【十八Spark Streaming实战】日志分析之Flume+Kafka+Spark Streaming+Hbase
【十七Spark Streaming实战】日志分析之用python生成日志
对接Python日志产生器输出的日志到Flume
1.编写flume agent的配置文件
在node1上进入flume目录
cd /app/flume/flume/conf
创建flume的agent配置文件
vi test-streaming-project.conf
#streaming-project
streaming-project.sources = exec-source
streaming-project.sinks = kafka-sink
streaming-project.channels = memory-channel
streaming-project.sources.exec-source.type = exec
streaming-project.sources.exec-source.command= tail -F /app/flume/testData/generateLog.log
streaming-project.sources.exec-source.shell = /bin/sh -c
streaming-project.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink
streaming-project.sinks.kafka-sink.topic = spark_topic
streaming-project.sinks.kafka-sink.brokerList = node1:9092
streaming-project.sinks.kafka-sink.requiredAcks = 1
streaming-project.sinks.kafka-sink.batchSize = 20
streaming-project.channels.memory-channel.type = memory
streaming-project.sources.exec-source.channels = memory-channel
streaming-project.sinks.kafka-sink.channel = memory-channel2.启动zookeeper集群
cd /app/zookeeper/bin
./zkServer.sh start
3.启动kafka
cd /app/kafka
bin/kafka-server-start.sh -daemon config/server.properties &
4.启动flume。
cd /app/flume/flume
bin/flume-ng agent --name streaming-project -c conf -f conf/test-streaming-project.conf -Dflume.root.logger=INFO,console
5.启动kafka消费端看是否能够接收到flume的数据。
cd /app/kafka
bin/kafka-console-consumer.sh --zookeeper node1:2181 --topic spark_topic

6.启动hadoop集群
cd /app/hadoop/hadoop-2.9.0/sbin
./start-all.sh
7.启动hbase集群
cd /app/hbase/bin
./start-hbase.sh
8.hbase创建表
./hbase shell 进入交互界面
create 'course_click_spark_streaming','info'
create 'course_search_clickcount','info'


9.项目目录
10.pom.xml
4.0.0
com.sid.spark
spark-train
1.0-SNAPSHOT
2008
2.11.8
0.9.0.0
2.2.0
2.6.0
1.2.0
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
scala-tools.org
Scala-Tools Maven2 Repository
http://scala-tools.org/repo-releases
org.scala-lang
scala-library
${scala.version}
org.apache.kafka
kafka_2.11
${kafka.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.slf4j
slf4j-log4j12
org.apache.hbase
hbase-client
${hbase.version}
org.apache.hbase
hbase-server
${hbase.version}
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.spark
spark-sql_2.11
${spark.version}
org.apache.spark
spark-streaming-flume_2.11
${spark.version}
org.apache.spark
spark-streaming-flume-sink_2.11
${spark.version}
org.apache.spark
spark-streaming-kafka-0-8_2.11
${spark.version}
net.jpountz.lz4
lz4
1.3.0
mysql
mysql-connector-java
5.1.31
org.apache.commons
commons-lang3
3.5
org.apache.flume.flume-ng-clients
flume-ng-log4jappender
1.6.0
src/main/scala
src/test/scala
org.scala-tools
maven-scala-plugin
compile
testCompile
${scala.version}
-target:jvm-1.5
org.apache.maven.plugins
maven-eclipse-plugin
true
ch.epfl.lamp.sdt.core.scalabuilder
ch.epfl.lamp.sdt.core.scalanature
org.eclipse.jdt.launching.JRE_CONTAINER
ch.epfl.lamp.sdt.launching.SCALA_CONTAINER
org.scala-tools
maven-scala-plugin
${scala.version}
11.代码
HBaseUtils.java
package com.sid.spark.project.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
/**
* HBase操作工具类:Java工具类建议采用单例模式封装
*/
public class HBaseUtils {
HBaseAdmin admin = null;
Configuration configuration = null;
/**
* 私有改造方法
*/
private HBaseUtils(){
configuration = new Configuration();
configuration.set("hbase.zookeeper.quorum", "node1:2181,node2:2181,node3:2181");
configuration.set("hbase.rootdir", "hdfs://hadoopcluster/hbase");
