统计推断——假设检验——python代码实现偏差总和、卡方检验(骰子问题)
假设你经营一家赌场,怀疑一位顾客使用作弊骰子,也就是说这个骰子经过处理,更容易掷出其中一面。你抓住这位受怀疑的作弊者,没收了筛子,但是还必须证明这个骰子有问题,你将这个骰子掷了60次,得到如下结果:
| 点数 |
1 | 2 | 3 | 4 | 5 | 6 |
| 频数 | 8 | 9 | 19 | 5 | 8 | 11 |
你希望的结果是每个点数平均出现10次。在这个数据集中,3出现的次数较多,4较少,但是,这些差异是统计显著的吗?
偏差总和
为了检验这个假设,我们可以计算出每个值的预期频数、预期频数与观擦频数的差值,以及差值绝对值的和,在这个示例中,我们预期60次投掷中,骰子的每一面都出现10次,[10,10,10,10,10,10],观察值与预期值的差值为[-2,-1,9,-5,-2,1],差值绝对值的和为20,完全偶然出现这么大差值的概率是多少?
原假设:骰子的质地均匀。
import collections
import math
#投掷60次骰子的随机结果
def RunModel4(data):
n=sum(data)
values=[1,2,3,4,5,6]
rolls=np.random.choice(values,n,replace=True) #在1~6数字当中随机有放回抽样n次
counter=collections.Counter(rolls) #统计各数字抽到的次数
freqs=[counter.get(x,0) for x in values] #返回1~6抽到次数的列表
return freqs
#计算实际数字出现的次数和理论出现的次数差值的绝对值。
def TestStatistic4(data):
observed=data
n=sum(observed)
expected=np.ones(6)*n/6 #计算理论出现的次数列表
test_stat=sum(abs(observed-expected)) #实际观测出现的次数和理论次数的比值
return test_stat
计算1000次试验的差值绝对值的和。
observed=[8,9,19,5,8,11]
a=[TestStatistic4(RunModel4(observed)) for _ in range(1000)] #计算1000次试验的结果。
sorted(a,reverse=True)输出:

b=sum(1 for x in a if x>=TestStatistic4(observed)) #计算比当前情况乃至更差情况出现的次数
b/1000输出:
0.138以上代码检验统计量为观察值和预期频数差值绝对值的和,原假设是骰子均匀,因此我们从values中随机抽取样本进行模拟,试验1000次,计算得到当前情况([8,9,19,5,8,11])出现的概率p值为0.13,也就是说,如果骰子没有问题,我们预期检验统计量达到或超过观察值的概率为0.13,因此,我们接受原假设,认为骰子有问题是不显著的。
卡方检验
在检验比例时,我们更多使用的是卡方统计量,将差值求平方(而不是绝对值)使得大偏差值得权重更大。除以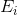 (理论值)可以将偏差标准化。
(理论值)可以将偏差标准化。

其中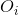 为观测到的频数,为预期频数(理论频数)。
为观测到的频数,为预期频数(理论频数)。
import collections
import math
#投掷60次骰子的随机结果
def RunModel5(data):
n=sum(data)
values=[1,2,3,4,5,6]
rolls=np.random.choice(values,n,replace=True) #在1~6数字当中随机有放回抽样n次
counter=collections.Counter(rolls) #统计各数字抽到的次数
freqs=[counter.get(x,0) for x in values] #返回1~6抽到次数的列表
return freqs
#计算卡方统计量。
def TestStatistic5(data):
observed=data
n=sum(observed)
expected=np.ones(6)*n/6 #计算理论出现的次数列表
test_stat=sum((observed-expected)**2/expected) #根据公式计算卡方值,注意,两个list列表是不可以相减的,但是array数组是可以这样操作的。
return test_stat计算1000次试验的卡方值。
observed=[8,9,19,5,8,11]
a=[TestStatistic5(RunModel5(observed)) for _ in range(1000)] #计算1000次试验的结果。
sorted(a,reverse=True)输出:

b=sum(1 for x in a if x>=TestStatistic5(observed)) #计算比当前情况乃至更差情况出现的次数
b/1000输出:
0.044使用卡方统计量计算的p值为0.04,明显小于使用偏差和的值0.13,如果我们坚持使用( )的检验水准,卡方检验就会认为骰子不均匀是显著的,而偏差总和统计量则认为是不显著了。
)的检验水准,卡方检验就会认为骰子不均匀是显著的,而偏差总和统计量则认为是不显著了。
这个示例说明了一个重要问题:p值取决于检验统计量的选择和原假设模型,有时这些因素决定了一个效应是否统计显著。