【大数据课程作业记录】学习HDFS和HBase的基本编程使用和Hash join的实现
本学期选修了《大数据系统与大规模数据分析》,本博文介绍第一次作业的内容和相关情况,但是最终得分并不高,所以代码仅供参考吧。
一、作业内容
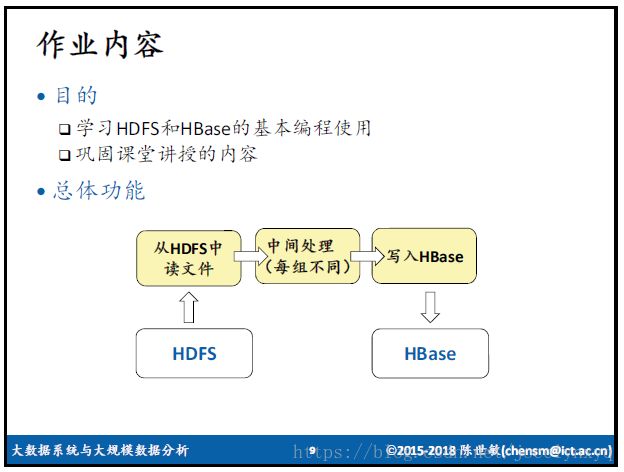
比较有意思的是,这次作业中,中间处理部分是根据学号的后六位有六个不同的小组,分别做不同的中间处理内容。如下:

我是两个数据表的Hash join。
二、操作介绍
1.从HDFS中读文件
HDFS中的文件都是格式规整的文件格式,每一行是一个关系型记录,如下:

老师在作业中也给出了一个HDFS中读取文件的demo,如下:
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
/**
*complie HDFSTest.java
*
* javac HDFSTest.java
*
*execute HDFSTest.java
*
* java HDFSTest
*
*/
public class HDFSTest {
public static void main(String[] args) throws IOException, URISyntaxException{
String file= "hdfs://localhost:9000/hw1/README.txt";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(file), conf);
Path path = new Path(file);
FSDataInputStream in_stream = fs.open(path);
BufferedReader in = new BufferedReader(new InputStreamReader(in_stream));
String s;
while ((s=in.readLine())!=null) {
System.out.println(s);
}
in.close();
fs.close();
}
}
2.将输出写入到HBase

老师在作业中也给出了HBase创建表和放入内容的demo,如下:
/*
* Make sure that the classpath contains all the hbase libraries
*
* Compile:
* javac HBaseTest.java
*
* Run:
* java HBaseTest
*/
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.log4j.*;
public class HBaseTest {
public static void main(String[] args) throws MasterNotRunningException, ZooKeeperConnectionException, IOException {
Logger.getRootLogger().setLevel(Level.WARN);
// create table descriptor
String tableName= "mytable";
HTableDescriptor htd = new HTableDescriptor(TableName.valueOf(tableName));
// create column descriptor
HColumnDescriptor cf = new HColumnDescriptor("mycf");
htd.addFamily(cf);
// configure HBase
Configuration configuration = HBaseConfiguration.create();
HBaseAdmin hAdmin = new HBaseAdmin(configuration);
if (hAdmin.tableExists(tableName)) {
System.out.println("Table already exists");
}
else {
hAdmin.createTable(htd);
System.out.println("table "+tableName+ " created successfully");
}
hAdmin.close();
// put "mytable","abc","mycf:a","789"
HTable table = new HTable(configuration,tableName);
Put put = new Put("abc".getBytes());
put.add("mycf".getBytes(),"a".getBytes(),"789".getBytes());
table.put(put);
table.close();
System.out.println("put successfully");
}
}
三、Hash join实现
1.关于Hash join
假如是对R和S两个表做hash join,若仅考虑hash table能放入内存的情况,首先要将R表(一般考虑性能应该将R和S中较小的那
个表)转变成为内存中的一个hash table,hash table中的hash key就是R和S做join的列的值。
然后开始从S表里面获取数据,对于S里的每一条数据的连接列使用相同的hash函数,并将每个hash值进行匹配,找到对应的R里数据在hash table里面的位置,在这个位置上检查能不能找到匹配的数据。因为匹配是在内存中进行,速度较merge sort join快很多。
由于使用了hash函数,hash join只能用在join条件是等于的条件下。
在这里,数据集R称为build table,数据集S称为probe table。
2.代码实现
import java.io.*;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
/**
* @ClassName: Hw1Grp0
* @Description: This class implements the function of reading data from HDFS,
* performing hash join and putting the result to HBase.
