上面笔者所画的将H层压缩到特征维度的操作。

1.3.4 补充知识
前面提到了3Dbackbone至少存在着四个值得考虑的问题,其中最大的显存占用问题已经通过稀疏表达的形式得到了比较好的解决,那么针对第四点问题,也就是卷积膨胀使得几何结构模糊化的问题,笔者有两点可以介绍,一点是今年的CVPR的文章SA-SSD,(在前面的文章中有细致的讲解),如下图所示,为了使得voxel-backbone结构能够拥有原始几何结构的感知能力,作者在原始点中添加了两项附加任务,分别做语义分割和中心点预测,最后的目标检测结构得到了很好的几何结构的感知能力。

第二点是笔者在实验中的思考,实际上在使用稀疏卷积的同时会配合使用‘流型卷积’结构,最原始的出处是SubmanifoldSparse Convolutional Networks(FAIR,NIPS17),具体的内容就是卷积过程带着膨胀的性质,实际上会模糊掉边界几何信息,如下图所示。所以研究者就提出卷积输出的grid需要在有本来就有特征的grid才有输出,换句话说,就是在原来本身不是空的voxle才是具有输出的,而原本是空的,但是周围kernel邻域内存在非空的voxels是不可以输出的,这样就能一定上保持比较重要的几何结构。

但是换个思考方式,卷积特征提取本身是在提取到更高维的特征,可能后续的feature-map在我们看来的边界模糊再机器感知中是能够被理解的也不一定。但是在3D卷积结构中,实验表明加了流型学习层的效果都比较好。这里笔者给出代码中的常用的设计格式如下,一般都是两层的‘流型学习’层加上一层的‘稀疏卷积’层(这样仅仅只做一个stride=2,所以一般下采样会得到设计4个这样的结构做到8×的下采样)。
SubMConv3d(num_input_features,128, 3, indice_key="subm0"),
BatchNorm1d(128),
nn.ReLU(),
SubMConv3d(128, 128, 3,indice_key="subm0"),
BatchNorm1d(128),
nn.ReLU(),
SpConv3d(128, 64, 3, 2,
padding=1), # [41,1280,1056]→[21,640,528]
BatchNorm1d(64),
nn.ReLU(),
1.3 二维 RPN
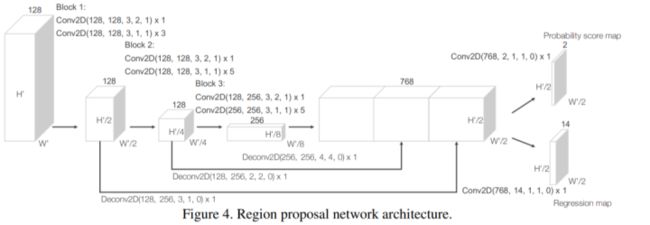
为什么叫二维RPN,因为从上面的backbone中我们最后将H维度直接压缩到特征维度中,直接将三维feature-map转化为了二维特征图,所以在二维特征图上,我们可以进一步采用二维优秀的RPN结构做三维目标检测任务,尽管voxel-representation的RPN结构有挺多的设计,但是就最基础高效的设计都是采用Voxle-net(CVPR18)上的RPN设计。如下所示,非常清晰的一个下采样然后上采样concat的结构。就不多提。在做cls和reg之前,笔者假设我们的feature-map大小是[B,H,W,C],那么做cls的话和正真的二维检测都是一样的直接在特征维度上映射到1,即[B,H,W,1];我们知道在二维检测中回归只需要回归Bbox的左上角和右下角的坐标即可,但是在3D目标检测中,我们需要回归七个维度,分别是中心点坐标(X,Y,Z),长宽高(W,H,L)以及朝向(dir),但是在实际实验中,会回归预定设置的朝向的倍数个参数量,即比如anchor预先设定的值为90°和180°,那么我们需要对每一个anchor都回归这样的七个维度,也就是14,同样对cls也需要分类两个。这些问题在一些文章中有一定的改进。ICCV19的STD采用球划分,就不会有方向性,更加优秀的anchor设计方式。
1.5 背景知识小结
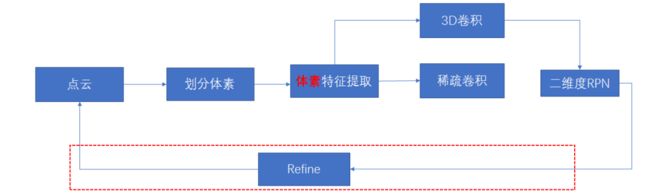
这里就相当于把一个one-stage的3D目标检测算法给讲明白了,这其实也就是在19年上半段的研究者的研究工作,在19年的下半段出现了很多refine网络结构,也就是精度更高的两阶段3D目标检测方法,这里画一个简单的总结图如下,除了refine阶段,上面的内容就是最基础的3D目标检测one-stage的结构。可能会在后面的文章中介绍到。
2 voxel-representation文章发展
笔者这里想按照问题问题解的发展历程,按照问题介绍发展。目标检测主要可以分为两个大的问题,一个是精度,一个个是速度,这也是为voxel-backbode的方法受欢迎,因为在速度和精度上都达到了比较好的效果。这一篇先介绍一下在速度上,前人研究者都做过哪些比较重要的尝试。
2.1 速度上的改进
在第一小节中,笔者提到3DCNN时间消耗太大,因此在18年的SENSORS研究者提取采用稀疏卷积代替3DCNN,大大的减少了参数量和显存消耗,这里不多介绍这篇文章。后续在19年CVPR上,pointpillars充分利用BEV视图特性,如下图,我们前文介绍到的都是划分voxel,这篇文章直接划分pillars,这样的好处可以直接将3D CNN过程省略掉,FPS高达恐怖的60,但是不可避免的是这样做信息感知能力变差,需要进一步做更多的优化工作。这也促使我们在思考这样的一个问题,BEV视图下的特征是否真的已经足够做3D目标检测?

