用scrapy只创建一个项目,创建多个spider,每个spider指定items,pipelines.启动爬虫时只写一个启动脚本就可以全部同时启动。
本文代码已上传至github,链接在文未。
一,创建多个spider的scrapy项目
scrapy startproject mymultispider
cd mymultispider
scrapy genspider myspd1 sina.com.cn
scrapy genspider myspd2 sina.com.cn
scrapy genspider myspd3 sina.com.cn
二,运行方法
1.为了方便观察,在spider中分别打印相关信息
import scrapy class Myspd1Spider(scrapy.Spider): name = 'myspd1' allowed_domains = ['sina.com.cn'] start_urls = ['http://sina.com.cn/']
def parse(self, response): print('myspd1')
其他如myspd2,myspd3分别打印相关内容。
2.多个spider运行方法有两种,第一种写法比较简单,在项目目录下创建crawl.py文件,内容如下
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # myspd1是爬虫名 process.crawl('myspd1') process.crawl('myspd2') process.crawl('myspd3') process.start()
为了观察方便,可在settings.py文件中限定日志输出
LOG_LEVEL = 'ERROR'
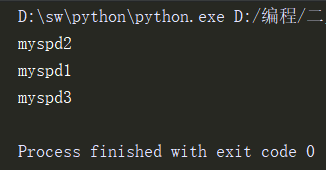
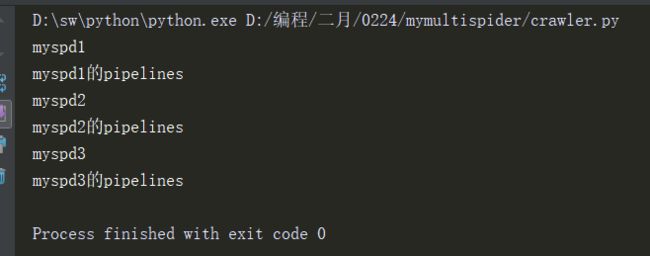
右键运行此文件即可,输出如下
3.第二种运行方法为修改crawl源码,可以从官方的github中找到:https://github.com/scrapy/scrapy/blob/master/scrapy/commands/crawl.py
在spiders目录的同级目录下创建一个mycmd目录,并在该目录中创建一个mycrawl.py,将crawl源码复制进来,修改其中的run方法,改为如下内容
def run(self, args, opts): # 获取爬虫列表 spd_loader_list = self.crawler_process.spider_loader.list() # 遍历各爬虫 for spname in spd_loader_list or args: self.crawler_process.crawl(spname, **opts.spargs) print("此时启动的爬虫:" + spname) self.crawler_process.start()
在该文件的目录下创建初始化文件__init__.py
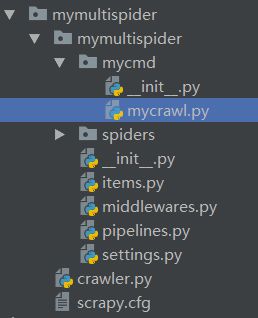
完成后机构目录如下
使用命令启动爬虫
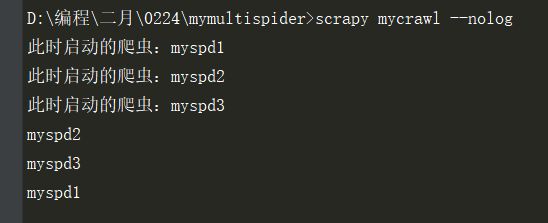
scrapy mycrawl --nolog
输出如下:
三,指定items
1,这个比较简单,在items.py文件内创建相应的类,在spider中引入即可
items.py
import scrapy class MymultispiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass class Myspd1spiderItem(scrapy.Item): name = scrapy.Field() class Myspd2spiderItem(scrapy.Item): name = scrapy.Field() class Myspd3spiderItem(scrapy.Item): name = scrapy.Field()
spider内,例myspd1
# -*- coding: utf-8 -*- import scrapy from mymultispider.items import Myspd1spiderItem class Myspd1Spider(scrapy.Spider): name = 'myspd1' allowed_domains = ['sina.com.cn'] start_urls = ['http://sina.com.cn/'] def parse(self, response): print('myspd1') item = Myspd1spiderItem() item['name'] = 'myspd1的pipelines' yield item
四,指定pipelines
1,这个也有两种方法,方法一,定义多个pipeline类:
pipelines.py文件内:
