接下来我将从源码层面分情况和应用分析我们在计算queryset数据集时是用orm的count函数计算长度还是用len函数计算数据集长度。
首先,我们知道ORM查询queryset数据集是惰性查询的,只有使用到数据集时,ORM才会真正去执行查询语句,然后ORM会把查询到的数据集缓存到内存中,下次我们使用数据集时是从缓存中取值的。这就是ORM的惰性查询机制和缓存机制,还不清楚可以找相应的博客了解其概念,首先理解这两点我们便能更好地理解接下来的场景及应用。
1.、场景一:我们写了ORM查询语句,然后queryset数据集被使用然后缓存的情况下,我们使用queryset对象结果集.count()方法时其底层源码如下图是用len()方法计算结果集长度的,所以在此场景有缓存的情况下用len()和count()来计算查询结果集的效果是一样的;
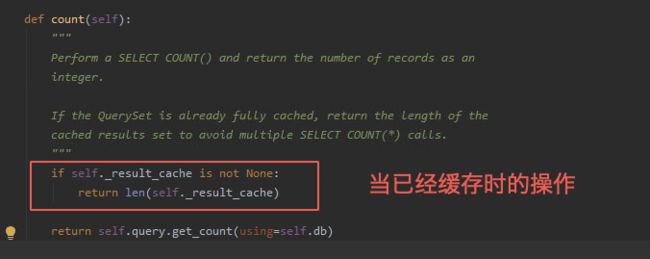
2、场景二:如果我们只想获得queryset对象的长度而不做queryset对象的其他操作的情况下,count函数底层实现如下图用的是数据库的聚合函数查询计算结果,
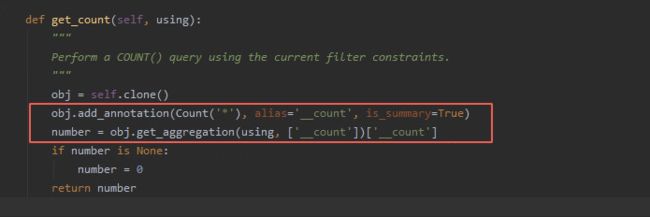
然后取其结果时间复杂度是O(1),空间复杂度为O(1),而len方法底层实现是是需要获取整个queryset数据集时间复杂度为O(n),并且空间复杂度也为O(n),

这种场景下使用count函数更好;
3、场景三:在初始我们写了ORM查询语句,然后接下来我们既要计算查询后结果集的长度,又要对结果集做其他操作(如获取每个queryset对象的属性等),(这里暂时不考虑分页时limit减小查询范围的情况)。
接下来我们分析len方法和count方法他们分别会做什么事情,首先如果是len操作的话会先触发orm的查询操作得到queryset结果集然后缓存,然后后续对结果集的操作直接从缓存中取对应的queryset对象,然后是count函数操作因为之前我们讲过ORM的惰性查询机制,在我们执行count函数的时其实这时查询操作还未真正的运行,也就是此时还没有queryset结果集的缓存,所以此时我们执行count方法会执行一次聚合函数查询,然后后续我们使用到queryset集合时就会触发数据库查询得到queryset结果集然后缓存。
所以在场景三的情况下,使用len()方法计算结果集的长度时会比count方法会更有优势,因为此时少了一次对数据的聚合查询操作。
4、场景四:如果是在先执行了数据库查询结果集并使用到了queryset结果有了缓存的情况下,参考场景一此时用len方法或者count方法的效果是一样的。
5、场景五:这也是最复杂也比较难判断的情况,首先步骤一:我们写了数据库查询操作(此时还未使用到这个查询的结果集),然后步骤二这里我们可能使用len方法或者count方法来计算结果集的长度,接下来步骤三我们使用分页组件对结果集进行分页处理,再步骤四使用我们分页后的结果集。
这种场景的话对于步骤二我们是使用len方法还是count方法来计算结果集的长度时就需要我们考虑以下几个因素了,
1)如果此时我们使用的是len方法的话我们会缓存整个queryset结果集,并相当于遍历了整个结果集时间复杂度为O(n),空间复杂度为O(n),步骤三的分页操作对于我们后端的时间或者空间来说都没什么太大帮助了
2)如果此时我们使用的是count()方法来计算长度的话,我们会多一次数据库查询操作,但是步骤三的分页操作相当于查询结果集时sql语句然后limit 10(数字取决于我们分页的size),这样我们的时间复杂度和空间复杂度都可以降到O(1)
个人倾向的话可能在此种情况我会使用count方法,通过多一次数据库查询操作来降低时间和空间的复杂度还是挺划算的。