* @author: Jocelyn
* @date: 2018-04-10
*/
public class Hw1Grp0 {
private static final String TABLE_NAME = "Result";
private static final String COLUME_FAMILY = "res";
/**
* Creates HBase table.
* @param tableName the name of the table.
* @return nothing.
* @exception MasterNotRunningException.
* @exception ZooKeeperConnectionException.
* @exception IOException On input error.
* @see MasterNotRunningException
* @see ZooKeeperConnectionException
* @see IOException
*/
public void createHbaseTable(String tableName) throws MasterNotRunningException,
ZooKeeperConnectionException, IOException {
//configure HBase and judge whether the table exists
Configuration configuration = HBaseConfiguration.create();
HBaseAdmin hAdmin = new HBaseAdmin(configuration);
TableName tn = TableName.valueOf(tableName);
if(hAdmin.tableExists(tn)) {
System.out.println("table exists, delete it now");
hAdmin.disableTable(tn);
hAdmin.deleteTable(tn);
} else {
System.out.println("table not exists,create it now");
}
//create table descriptor
HTableDescriptor htd = new HTableDescriptor(tn);
//create colume descriptor
HColumnDescriptor cf = new HColumnDescriptor(COLUME_FAMILY);
htd.addFamily(cf);
hAdmin.createTable(htd);
hAdmin.close();
System.out.println("HBase table created");
}
/**
* Creates buffer reader of this file.
* @param file the specified file path.
* @return buffer reader.
* @exception IOException On input error.
* @exception URISyntaxException throws when string could not be parsed as a URI reference.
* @see IOException
* @see URISyntaxException
*/
public BufferedReader readHdfsFile(String file) throws IOException, URISyntaxException{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(file), conf);
FSDataInputStream in_stream = fs.open(new Path(file));
BufferedReader in = new BufferedReader(new InputStreamReader(in_stream));
return in;
}
/**
* Reads data from hdfs,uses hash join and stores in HBase.
* @param fileR the name of the file which contains the first data table.
* @param fileS the name of the file which contains the second data table.
* @param joinKeyR join key of the first data table.
* @param joinKeyS join key of the second data table.
* @param resCol result columns of the two tables.
* @return nothing.
* @exception IOException On input error.
* @exception URISyntaxException throws when string could not be parsed as a URI reference.