class Myspd1spiderPipeline(object): def process_item(self,item,spider): print(item['name']) return item class Myspd2spiderPipeline(object): def process_item(self,item,spider): print(item['name']) return item class Myspd3spiderPipeline(object): def process_item(self,item,spider): print(item['name']) return item
1.1settings.py文件开启管道
ITEM_PIPELINES = { # 'mymultispider.pipelines.MymultispiderPipeline': 300, 'mymultispider.pipelines.Myspd1spiderPipeline': 300, 'mymultispider.pipelines.Myspd2spiderPipeline': 300, 'mymultispider.pipelines.Myspd3spiderPipeline': 300, }
1.2spider中设置管道,例myspd1
# -*- coding: utf-8 -*- import scrapy from mymultispider.items import Myspd1spiderItem class Myspd1Spider(scrapy.Spider): name = 'myspd1' allowed_domains = ['sina.com.cn'] start_urls = ['http://sina.com.cn/'] custom_settings = { 'ITEM_PIPELINES': {'mymultispider.pipelines.Myspd1spiderPipeline': 300}, } def parse(self, response): print('myspd1') item = Myspd1spiderItem() item['name'] = 'myspd1的pipelines' yield item
指定管道的代码
custom_settings = { 'ITEM_PIPELINES': {'mymultispider.pipelines.Myspd1spiderPipeline': 300}, }
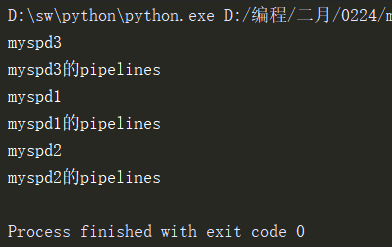
1.3运行crawl文件,运行结果如下
2,方法二,在pipelines.py文件内判断是哪个爬虫的结果
2.1 pipelines.py文件内
class MymultispiderPipeline(object): def process_item(self, item, spider): if spider.name == 'myspd1': print('myspd1的pipelines') elif spider.name == 'myspd2': print('myspd2的pipelines') elif spider.name == 'myspd3': print('myspd3的pipelines') return item
2.2 settings.py文件内只开启MymultispiderPipeline这个管道文件
ITEM_PIPELINES = { 'mymultispider.pipelines.MymultispiderPipeline': 300, # 'mymultispider.pipelines.Myspd1spiderPipeline': 300, # 'mymultispider.pipelines.Myspd2spiderPipeline': 300, # 'mymultispider.pipelines.Myspd3spiderPipeline': 300, }
2.3spider中屏蔽掉指定pipelines的相关代码
# -*- coding: utf-8 -*- import scrapy from mymultispider.items import Myspd1spiderItem class Myspd1Spider(scrapy.Spider): name = 'myspd1' allowed_domains = ['sina.com.cn'] start_urls = ['http://sina.com.cn/'] # custom_settings = { # 'ITEM_PIPELINES': {'mymultispider.pipelines.Myspd1spiderPipeline': 300}, # } def parse(self, response): print('myspd1') item = Myspd1spiderItem() item['name'] = 'myspd1的pipelines' yield item
2.4 运行crawl.py文件,结果如下
代码git地址:https://github.com/terroristhouse/crawler
python系列教程:
链接:https://pan.baidu.com/s/10eUCb1tD9GPuua5h_ERjHA
提取码:h0td
