Flink学习 - 7. Flink CheckPoint数据容错机制
Flink学习 - 7. Flink CheckPoint数据容错机制
- 有状态计算
- 什么是状态
- Keyed State
- Operator State
- 状态管理
- state的数据类型
- Keyed State
- Operator State
- Flink中使用state
- CheckPoint
- 单流的barrier
- 并行的barrier
- Checkpoint 的执行机制
- Statebackend
- HeapStateBackend
- RocksDBStateBackend
- CheckPoint机制详解
- Checkpoint 的 EXACTLY_ONCE 语义
有状态计算
Flink架构体系中,最重要的特性之一便是有状态计算。
什么是状态
状态计算一般是指: 在程序计算过程中,在程序内部储存计算所产生的中间结果,并提供给后续Function或者算子计算结果使用。
Flink有两种基本类型的State: Keyed State 和 Operator State(Non-Keyed State)。
Keyed State
是一种和Key相关的一种State,只能用于KeyedStream类型数据类型所对应的Functions和Operator上。
Operator State
Operator State和并行的算子实例绑定,与数据元素中的Key无关。Operator State支持 当算子实例并行度发生变化时自动重新分配状态数据。
状态管理
-
托管状态(Manager State)
由Flink Runtime中控制和管理状态数据,并将状态数据转换为内存Hash tables或RocksDB的对象存储,然后将这些状态数据通过内部的接口持久化到CheckPoints中,任务异常时可以通过这些状态数据恢复任务。 -
原生状态(Row State)
由算子自己管理数据结构,当触发CheckPoint过程中,Flink并不知道状态数据内部的数据结构,只是将数据转换成bytes数据存储在CheckPoints中,当从CheckPoint恢复任务是,算子自己再反序列化出状态的数据结构。
state的数据类型

Keyed State
- ValueState
- ListState
- ReducingState
- AggregatingState
- MapState
Operator State
- ListState
- BroadcastState
上述的State对象,仅仅用于与状态进行交互(更新,删除,清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄。实际上这些状态有三种存储方式:
MemoryStateBackend
FsStateBackend
RockDBStateBackend
Flink中使用state
- 使用ValueState:
package com.jerome.flink.state;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* This is Description
*
* @author Jerome丶子木
* @date 2019/12/25
*/
public class ValueStateTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource> inputStream = env.fromElements(new Tuple2(2, 21L), new Tuple2(4, 1L), new Tuple2(5, 4L));
SingleOutputStreamOperator> leastValue = inputStream.keyBy(0).flatMap(new RichFlatMapFunction, Tuple3>() {
private ValueState leastValueState;
@Override
public void open(Configuration parameters) throws Exception {
//创建ValueStateDescriptor,定意状态名称为leastValue,并指定数据类型
ValueStateDescriptor leastValueStateDescriptor = new ValueStateDescriptor<>("leastValue", Long.class);
//通过getRuntimeContext.getState获取State
leastValueState = getRuntimeContext().getState(leastValueStateDescriptor);
}
@Override
public void flatMap(Tuple2 value, Collector> out) throws Exception {
//通过value方法从leastValueState中获取最小值
Long leastValue = leastValueState.value();
if (leastValue != null) {
//如果当前指标大于最小值,则直接输出数据元素和最小值
if (value.f1 > leastValue) {
out.collect(new Tuple3<>(value.f0, value.f1, leastValue));
} else {
//如果当前指标小于最小值,则更新状态中的最小值
leastValueState.update(value.f1);
//将当前数据中的指标作为最小值输出
out.collect(new Tuple3<>(value.f0, value.f1, value.f1));
}
}else {
//如果状态中的值是空,则更新状态中的最小值
leastValueState.update(value.f1);
//将当前数据中的指标作为最小值输出
out.collect(new Tuple3<>(value.f0, value.f1, value.f1));
}
}
});
leastValue.print();
env.execute("ValueStateTest");
}
}
- 通过sum所使用的StreamGroupedStream来说明keyedState使用方法:

- FromElementsFunction类进行详解并分享如何在代码中使用 operator state:

CheckPoint
CheckPoint可以理解为: 将State状态数据持久化,注意这个CheckPoint是在同一时间点 Task/Operator的状态的全局快照。
CheckPoint是Flink在输入的数据集上间隔性的生成checkpoint barrier,并通过barrier将时间间隔段内的数据划分到相应的CheckPoint中。一旦Flink程序意外崩溃时,重新运行程序时可以有选择的从这些快照中恢复所有算子之前的状态,从而保证数据一致性。
单流的barrier

- checkpoint barrier会作为数据流的一部分注入到数据流中
- checkpoint barrier占用空间较小,非常轻量,对数据流任务影响相对较小。
- barrier严格遵循间隔性的产生,不会存在乱序
- 每一个checkpoint barrier都会携带对应的ID
并行的barrier

