Flink介绍
本文开头附:Flink 学习路线系列 ^ _ ^
随着5G时代的到来,未来都将会是万物互联,各种各样的设备都会与网络连接起来。未来有无人驾驶、很多的设备都能接入到5G,会有大量的数据产生。
以后这些数据都将需要做实时分析,有人把Flink归类为第三代大数据引擎。第一代:Hadoop、第二代:Spark 。
1.什么是 Flink
Flink官网:https://flink.apache.org/
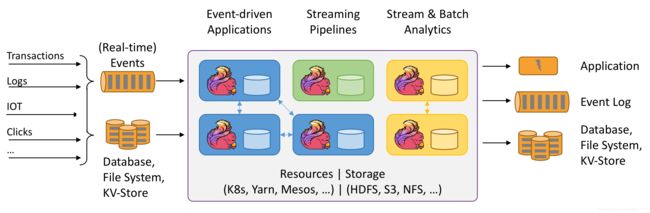
Apache Flink 是一个分布式大数据处理引擎,可对1.有限数据流和2.无线数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
名词解释:
有限数据流:即数据已经产生,数据大小已经确定。数据有限,可以做离线计算;无限数据流:即数据流一旦产生,不知道什么时候结束。比如:数据实时写入到Kafka。数据无限,可以做实时计算。
1.1.Flink设计初衷
Flink 设计之初,就是为实时计算而设计的。但是因为其计算引擎过于强大,所以也可以做离线计算。它可以部署在各种各样的集群中,比如 Flink自己的 standalone 集群,flink on yarn部署,Flink 还可以跑在K8S上,Flink 还可以跑在各种各样的集群上。Flink为了开发测试比较方便,还可以使用单机模式。可以对各种大小规模的数据进行快速计算。特点就是:快。
1.2.Flink历史介绍
早在 2008年,Flink 的前身已经是柏林理工大学一个研究性项目,在 2014 年被 Apache 孵化器所接受,然后迅速成为了 ASF(Apache Software Foundation)的顶级项目之一。
Flink 的商业母公司 Data Artisans,位于柏林,公司成立于 2014年,共获得两轮融资共计 650万欧,该公司旨在为企业提供大规模数据处理解决方案,使企业可以管理和部署实时数据,实时反馈数据,做更快、更精准的商业决策。
目前,ING,Netflix 和 Uber 等企业也都通过 Apache Flink 平台部署大规模分布式应用,如实时数据分析、机器学习、搜索、排序推荐和欺诈风险等。
2019年1月8日,阿里巴巴以9000万欧元收购 Data Artisans 公司。从此以后,Flink 的控制权就掌握在了阿里手中。
1.3.Logo介绍

在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为Logo,这不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色,而 Flink 的松鼠 Logo 拥有可爱的尾巴,尾巴的颜色与Apache软件基金会的logo颜色相呼应(Apache logo鸡毛掸子和松鼠尾巴相结合),也就是说,这是一只具有 Apache 风格的松鼠。
2.Flink特点
- 批流统一
- 支持高吞吐、低延迟、高性能的流处
- 支持带有事件事件的窗口(Window)操作
- 支持有状态计算的 Exactly-once 语义
- 支持高度灵活的窗口(Window)操作,支持基于 time、count、session 窗口操作
- 支持具有 Backpressure 功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 支持迭代计算
- Flink 在 JVM内部实现了自己的内存管理
- 支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存。
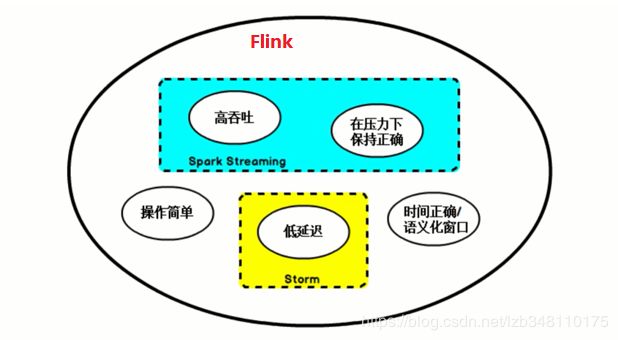
3.Flink 与其他框架的对比
| 框架 | 优点 | 缺点 |
|---|---|---|
| Storm | 低延迟 | 吞吐量第、不能保证 exactly-once、编程 API 不丰富 |
| Spark Streaming | 吞吐量高、可以保证 exactly-once、编程 API 丰富 | 延迟较高 |
| Storm | 低延迟、吞吐量高、可以保证 exactly-once、编程API丰富(具有Storm+Spark优势) | 快速迭代中,API 变化比较快 |
Spark