try {
admin = new HBaseAdmin(configuration);
} catch (IOException e) {
e.printStackTrace();
}
}
private static HBaseUtils instance = null;
public static synchronized HBaseUtils getInstance() {
if(null == instance) {
instance = new HBaseUtils();
}
return instance;
}
/**
* 根据表名获取到HTable实例
*/
public HTable getTable(String tableName) {
HTable table = null;
try {
table = new HTable(configuration, tableName);
} catch (IOException e) {
e.printStackTrace();
}
return table;
}
/**
* 添加一条记录到HBase表
* @param tableName HBase表名
* @param rowkey HBase表的rowkey
* @param cf HBase表的columnfamily
* @param column HBase表的列
* @param value 写入HBase表的值
*/
public void put(String tableName, String rowkey, String cf, String column, String value) {
HTable table = getTable(tableName);
Put put = new Put(Bytes.toBytes(rowkey));
put.add(Bytes.toBytes(cf), Bytes.toBytes(column), Bytes.toBytes(value));
try {
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
//HTable table = HBaseUtils.getInstance().getTable("imooc_course_clickcount");
//System.out.println(table.getName().getNameAsString());
String tableName = "course_click_spark_streaming'" ;
String rowkey = "20171111_88";
String cf = "info" ;
String column = "click_count";
String value = "2";
HBaseUtils.getInstance().put(tableName, rowkey, cf, column, value);
}
}
CourseClickCountDAO.scalapackage com.sid.spark.project.dao
import com.sid.spark.project.domain.CourseClickCount
import com.sid.spark.project.utils.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 实战课程点击数-数据访问层
*/
object CourseClickCountDAO {
val tableName = "course_click_spark_streaming"
val cf = "info"
val qualifer = "click_count"
/**
* 保存数据到HBase
* @param list CourseClickCount集合
*/
def save(list: ListBuffer[CourseClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for(ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
/**
* 根据rowkey查询值
*/
def count(day_course: String):Long = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_course))
val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)
if(value == null) {
0L
}else{
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseClickCount]
list.append(CourseClickCount("20171111_8",8))
list.append(CourseClickCount("20171111_9",9))
list.append(CourseClickCount("20171111_1",100))
save(list)
println(count("20171111_8") + " : " + count("20171111_9")+ " : " + count("20171111_1"))
}
}
CourseSearchClickCountDAO.scalapackage com.sid.spark.project.dao
import com.sid.spark.project.domain.{CourseClickCount, CourseSearchClickCount}
import com.sid.spark.project.utils.HBaseUtils
import org.apache.hadoop.hbase.client.Get
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
/**
* 从搜索引擎过来的实战课程点击数-数据访问层
*/
object CourseSearchClickCountDAO {
val tableName = "course_search_clickcount"
val cf = "info"
val qualifer = "click_count"
/**
* 保存数据到HBase
*
* @param list CourseSearchClickCount集合
*/
def save(list: ListBuffer[CourseSearchClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for(ele <- list) {
table.incrementColumnValue(Bytes.toBytes(ele.day_search_course),
Bytes.toBytes(cf),
Bytes.toBytes(qualifer),
ele.click_count)
}
}
/**
* 根据rowkey查询值
*/
def count(day_search_course: String):Long = {
val table = HBaseUtils.getInstance().getTable(tableName)
val get = new Get(Bytes.toBytes(day_search_course))
val value = table.get(get).getValue(cf.getBytes, qualifer.getBytes)
if(value == null) {
0L
}else{
Bytes.toLong(value)
}
}