- Checkpoint指定触发生成时间间隔后,每当需要触发Checkpoint时,会向Flink程序运行时的多个分布式的Stream Source中插入一个Barrier标记。
- 这些Barrier会根据Stream中的数据记录一起流向下游的各个Operator。
- 多个输入流的Operator,需要在checkpoint 对齐(align)输入流,才会继续。当一个Operator接收到一个Barrier时,它会暂停处理Steam中新接收到的数据记录。因为一个Operator可能存在多个输入的Stream,而每个Stream中都会存在对应的Barrier,该Operator要等到所有的输入Stream中的Barrier都到达。当所有Stream中的Barrier都已经到达该Operator,这时所有的Barrier在时间上看来是同一个时刻点(表示已经对齐),在等待所有Barrier到达的过程中,Operator的Buffer中可能已经缓存了一些比Barrier早到达Operator的数据记录(Outgoing Records),
- 当对齐之后,该Operator会将数据记录(Outgoing Records)发射(Emit)出去,作为下游Operator的输入,最后将Barrier对应Snapshot发射(Emit)出去作为此次Checkpoint的结果数据。
Checkpoint 的执行机制
Apache Flink 进阶(三):Checkpoint 原理剖析与应用实践
下面阐述了state的存储,state是checkpoint进行持久化的主要角色。
Statebackend
下图阐释了目前 Flink 内置的三类 state backend,其中MemoryStateBackend和FsStateBackend在运行时都是存储在 java heap 中的,只有在执行 Checkpoint 时,FsStateBackend才会将数据以文件格式持久化到远程存储上。而RocksDBStateBackend则借用了 RocksDB(内存磁盘混合的 LSM DB)对 state 进行存储。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lEGH7QPv-1578641707672)(http://note.youdao.com/yws/res/22226/C34B91AB387C4CA5A2218BE5588429EA)]

HeapStateBackend
对于HeapKeyedStateBackend , 有两种实现:
- 支持异步CheckPoint(默认):存储格式CopyOnWriteStateMap
- 仅支持同步CheckPoint:存储格式NestedStateMap
特别在 MemoryStateBackend 内使用HeapKeyedStateBackend时,Checkpoint 序列化数据阶段默认有最大 5 MB 数据的限制
-
MamoryStateBackend
state 数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中,基于内存的statebackend在生产环境不建议使用。 -
FsStateBackend
state 数据保存在TaskManager的内存中,执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中,可以使hdfs等分布式文件系统。
RocksDBStateBackend
对于RocksDBKeyedStateBackend,每个 state 都存储在一个单独的 column family 内,其中 keyGroup,Key 和 Namespace 进行序列化存储在 DB 作为 key。

- RocksDBStateBackend
RocksDB的存储方式略有不同,他会在本地文件系统中维护状态,state会直接写入到本地的RocksDB 当中。同时RocksDB需要配置一个源端的filesystem。
uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中,failover的时候从filesystem中恢复到本地。
RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用。
CheckPoint机制详解
下图左侧是CheckPoint Coordinator,是整个CheckPoint的发起者,中间是由两个source,一个sink组成的Flink作业,最右侧的是持久化存储,在大部分用户场景中对应HDFS。
- 第一步,CheckPoint coordinator 向所有source节点trigger CheckPoint;
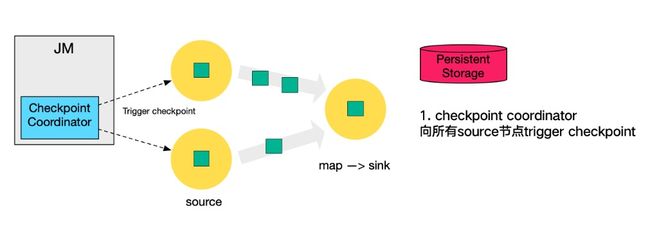
- 第二步, source 节点向下游广播barrier,这个barrier就是实现Chandy-Lamport分布式快照算法的核心,下游的task只有收到所有input的barrier才会执行费相应的CheckPoint。

- 第三部,当task完成state备份后,会将备份数据的地址(state handle)通知给CheckPoint coordinator。

- 第四步,下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。

- 同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator。

- 最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。

Checkpoint 的 EXACTLY_ONCE 语义
为了实现 EXACTLY ONCE 语义,Flink 通过一个 input buffer 将在对齐阶段收到的数据缓存起来,等对齐完成之后再进行处理。而对于 AT LEAST ONCE 语义,无需缓存收集到的数据,会对后续直接处理,所以导致 restore 时,数据可能会被多次处理。下图是官网文档里面就 Checkpoint align 的示意图:

需要特别注意的是,Flink 的 Checkpoint 机制只能保证 Flink 的计算过程可以做到 EXACTLY ONCE,端到端的 EXACTLY ONCE 需要 source 和 sink 支持。