* @see IOException
* @see URISyntaxException
*/
public void hashJoin(String fileR, String fileS,int joinKeyR, int joinKeyS, String[] resCol) throws IOException, URISyntaxException {
//getting column numbers list of table R and table S
List listColR = new ArrayList();
List listColS = new ArrayList();
List listColName = new ArrayList();
for(int x = 0;x < resCol.length;x++){
if(resCol[x].indexOf("R")!= (-1)){
listColR.add(Integer.parseInt(resCol[x].substring(1)));
} else if(resCol[x].indexOf("S")!= (-1)) {
listColS.add(Integer.parseInt(resCol[x].substring(1)));
}
}
for(int i = 0;i < listColR.size();i++)
{
listColName.add("R"+String.valueOf(listColR.get(i)));
}
for(int i = 0;i < listColS.size();i++)
{
listColName.add("S"+String.valueOf(listColS.get(i)));
}
BufferedReader bufferR = readHdfsFile(fileR);
String r;
//doing hash map
Map hashR = new HashMap();
String lastJoinKeyR = null;
String keyFlag = "";
while ((r=bufferR.readLine())!=null) {
String[] tmpColR = r.split("\\|");
String thisJoinKey = tmpColR[joinKeyR];
String[] colR = new String[listColR.size()];
for(int i = 0;i < listColR.size(); i++){
colR[i] = tmpColR[listColR.get(i)];
}
if(thisJoinKey.equals(lastJoinKeyR)) {
keyFlag += "*";
} else {
keyFlag = "";
}
hashR.put(thisJoinKey + keyFlag, colR);
lastJoinKeyR = thisJoinKey;
}
BufferedReader bufferS = readHdfsFile(fileS);
String s;
List result = new ArrayList();
while ((s=bufferS.readLine())!=null) {
List matchR = new ArrayList();
String[] colS = s.split("\\|");
String thatJoinKey = colS[joinKeyS];
//using the join key to match records in the hash map
for(String st=""; ; st+="*") {
String[] valueR = hashR.get(thatJoinKey+st);
if(valueR == null) {
break;
}
else {
matchR.add(valueR);
}
}
//if this line has records to join
if(matchR.size() > 0) {
Iterator it = matchR.iterator();
while (it.hasNext()) {
String[] res = new String[resCol.length + 1];
String[] resColR = it.next();
String[] resColS = new String[listColS.size()];;
for(int i = 0;i < listColS.size(); i++){
resColS[i] = colS[listColS.get(i)];
}
res[0]= thatJoinKey;
System.arraycopy(resColR, 0, res, 1, resColR.length);
System.arraycopy(resColS, 0, res, 1 + resColS.length + 1, resColS.length);
//put the record to the result list
result.add(res);
}
}
}
HTable table = new HTable(HBaseConfiguration.create(),TABLE_NAME);
String lastRowKey = null;
String indexFlag = "";
int index = 0;
Put put = null;
if(result.size() > 0) {
Iterator itRes = result.iterator();
while (itRes.hasNext()) {
String[] record = itRes.next();
String rowKey = record[0];
if(rowKey.equals(lastRowKey)) {
index++;
indexFlag = "." + String.valueOf(index);
} else {
index = 0;
indexFlag = "";
if(put != null ){
table.put(put);
}
put = new Put(rowKey.getBytes());
}
//according to the result list put the record to hbase
for(int i = 1; i < record.length; i++) {
put.add("res".getBytes(),(listColName.get(i-1) + indexFlag).getBytes(),record[i].getBytes());
}
lastRowKey = rowKey;
}
}
if(put != null ){
table.put(put);
}
table.close();
System.out.println("HBase put successfully");
}
public static void main(String[] args) throws IOException, URISyntaxException{
if(args.length != 4) {
System.out.println("Mismatched number of input arguments");
System.out.println("Please type the command like:");
System.out.println("$ java Hw1Grp0 R=/hw1/lineitem.tbl S=/hw1/orders.tbl join:R0=S0 res:S1,R1,R5");
System.exit(0);
}
if(args[2].indexOf('=') == (-1)) {
System.out.println("You must input equal join with the symbol '='");
System.exit(0);
}
String fileR = args[0].substring(args[0].indexOf('=')+1).trim();
String fileS = args[1].substring(args[1].indexOf('=')+1).trim();
int joinKeyR = Integer.parseInt(args[2].substring(args[2].indexOf('R')+1,args[2].indexOf('=')).trim());
int joinKeyS = Integer.parseInt(args[2].substring(args[2].indexOf('S')+1).trim());
String[] resCol = args[3].substring(args[3].indexOf(':')+1).trim().split(",");
Hw1Grp0 hw = new Hw1Grp0();
hw.createHbaseTable(TABLE_NAME);
hw.hashJoin(fileR,fileS,joinKeyR,joinKeyS,resCol);
System.out.println("The process has been finished");
}
}