def main(args: Array[String]): Unit = {
val list = new ListBuffer[CourseSearchClickCount]
list.append(CourseSearchClickCount("20171111_www.baidu.com_8",8))
list.append(CourseSearchClickCount("20171111_cn.bing.com_9",9))
save(list)
println(count("20171111_www.baidu.com_8") + " : " + count("20171111_cn.bing.com_9"))
}
}ClickLog.scalapackage com.sid.spark.project.domain
/**
* 清洗后的日志信息
* @param ip 日志访问的ip地址
* @param time 日志访问的时间
* @param courseId 日志访问的实战课程编号
* @param statusCode 日志访问的状态码
* @param referer 日志访问的referer
*/
case class ClickLog(ip:String, time:String, courseId:Int, statusCode:Int, referer:String)
CourseClickCount.scalapackage com.sid.spark.project.domain
/**
* 实战课程点击数实体类
* @param day_course 对应的就是HBase中的rowkey,20171111_1
* @param click_count 对应的20171111_1的访问总数
*/
case class CourseClickCount(day_course:String, click_count:Long)
CourseSearchClickCount.scalapackage com.sid.spark.project.domain
/**
* 从搜索引擎过来的实战课程点击数实体类
* @param day_search_course
* @param click_count
*/
case class CourseSearchClickCount(day_search_course:String, click_count:Long)
DateUtils.scalapackage com.sid.spark.project.utils
import java.util.Date
import org.apache.commons.lang3.time.FastDateFormat
/**
* 日期时间工具类
*/
object DateUtils {
val YYYYMMDDHHMMSS_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
val TARGE_FORMAT = FastDateFormat.getInstance("yyyyMMddHHmmss")
def getTime(time: String) = {
YYYYMMDDHHMMSS_FORMAT.parse(time).getTime
}
def parseToMinute(time :String) = {
TARGE_FORMAT.format(new Date(getTime(time)))
}
def main(args: Array[String]): Unit = {
println(parseToMinute("2017-10-22 14:46:01"))
}
}
StatStreamingApp.scalapackage com.sid.spark.project.spark
import com.sid.spark.project.dao.{CourseClickCountDAO, CourseSearchClickCountDAO}
import com.sid.spark.project.domain.{ClickLog, CourseClickCount, CourseSearchClickCount}
import com.sid.spark.project.utils.DateUtils
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
/**
* 使用Spark Streaming处理Kafka过来的数据
*/
object StatStreamingApp {
def main(args: Array[String]): Unit = {
if (args.length != 4) {
println("Usage: StatStreamingApp ")
System.exit(1)
}
val Array(zkQuorum, groupId, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("StatStreamingApp") .setMaster("local[5]")
val ssc = new StreamingContext(sparkConf, Seconds(60))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val messages = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap)
// 测试步骤一:测试数据接收
messages.map(_._2).count().print
// 测试步骤二:数据清洗
val logs = messages.map(_._2)
val cleanData = logs.map(line => {
val infos = line.split("\t")
// infos(2) = "GET /class/130.html HTTP/1.1"
// url = /class/130.html
val url = infos(2).split(" ")(1)
var courseId = 0
// 把实战课程的课程编号拿到了
if (url.startsWith("/class")) {
val courseIdHTML = url.split("/")(2)
courseId = courseIdHTML.substring(0, courseIdHTML.lastIndexOf(".")).toInt
}
ClickLog(infos(0), DateUtils.parseToMinute(infos(1)), courseId, infos(3).toInt, infos(4))
}).filter(clicklog => clicklog.courseId != 0)
cleanData.print()
// 测试步骤三:统计今天到现在为止实战课程的访问量
cleanData.map(x => {
// HBase rowkey设计: 20171111_88
(x.time.substring(0, 8) + "_" + x.courseId, 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitionRecords => {
val list = new ListBuffer[CourseClickCount]
partitionRecords.foreach(pair => {
list.append(CourseClickCount(pair._1, pair._2))
})
println("写入HBase"+list)
CourseClickCountDAO.save(list)
})
})
// 测试步骤四:统计从搜索引擎过来的今天到现在为止实战课程的访问量
