GNN中的Graph Pooling
前言
GNN/GCN在非欧数据中的应用具有极大的挖掘价值。通常,GNN的应用分为两种:1,节点分类;2,图分类。
节点分类可以用在点云分割,社交网络节点分类,推荐算法等等。
图分类可以用在姿态估计,蛋白质分类等等,当然,也可以用在图像分类。
对于节点分类而言,图结构在forward阶段是不会改变的,改变的只是节点的隐藏层属性。如下:
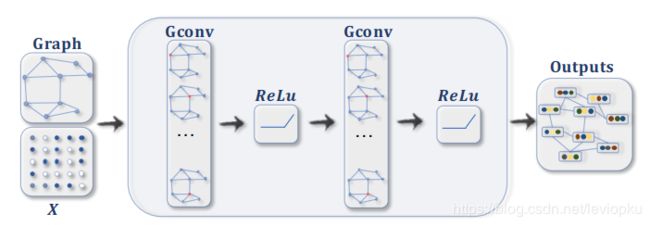
对于图分类而言,图结构在前传的时候会downsize,最后聚合成一个点的feature再做MLP:

截图来自论文:https://arxiv.org/abs/1901.00596
图分类所用的downsize便是本文的主角graph pooling。--终于引出来了..
Graph Pooling
GNN/GCN 最先火的应用是在Node classification,然后先富带动后富,Graph classification也越来越多人研究。所以,Graph Pooling的研究其实是起步比较晚的。
Pooling就是池化操作,熟悉CNN的朋友都知道Pooling只是对特征图的downsampling。不熟悉CNN的朋友请按ctrl+w。对图像的Pooling非常简单,只需给定步长和池化类型就能做。但是Graph pooling,会受限于非欧的数据结构,而不能简单地操作。
简而言之,graph pooling就是要对graph进行合理化的downsize。
目前有三大类方法进行graph pooling:
1. Hard rule
hard rule很简单,因为Graph structure是已知的,可以预先规定池化节点:
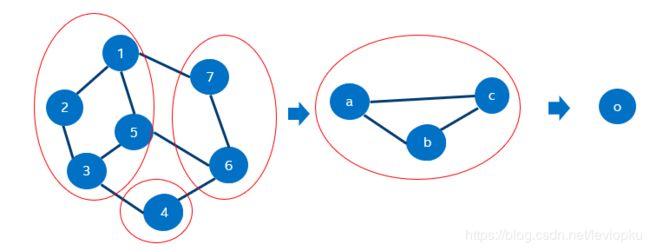
如图,咱们预先规定[1,2,3,5]节点,[6,7]节点和[4]节点合并,得到新的a,b,c节点。这便是硬规定下的池化方法。比较好理解。
2. Graph coarsening
图粗略化是现在的主流可学习池化方法之一。
代表论文:DiffPool
论文链接:https://arxiv.org/abs/1806.08804

这种方法是hard rule的trainable版本,先对节点进行聚类,然后合成一个超级节点,以达到池化效果。
思想流程大概是:soft clustering -> super node -> coarsening
3. Node selection
节点选择就是选择一些重要节点去代替原图:
代表论文:self-attention graph pooling
论文链接:https://arxiv.org/pdf/1904.08082.pdf

这个self-attention类似于分析节点的重要性,方法类似节点分类的操作。