进一步的 在NIPS19上有一篇出自韩松实验的文章Point-Voxel CNN for Efficient 3DDeep Learning,想要通过voxel结构代替pointnet++特征提取,也就是希望借助voxel特征提取的快速性(好像不是很搭边),如下图可以看的出来,实际上也就是将pointnet++采用voxel-backbone代替掉,然后再采用插值的方式回到点中。最后也将该方法测试在pointR-CNN中得到了不错的效果。

目前在voxel-representation上从速度着手的研究工作并不是很多(得益于稀疏卷积),但是在point-based的方法中是很多从速度方面着手的,比较好的有今年VPR20的3D-SSD,之前有写过比较细致的研究文章,有兴趣可以看一看研究者是如何思考这样的问题的。
2.2 精度上的改进
这一部分比较空旷,内容比较多,所以这一篇文章就先开个头,大概列举一下笔者所看到过的文章中主要的方向:
(1)refine(2)loss(3)fusion(4)backboe -structure(5)others。paper -list内容看上去不少了,所以这个最核心的内容就做下次的分享内容吧。这次后续再介绍一点
3 补充知识
3.1. point和二维图像的变换
很多研究工作采用了二维图像和3D点云融合的方式,以增大信息量,但是这其中如何确定一个点所对应的二维图像的像素点的位置呢,就KITTI而言,可以做如下补充。
就KITTI的数据而言,有
(1)我们下载的点云投影到相机平面的数据是calib_velo_to_cam.txt,表示的是点云到相机的定位文件。在KITTI中还有文件calib_cam_to_cam.txt(相机到相机的标定)。
(2)相机和点云的坐标定义:相机(x:右,y:下,z:前) 。点云(x:前,y:左,z:上),也就证实了上文中投影在相机前面的点时采用z>0为判定条件。
(3)计算点云到图像的投影矩阵,如下展开说:
3.1.1核心思想
计算点云到图像的投影矩阵需要三个参数,分别是P_rect(相机内参矩阵)和R_rect(参考相机0到相机xx图像平面的旋转矩阵)以及Tr_velo_to_cam(点云到相机的[RT]外参矩阵)。
3.1.2计算投影矩阵(matlab)
% 计算点云到图像平面的投影矩阵
R_cam_to_rect= eye(4);
R_cam_to_rect(1:3,1:3)= calib.R_rect{1}; % 参考相机0到相机xx图像平面的旋转矩阵
P_velo_to_img= calib.P_rect{cam+1}*R_cam_to_rect*Tr_velo_to_cam; % 内外参数
3.1.3点云投影到图像
投影矩阵乘以点云坐标。在此之前需要把点云填充到四维的齐次坐标,也就是加1。即把前三维作为输入因此需要转化为齐次坐标。投影矩阵是4* 4的。最后和point相乘就可以得到在二维图像中的位置了
3.2 推荐项目
就笔这前半年的研究过程,发现了很多优秀的3D目标检测的项目,笔者的起步是从SECOND的作者的项目出发,地址是:https://github.com/traveller59/second.pytorch。很多研究者的工作都是在这个基础上的,但是代码并不是很适合快速上手,笔者之前学习的时候有做过很多的记录笔记,如果读者都感兴趣的话,笔者可以在后续出一个该项目的教程。
接下来的这一个项目时mmdetection风格的项目,作者是CVPR20文章PV-RCNN的作者,代码风格和可改性就大很多,笔者目前也是在这个项目上实现自己的Idea,地址是:https://github.com/sshaoshuai/PCDet 此外还有很多优秀的项目,如旷世的det3D:https://github.com/poodarchu/Det3D。
推荐文献
[1] 3D Backbone Network for 3D ObjectDetection
[2] PointPillars: Fast Encoders for Object Detection from Point Clouds
[3] SECOND: Sparsely Embedded Convolutional Detection
[4] Submanifold Sparse Convolutional Networks
[5] Point-Voxel CNN for Efficient 3D Deep Learning