cleanData.map(x => {
// * https://www.sogou.com/web?query=Spark SQL实战
// *
// * ==>
// * https:/www.sogou.com/web?query=Spark SQL实战
val referer = x.referer.replaceAll("//", "/")
val splits = referer.split("/")
var host = ""
if(splits.length > 2) {
host = splits(1)
}
(host, x.courseId, x.time)
}).filter(_._1 != "").map(x => {
(x._3.substring(0,8) + "_" + x._1 + "_" + x._2 , 1)
}).reduceByKey(_ + _).foreachRDD(rdd => {
rdd.foreachPartition(partitionRecords => {
val list = new ListBuffer[CourseSearchClickCount]
partitionRecords.foreach(pair => {
list.append(CourseSearchClickCount(pair._1, pair._2))
})
CourseSearchClickCountDAO.save(list)
})
})
ssc.start()
ssc.awaitTermination()
}
}
12.运行

本地跑通后用maven编译生成jar包放到服务器上运行
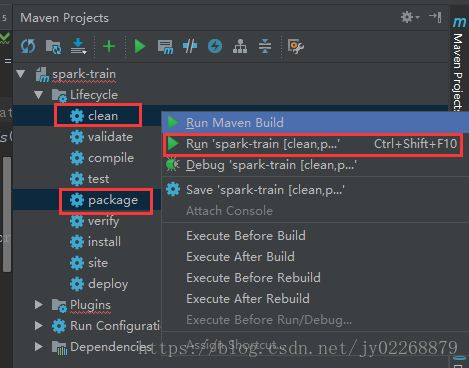
编译失败
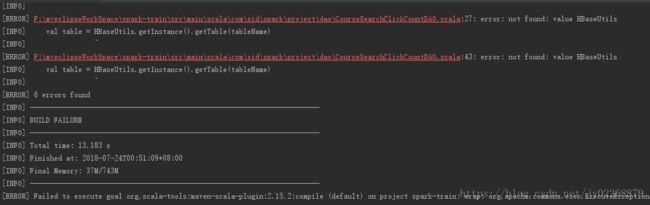
解决:

把pom.xml文件中
重新编译

把生成到target下面的jar包传到服务器上运行
cd /app/spark/spark-2.2.0-bin-2.9.0/bin
./spark-submit --class com.sid.spark.project.spark.StatStreamingApp --master local[5] --name StatStreamingApp /app/spark/test_data/spark-train-1.0-SNAPSHOT.jar node1:2181,node2:2181,node3:2181 test spark_topic 1
报错
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka/KafkaUtils$
at com.sid.spark.project.spark.StatStreamingApp$.main(StatStreamingApp.scala:31)
at com.sid.spark.project.spark.StatStreamingApp.main(StatStreamingApp.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:755)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:119)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.streaming.kafka.KafkaUtils$
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 11 more
解决:
因为我们maven不是打的胖包,在执行的时候需要用--packages把kafka的包引进来。
重新运行:
cd /app/spark/spark-2.2.0-bin-2.9.0/bin
./spark-submit --class com.sid.spark.project.spark.StatStreamingApp --master local[5] --name StatStreamingApp --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 /app/spark/test_data/spark-train-1.0-SNAPSHOT.jar node1:2181,node2:2181,node3:2181 test spark_topic 1
报错
java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/client/HBaseAdmin
at com.sid.spark.project.utils.HBaseUtils.(HBaseUtils.java:29)
at com.sid.spark.project.utils.HBaseUtils.getInstance(HBaseUtils.java:39)
at com.sid.spark.project.dao.CourseSearchClickCountDAO$.save(CourseSearchClickCountDAO.scala:27)
at com.sid.spark.project.spark.StatStreamingApp$$anonfun$main$9$$anonfun$apply$3.apply(StatStreamingApp.scala:102)
at com.sid.spark.project.spark.StatStreamingApp$$anonfun$main$9$$anonfun$apply$3.apply(StatStreamingApp.scala:95)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:926)
at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:926)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2062)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2062)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87)
at org.apache.spark.scheduler.Task.run(Task.scala:108)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
解决:
原因和上一个报错类似,因为maven打的不是胖包,找不到HBase相关的jar
这次用--jars 把hbase/lib下的jar包都引进来
重新运行:
cd /app/spark/spark-2.2.0-bin-2.9.0/bin
./spark-submit --jars $(echo /app/hbase/lib/*.jar | tr ' ' ',') --class com.sid.spark.project.spark.StatStreamingApp --master local[5] --name StatStreamingApp --packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.2.0 /app/spark/test_data/spark-train-1.0-SNAPSHOT.jar node1:2181,node2:2181,node3:2181 test spark_topic 1
数据采集+实时分析+入库已完成。
数据可视化展示:Spring Boot+Echarts+HBase绘制动态数据饼图