Pandas学习笔记02-数据合并(concat/merge/join)
文章目录
- 1.concat
- 1.1.设置keys值
- 1.2.按列合并axis=1
- 1.3.内连接join='inner'
- 1.4.忽略索引ignore_index=True
- 1.5.DataFrame与Series合并
- 1.6.行数据追加到数据帧
- 2.merge
- 2.1.链接方式how=' '
- 2.2.validate检查重复键
- 2.3.indicator合并指示器
- 2.4.left_on和right_on
- 3.join
pandas对象中的数据可以通过一些方式进行合并:
pandas.concat可以沿着一条轴将多个对象堆叠到一起;
pandas.merge可根据一个或多个键将不同DataFrame中的行连接起来。
这部分,我觉得pandas官网资料介绍的太香了,直接搬运过来吧。
1.concat
concat函数可以在两个维度上对数据进行拼接,默认纵向拼接(axis=0),拼接方式默认外连接(outer)。
纵向拼接通俗来讲就是按行合并,横向拼接通俗来讲就是按列合并;
外连接通俗来说就是取所有的表头字段或索引字段,内连接通俗来说就是只取各表都有的表头字段或索引字段。
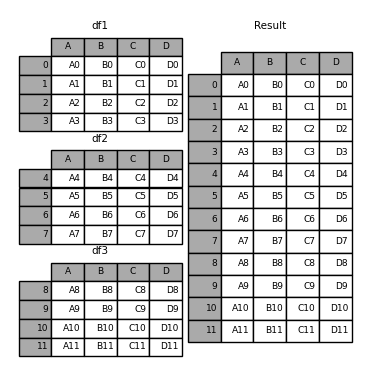
先简单看个例子吧~
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
In [4]: df = [df1,df2,df3]
In [5]: result = pd.concat(df)
pd.concat(objs, axis=0, join=‘outer’, ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)
objs:需要用于连接合并的对象列表
axis:连接的方向,默认为0(按行),按列为1
join:连接的方式,默认为outer,可选inner只取交集
ignore_index:合并后的数据索引重置,默认为False,可选True
keys:列表或数组,也可以是元组的数组,用来构造层次结构索引
levels:指定用于层次化索引各级别上的索引,在有keys值时
names:用于创建分层级别名称,在有keys和levels时
verify_integrity:检查连接对象中新轴是否重复,若是则异常,默认为False允许重复
copy:默认为True,如果是False,则不会复制不必要的可以提高效率
1.1.设置keys值
In [6]: result = pd.concat(df, keys=['x', 'y', 'z'])

我们还可以通过字典形式传递keys参数(以下代码结果 和上述一致):
In [7]: pieces = {'x': df1, 'y': df2, 'z': df3}
In [8]: result = pd.concat(pieces)
我们还可以指定keys值进行数据合并:
In [9]: result = pd.concat(pieces, keys=['z', 'y'])

以上我们可以看到,设定keys值后,合并后的数据多了一层索引,我们可以直接通过这一层索引选择整块数据:
In [10]: result.loc['y']
Out[11]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
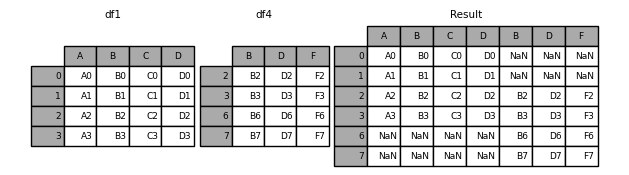
1.2.按列合并axis=1
默认情况下,join=‘outer’,合并时索引全部保留,对于不存在值的部分会默认赋NaN。
In [12]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
In [13]: result = pd.concat([df1, df4], axis=1,sort=False)
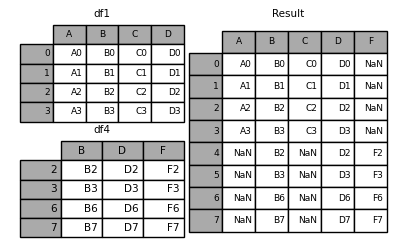
对于按照列合并数据时,如果我们希望只保留第一份数据下的索引,可以通过如下两种方式实现:
#①合并后只取第一份数据的索引
In [14]: pd.concat([df1, df4], axis=1).reindex(df1.index)
Out[15]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
#②对第二份数据设置索引为第一份部分索引
In [16]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[17]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
1.3.内连接join=‘inner’
内连接就是选取交集部分的索引或列名
In [18]: result = pd.concat([df1, df4], axis=1, join='inner')

