Flink常用算子Transformation介绍
本文开头附:Flink 学习路线系列 ^ _ ^
1.算子介绍
Flink中的算子,是对 DataStream 进行操作,返回一个新的 DataStream 的过程。Transformation 过程,是将一个或多个 DataStream 转换为新的 DataStream,可以将多个转换组合成复杂的数据流拓扑
Transformation:指数据转换的各种操作。有 map / flatMap / filter / keyBy / reduce / fold / aggregations / window / windowAll / union / window join / split / select / project 等,操作有很多中凡是,可以将数据转换计算成你想要的数据。
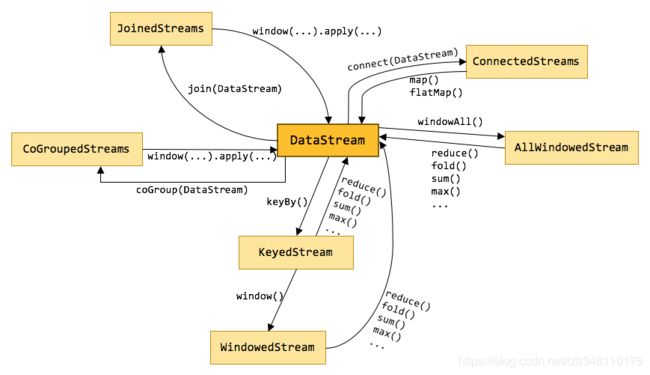
在Flink中,有多种不同的 DataStream 类型,他们之间就是使用各种算子来进行转换的。如下图所示:
2.官方文档
附:Flink算子Transformation介绍,我是官方文档(英文版)
3.常用算子介绍
本文使用 JDK8新特性:Lambda 表达式来介绍 Flink 中常用算子使用。如果你还不了解 JDK8 新特性,请点击了解了解: 我是链接 。
如需了解 Lambda表达式的使用,你也可以点击以下链接具体了解:JDK8新特性:Lambda表达式
3.1 map()
映射函数。即:取出一个元素,根据规则处理后,并产生一个元素。可以用来做一些数据清洗的工作。
类型转换:
DataStream → DataStream
场景:使用 java.util.Collection 创建一个数据流,并将数据流中的数据 * 2,并输出。
/**
* TODO map()方法操作
*
* @author liuzebiao
* @Date 2020-2-8 13:49
*/
public class MapDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建数据流
DataStreamSource<Integer> dataStream = env.fromElements(1, 2, 3, 4, 5);
//将Stream流中的数据 *2
SingleOutputStreamOperator<Integer> operator = dataStream.map(num -> num * 2).returns(Types.INT);
operator.print();
env.execute("MapDemo");
}
}
3.2 flatMap()
拆分压平。即:取出一个元素,并产生零个、一个或多个元素。
flatMap 和 map 方法的使用相似,但是因为一般 Java 方法的返回值结果都是一个,引入 flatMap 后,我们可以将处理后的多个结果放到一个 Collections 集合中(类似于返回多个结果)。
类型转换:
DataStream → DataStream
场景:使用 java.util.Collection 创建一个数据流,并将数据流中以 “S” 开头的数据返回。
/**
* TODO flatMap()方法操作
*
* @author liuzebiao
* @Date 2020-2-9 10:49
*/
public class FlatMapDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建数据流
DataStreamSource<String> dataStreamSource = env.fromElements("Hadoop Flink Storm HBase", "Spark Tomcat Spring MyBatis", "Sqoop Flume Docker K8S Scala");
//将Stream流中以 "S" 开头的数据,输出到 Collectior 集合中
SingleOutputStreamOperator<String> streamOperator = dataStreamSource.flatMap((String line, Collector<String> out) -> {
Arrays.stream(line.split(" ")).forEach( str ->{
if (str.startsWith("S")) {
out.collect(str);
}
});
}).returns(Types.STRING);
streamOperator.print();
env.execute("FlatMapDemo");
}
}
3.3 filter()
过滤。即:为取出的每个元素进行规则判断(返回true/false),并保留该函数返回 true 的数据。
类型转换:
DataStream → DataStream
场景:使用 java.util.Collection 创建一个数据流,并将数据流中以 “S” 开头的数据返回。
/**
* TODO filter()方法操作
*
* @author liuzebiao
* @Date 2020-2-9 11:26
*/
public class FilterDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//创建数据流
DataStreamSource<String> dataStreamSource = env.fromElements("Hadoop", "Spark", "Tomcat", "Storm", "Flink", "Docker", "Hive", "Sqoop" );
//将Stream流中以 "S" 开头的数据,输出
SingleOutputStreamOperator<String> streamOperator = dataStreamSource.filter(str -> str.startsWith("S")).returns(Types.STRING);
streamOperator.print();
env.execute("FilterDemo");
}
}
3.4 keyBy()
按 key 进行分组,key相同的(一定)会进入到同一个组中。具有相同键的所有记录都会分配给同一分区。在内部,keyBy() 是通过哈希分区实现的,有多种指定密钥的方法。
此转换返回一个
KeyedStream。使用 keyBy 进行分区,分为以下下两种情况:
- POJO类型:以 “属性名” 进行分组(
属性名错误或不存在,会提示错误)- Tuple(元组)类型:以“0、1、2”等进行分组(角标从0开始)
eg:
dataStream.keyBy(“someKey”) // Key by field “someKey”
