编译原理(一)
什么是编译程序?
编译程序(Compiler):
把某一种高级语言程序等价地转换成另一种低级语言程序(如汇编语言或机器语言程序)的程序。
解释程序(Interpreter):
把源语言写的源程序作为输入,但不产生目标程序,而是边解释边执行源程序。
编译过程
编译过程分为6个阶段分别是:词法分析、语法分析、语义分析、中间代码产生、优化、目标代码生成。
词法分析
词法分析是编译过程的第一个阶段。这个阶段的任务是输入源程序,对构成源程序的字符串进行扫描和分解,识别出单词符号。再依据构词规则把单词符号分为标识符、保留字、算符、界符等。
语法分析
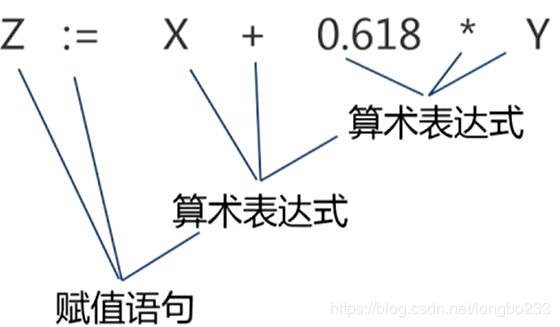
语法分析是编译过程的第二个阶段。这个阶段的任务是在词法分析的基础上将单词序列分解成各类语法单位,如“程序”、“语句”、“表达式”等。这种语法短语也称为语法单位,可以表示成语法树:
语义分析
语义分析是审查源程序有无语义错误,为代码生成阶段收集类型信息。例如,语义分析的一个工作是进行类型审查,审查每个算符是否具有语言规范允许的运算对象,当不符合语言规范时,编译程序应报告错误。
语义检查:
1.变量或过程未经声明就使用
2.变量或过程名重复声明
3.运算分量类型不匹配
4.操作符与操作数之间的类型不匹配
5.数组下标不是整数
6.对非数组变量使用数组访问操作符
7/对非过程名使用过程调用操作符
8.过程调用的参数类型或数目不匹配
9.函数返回类型有误
收集类型信息:
1.种属(Kind):简单变量,复合变量(数组,记录,…),过程,…
2.类型(Type):整型,实型,字符型,布尔型,指针型,…
3.存储位置、长度、值、作用域
中间代码生成
中间代码生成是编译过程的第四个阶段。这个阶段的任务是对各类语法单位按语言的语义进行初步翻译生成中间代码。
中间代码的设计原则主要有两点:1.容易生成;2.容易将它翻译成目标代码
很多编译程序采用了一种近似“三地址指令”的“四元式”中间代码形式为:
(运算符,运算对象1,运算对象2,结果)
z:=X+0.618*Y
| 序号 | 运算符 | 运算对象1 | 运算对象2 | 结果 | 注释 |
|---|---|---|---|---|---|
| 1 | * | 0.618 | Y | T1 | T1:=0.618*Y |
| 2 | + | X | T1 | T2 | T2:=X+T1 |
| 3 | = | T2 | Z | Z:=T2 |
优化
优化是编译过程的第五个阶段。这个阶段的任务是对前阶段产生的中间代码进行加工变换,以期在最后阶段产生更高效的目标代码,即省时间,省空间。
它依循的原则是程序的等价变换规则,列如以下代码:
FOR K:=1 TO 100 DO
BEGIN
X:=I+1;
M:=I+10*K;
N:=J+10*K;
END
已知K为1,M、N每次运算实质上就是加10,可将M、N优化为:
M:=I+10;
N:=J+10;
目标代码产生
它的任务是把中间代码变换成特定机器上的目标代码,它的工作依赖于硬件系统结构和机器指令的含义。
目标代码三种形式
1.汇编指令代码:需要进行汇编
2.绝对指令代码:可直接运行
3.可重新定位指令代码:需要链接
编译程序的结构
编译过程的6个阶段的任务可以分别由6个模块完成,分别称作词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、代码优化程序和目标代码生成程序。此外,一个完整的编译程序还必须包括表格管理程序和出错处理程序。下图是将语义分析程序、中间代码生成程序合成一个模块:
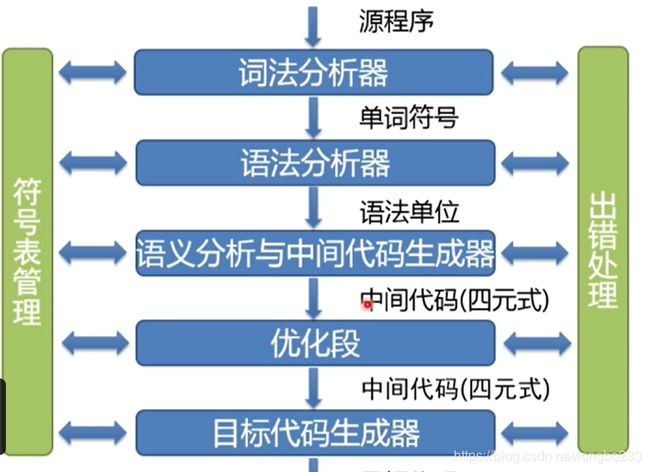
表格管理和出错处理与这6个阶段都有联系,编译过程中源程序的各种信息被保留在种种不同的表格里,编译各阶段的工作都涉及构造、查找或更新有关的表格,因此需要有表格管理的工作。
出错处理
出错处理程序:发现源程序中的错误,把有关错误信息报告给用户
语法错误:
1.源程序中不符合语法(或词法)规则的错误
2.非法字符、括号不匹配、缺少;……
语义错误:
1.源程序中不符合语义规则的错误
2.说明错误、作用域错误、类型不一致;……
编译阶段的组合
编译前端
与源语言有关,如词法分析,语法分析,语义分析与中间代码产生,与机器无关的优化
编译后端
与目标机有关,与目标机有关的优化,目标代码产生
带来的好处
程序逻辑结构清晰
优化更充分,有利于移植
遍(pass)
所谓“遍”就是对源程序或源程序的中间表示从头到尾扫描一次
阶段与遍是不同的概念:
一遍可以由若干段组成
一个阶段也可以分若干遍来完成