1.4.忽略索引ignore_index=True
很多时候需要合并的数据存在索引重叠的情况,对于很多没有实际意义的索引(比如单纯的默认索引0到n-1),我们可以设定忽略索引从而创建新的0到m-1的索引。
In [19]: result = pd.concat([df1, df4], ignore_index=True, sort=False)
1.5.DataFrame与Series合并
Series与DataFrame合并时,会将Series转化为DataFrame的一列,该列名为Series的名称。
In [20]: s1 = pd.Series(['x0','x1','x2','x3'],name = 'x')
In [21]: result = pd.concat([df1,s1],axis=1)

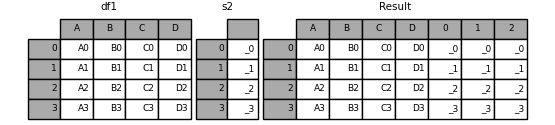
若Series未进行命名,则合并后的列名为连续的编号。
In [22]: s2 = pd.Series(['-0','-1','-2','-3'])
In [23]: result = pd.concat([df1,s2,s2,s2], axis=1)
我们同样可以通过使用ignore_index = True删除并重新进行列名称编号。
In [24]: result = pd.concat([df1, s1], axis=1, ignore_index=True)
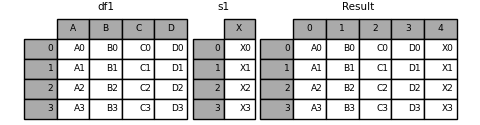
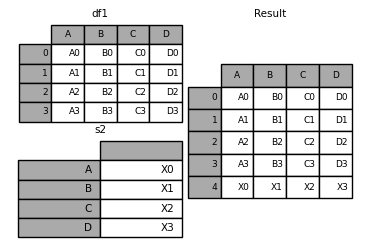
1.6.行数据追加到数据帧
这样做的效率一般,使用append方法,可以将Series或字典数据添加到DataFrame。
Series数据追加到数据帧
In [25]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [26]: result = df1.append(s2, ignore_index=True)
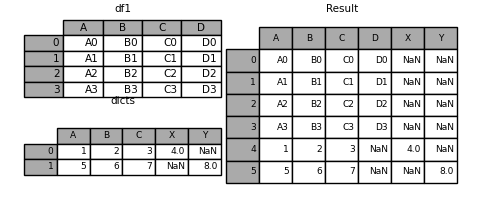
字典数据追加到数据帧
In [27]: dicts = [{'A': 1, 'B': 2, 'C': 3, 'X': 4},
...: {'A': 5, 'B': 6, 'C': 7, 'Y': 8}]
In [28]: result = df1.append(dicts, ignore_index=True, sort=False)
2.merge
merge可根据一个或多个键(列)相关同DataFrame中的拼接起来。SQL或其他关系型数据库的用户对此应该会比较熟悉,因为它实现的就是数据库的join操作。
pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=(’_x’, ‘_y’), copy=True, indicator=False,
validate=None)
left:参与合并的左侧数据
right:参与合并的右侧数据
how:合并类型:inner(默认内连接)、outer(外连接)、left(左连接)、right(右连接)
on:用于连接的列名,默认为左右侧数据共有的列名,指定时需要为左右侧数据都存在的列名
left_on:左侧数据用于连接的列
right_on:右侧数据用于连接的列
left_index:将左侧索引作为连接的列
right_index:将右侧索引作为连接的列
sort:排序,默认为True,设置为False可提高性能
suffixes:默认为(’_x’, ‘_y’),可以自定义如(‘date_x’,‘date_y’)
copy:默认为True,如果是False,则不会复制不必要的可以提高效率
indicator:指示器,设置为True时会新增一列标识行数据存在于哪侧数据
validate:字符串,如果指定则会检测合并的数据是否满足指定类型
validate 类型说明:
“one_to_one” or “1:1”: checks if merge keys are unique in both left and right datasets.
“one_to_many” or “1:m”: checks if merge keys are unique in left dataset.
“many_to_one” or “m:1”: checks if merge keys are unique in right dataset.
“many_to_many” or “m:m”: allowed, but does not result in checks.
先看个简单的例子
In [78]: result = df1.append(dicts, ignore_index=True, sort=False)
In [79]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
...: 'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3']})
...:
...: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']})
In [80]: result = pd.merge(left, right, on='key')