Spark 就是为离线计算而设计的,在Spark生态体系中,不论是流处理还是批处理,底层引擎都是Spark Core。Spark Streaming 将微批次小任务不停地提交到 Spark 引擎,从而实现准实时计算,Spark Streaming 只不过是一种特殊的批处理而已。
Flink
Flink 就是为实时计算而设计的,Flink 可以同时实现批处理和流处理,Flink 将批处理(即有界数据/离线处理)视作一种特殊的流处理。
Flink 部署,可以使用本地Local模式,也可以使用Cluster集群模式(可以部署 standalone,yarn上,也可以部署在cloud 云上)。
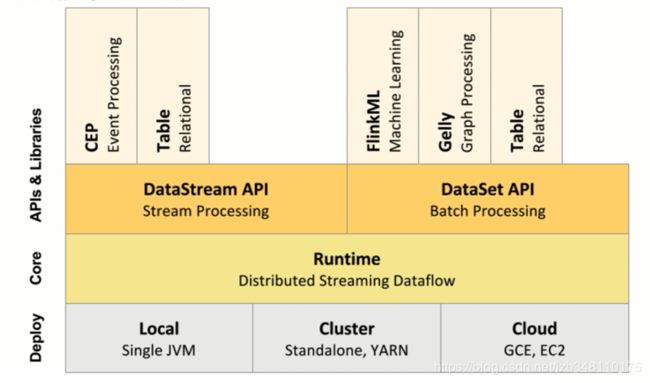
4.Flink 架构体系简介
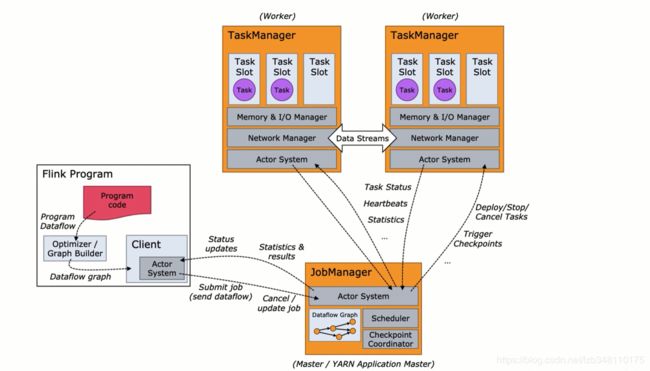
Flink 真正用来做执行操作的,叫做 Worker。进程在不同的环境模式下运行,进程名称不同。如:使用 Standalone集群模式启动,JobManager 叫做 StandaloneSessionClusterEntrypoint,TaskManager叫做 TaskManagerRunner,使用 yarn 集群启动,进程名称又会有所不同。
JobManager介绍:
也称之为 Master,用于协调分布式执行,它用来调度 Task,协调检查点,协调失败时恢复等。Flink 运行时至少存在一个 Master,如果配置高可用模式则会存在多个 Master,他们其中有一个是 Leader,而其他的都是 Standby。
TaskManager介绍:
也称之为 Worker,用于执行一个 dataflow 的 Task、数据缓冲 和 Data Stream 的数据交换,Flink 运行时至少会存在一个 TaskManager。JobManager 和 TaskManager 可以直接运行在物理机上,或者运行在 yarn 这样的资源调度框架。TaskManager 通过网络连接到JobManager,通过 RPC 通信告知自身的可用性进而获得任务分配。
Flink架构流程介绍:
用于工作的叫做 TaskManager(又叫:Worker)。TaskManager 里面以后运行着Task(又叫:subTask)。TaskSlot 中就会运行着真正计算的任务 Task。
TaskManager 相当于用来给 Task 提供执行环境。JobManager相当于是主节点,TaskManager相当于是从节点。JobManager用来负责管理,TaskManager用来负责执行具体的Task,他们之间也要通过网络进行RPC通信。RPC通信,底层使用的是Akka。 我们还会用到一个客户端。这个客户端用来提交任务(左图中的Client)。
客户端提交任务,首先会与 JobManager 进行通信。我们在本地写程序。程序中会构建成一个类似于 Spark 的 DAG(Flink 中叫做Dataflow graph),将 Dataflow graph 提交到 JobManager。JobManager 会把这个Dataflow graph 切分成多个 Task。将 Task 调度到TaskManager中进行执行。(和Spark很相似)
使用客户端提交任务,①可以通过命令来提交 ②也可以通过 Web 页面提交。
5.Sprak 和 Flink角色对比
| 含义 | Spark | Flink |
|---|---|---|
| 离散流 | DStream | DataStream |
| 算子 | Transformation | Transformation |
| Action类算子(xxxx预留) | Action | Sink |
| 任务 | Task | SubTask |
| 流水线 | Pipeline | Oprator chains |
| 有向无环图(Directed Acyclic Graph) | DAG | DataFlow Graph |
| xxxx预留 | Master + Driver | JobManager |
| xxxx预留 | Worker+ Executor | TaskManager |
博主写作不易,来个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
博主不能保证写的所有知识点都正确,但是能保证纯手敲,错误也请指出,望轻喷 Thanks♪(・ω・)ノ