机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(七)
上一节讲了SVM,这一节将另外一个强大的算法:决策树,它能够处理回归和分类问题,甚至是多输出问题,能够拟合复杂的数据(容易过拟合),而且它是集成算法:随机森林(Random forest)的基础,下面开始介绍决策树Scikit-learn的用法,以及参数的选择及算法的局限性。
七、决策树(Decision Trees)
1、训练决策树并其可视化
下面是决策树分类(DecisionTreeClassifier)用在Iris分类上的粒子。参数max_depth控制决策树的深度。
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # petal length and width
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2)
tree_clf.fit(X, y)训练完以后可以预测分为每一类的概率,或最终结果
tree_clf.predict_proba([[5, 1.5]])
tree_clf.predict([[5, 1.5]]) 
还可以用export_graphviz()方法把决策树画出来,输出的是.dot文件
from sklearn.tree import export_graphviz
export_graphviz(
tree_clf,
out_file=image_path("iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
).dot文件可以转换为PDF或png格式查看更加直观清晰。(linux使用dot命令转换需要graphviz包)
dot -Tpng iris_tree.dot -o iris_tree.png #linux代码 
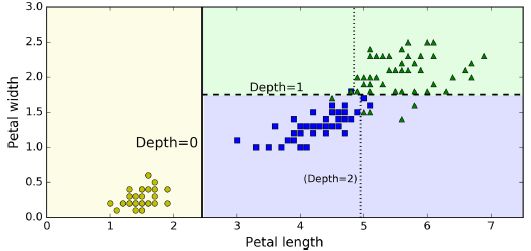
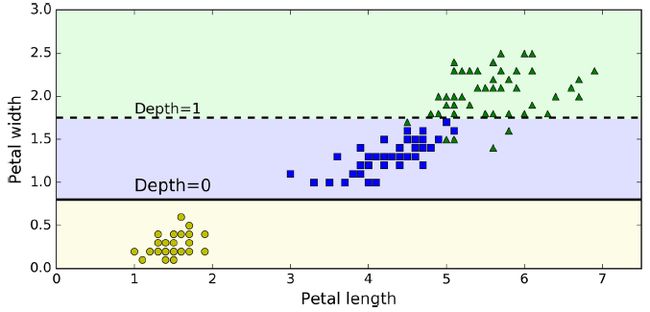
图中白色框的第一行为划分条件,gini为划分比例,samples为此时总共有多少样本,value为此时每一类样本的总数,class为分为哪一类。
因此如果有一个新的样本,则从顶端开始根据划分条件,不断往下判断,最终预测为某一类。
需要注意:决策树只需要很少样本就可以生成,而且不需要对特征进行缩放。而且Scikit使用的为CART algorithm,即每次只生成两个分支,而ID3等算法可以产生多个分支。
2、正则化参数(Regularization Hyperparameters)
由于决策树算法对训练数据没有什么假设(相比线性模型假设决策线为一条线),这就对算法没有任何限制,因此很容易拟合训练数据,从而很容易导致过拟合。
因此为了防止对训练数据过拟合,需要增加一些参数来限制。最一般的设置应该设置最大深度(max_depth);DecisionTreeClassifier类还有一些其他参数用来防止过拟合,节点被分开的最小样本数(min_samples_split);叶子节点的最小样本数(min_samples_leaf);和min_samples_leaf有点像,不过这个是分开节点变为叶子的最小比例,(min_weight_fraction_leaf);叶子节点的最大样本数(max_leaf_nodes);在每个节点分开时评估的最大特征数(max_features)。增加min_*,减小max_*都能正则化算法。
3、决策树回归(Decision Tree Regression)
决策树回归与决策树分类相似,不同的是决策树分类叶子节点最终预测的是类别,而决策树回归叶子节点最终预测的是一个值。
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y) 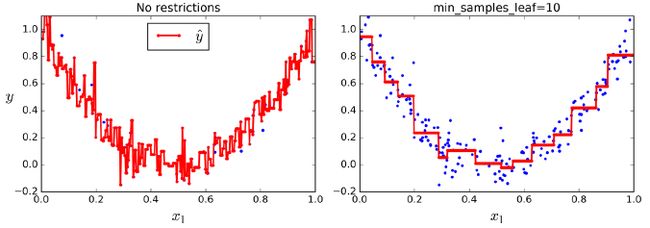
可以看到如果不加任何约束,则会产生过拟合。所以使用决策树回归时也要增加正则化参数。
4、局限性(不稳定性)
虽然决策树易于使用,易于展示与理解,但是存在一些局限性。你可能注意到决策树喜欢正交决策边界(垂直),这使得它们对训练集旋转很敏感。例如下图为一个简单的可线性分离的数据集:左边的决策树可以轻松地分割,而右边的数据集旋转45度后,决策边界看起来较为复杂。虽然这两个决策树都能拟合训练集,但是右边的模型很可能没有很好的泛化推广能力。解决这个问题的一种方法是使用PCA(后两节会说)来使训练数据更好的定位。

除了正交决策边界的缺陷以外,如果训练样本稍有变动,可能会导致决策线发生巨大改变,如左图删掉1个点以后决策线变为了右图,相差非常大,说明决策树算法非常不稳定。
随机森林可以通过对多个决策树作平均来限制这种不稳定性,在下一节的集成算法我们看到。
上一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(六)
下一篇:机器学习实战(用Scikit-learn和TensorFlow进行机器学习)(八)