2.1.链接方式how=’ ’
left左连接
只保留左侧数据有的索引
In [81]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
...: 'key2': ['K0', 'K1', 'K0', 'K1'],
...: 'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3']})
...:
...:
In [81]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
...: 'key2': ['K0', 'K0', 'K0', 'K0'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']})
In [82]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])

right右连接
只保留右侧数据有的索引
In [46]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])

outer外连接
外连接会保留左右两侧全部的索引
In [47]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])

inner内连接
外连接只保留左右两侧均有的索引,这个也是默认的连接形式
In [48]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])

2.2.validate检查重复键
validate参数可以指定一对一、一对多、多对一和多对多的情况,若不满足对应情况则在合并时会发生异常。
In [83]: left = pd.DataFrame({'A' : [1,2], 'B' : [1, 2]})
In [84]: right = pd.DataFrame({'A' : [4,5,6], 'B': [2, 2, 2]})
以上left和right有重复项,都包含A和B名称的列,默认情况下是会根据两个都有的列名进行合并,若设置**validate=‘one_to_one’**则会报错。
In [88]: result
Out[88]:
Empty DataFrame
Columns: [A, B]
Index: []
In [89]: result = pd.merge(left, right,on = 'B',how ='outer',validate='one_to_one')
"Merge keys are not unique in right dataset; "
MergeError: Merge keys are not unique in right dataset; not a one-to-one merge
若我们设置**validate=‘one_to_many’**则可正常合并。
In [90]: pd.merge(left, right, on='B', how='outer', validate="one_to_many")
Out[90]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
In [91]: pd.merge(left, right, on='B', how='outer', validate="many_to_many")
Out[91]:
A_x B A_y
0 1 1 NaN
1 2 2 4.0
2 2 2 5.0
3 2 2 6.0
2.3.indicator合并指示器
默认情况下,indicator为False,若我们设置为True,则会在合并数据后新增一列标识
In [93]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [94]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [95]: df1
Out[95]:
col1 col_left
0 0 a
1 1 b
In [96]: df2
Out[96]:
col1 col_right
0 1 2
1 2 2
2 2 2
In [97]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[97]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
我们也可以对indicator辅助列进行命名,通过传递参数形式。
In [98]: pd.merge(df1, df2, on='col1', how='outer', indicator='辅助标识器')
Out[98]:
col1 col_left col_right 辅助标识器
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
2.4.left_on和right_on
当我们想合并的两个数据出现没有公共列名的情况,可以用left_on和right_on分别指定左右两侧数据用于匹配的列。
In [102]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'key': ['K0', 'K1', 'K0', 'K1']})
...:
...:
In [102]: right = pd.DataFrame({'C': ['C0', 'C1'],
...: 'D': ['D0', 'D1'],
...: 'key2': ['K0', 'K1']})
In [104]: result = pd.merge(left, right, left_on='key', right_on='key2',how='left', sort=False)
In [105]: result
Out[105]:
A B key C D key2
0 A0 B0 K0 C0 D0 K0
1 A1 B1 K1 C1 D1 K1
2 A2 B2 K0 C0 D0 K0
3 A3 B3 K1 C1 D1 K1
3.join
join可以将两个没用共同列名的数据进行快速合并,默认是保留被被合并的数据索引
In [106]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
...: 'B': ['B0', 'B1', 'B2']},
...: index=['K0', 'K1', 'K2'])
In [107]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
...: 'D': ['D0', 'D2', 'D3']},
...: index=['K0', 'K2', 'K3'])
In [108]: result = left.join(right)
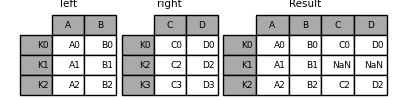
join接受的参数有how、on和suffix等
以下两个表达式是等效的:
>>>left.join(right, on=key_or_keys)
>>>pd.merge(left, right, left_on=key_or_keys, right_index=True,
how='left', sort=False)
比如:

In [109]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'key': ['K0', 'K1', 'K0', 'K1']})
...:
...:
In [109]: right = pd.DataFrame({'C': ['C0', 'C1'],
...: 'D': ['D0', 'D1']},
...: index=['K0', 'K1'])
In [110]: result = left.join(right, on='key')
In [111]: result
Out[111]:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K0 C0 D0
3 A3 B3 K1 C1 D1
In [112]: result = pd.merge(left, right, left_on='key', right_index=True,how='left', sort=False)
In [113]: result
Out[113]:
A B key C D
0 A0 B0 K0 C0 D0
1 A1 B1 K1 C1 D1
2 A2 B2 K0 C0 D0
3 A3 B3 K1 C1 D1
参考资料
①https://pandas.pydata.org/docs/user_guide/merging.html#timeseries-friendly-merging