dataStream.keyBy(0) // Key by the first element of a Tuple
keyBy() ,也支持以多个字段进行分组。 例如:①keyBy(0,1):Tuple形式以第1和第2个字段进行分组 ②keyBy(“province”,“city”):POJO形式以"province"和"city"两个字段进行分组。多字段分组使用方法,与单个字段分组类似。单个字段分组实例Demo,请往下查看例子。
类型转换:
DataStream → KeyedStream
场景:通过 Socket 方式,实时获取输入的数据,并对数据流中的单词进行分组求和计算(如何通过Socket输入数据,请参考:Java编写实时任务WordCount)
3.4.1 POJO(实体类)方式 keyBy(使用属性 keyBy)
/**
* TODO WordCount POJO实体类
*
* @author liuzebiao
* @Date 2020-2-9 15:04
*/
public class WordCount {
public String word;
public int count;
public WordCount() {
}
public WordCount(String word, int count) {
this.word = word;
this.count = count;
}
//of()方法,用来生成 WordCount 类(Flink源码均使用of()方法形式,省去每次new操作。诸如:Tuple2.of())
public static WordCount of(String word,int count){
return new WordCount(word, count);
}
@Override
public String toString() {
return "WordCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
/**
* TODO keyBy()方法操作(POJO实体类形式)
*
* @author liuzebiao
* @Date 2020-2-9 15:06
*/
public class KeyByDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//通过Socket实时获取数据
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//将数据转换成 POJO 实体类形式
SingleOutputStreamOperator<WordCount> streamOperator = lines.flatMap((String line, Collector<WordCount> out) -> {
Arrays.stream(line.split(" ")).forEach(str -> out.collect(WordCount.of(str, 1)));
}).returns(WordCount.class);
//keyBy()以属性名:word 进行分组
KeyedStream<WordCount, Tuple> keyedStream = streamOperator.keyBy("word");
//sum()以属性名:count 进行求和
SingleOutputStreamOperator<WordCount> summed = keyedStream.sum("count");
summed.print();
env.execute("KeyByDemo");
}
}
返回结果:
7> WordCount{word='Storm', count=1}
8> WordCount{word='Flink', count=1}
8> WordCount{word='Spark', count=1}
8> WordCount{word='Docker', count=1}
7> WordCount{word='Scala', count=1}
8> WordCount{word='Flink', count=2}
8> WordCount{word='Flink', count=3}
8> WordCount{word='Flink', count=4}
8> WordCount{word='Spark', count=2}
3.4.2 Tuple(元组)方式 keyBy(使用下标 keyBy)
/**
* TODO keyBy()方法操作(Tuple 元组形式)
*
* @author liuzebiao
* @Date 2020-2-9 14:38
*/
public class KeyByDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//通过Socket实时获取数据
DataStreamSource<String> dataSource = env.socketTextStream("localhost", 8888);
//将数据转换成元组(word,1)形式
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = dataSource.flatMap((String lines, Collector<Tuple2<String, Integer>> out) -> {
Arrays.stream(lines.split(" ")).forEach(word -> out.collect(Tuple2.of(word, 1)));
}).returns(Types.TUPLE(Types.STRING, Types.INT));
//keyBy()以下标的形式,进行分组
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = streamOperator.keyBy(0);
//sum()以下标的形式,对其进行求和
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyedStream.sum(1);
summed.print();
env.execute("KeyByDemo");
}
}
返回结果:
8> (Flink,1)
8> (Spark,1)
7> (Storm,1)
8> (Docker,1)
7> (Scala,1)
8> (Flink,2)
8> (Flink,3)
8> (Flink,4)
8> (Spark,2)
3.5 reduce()
归并操作。如果需要将数据流中的所有数据,归纳得到一个数据的情况,可以使用 reduce() 方法。如果需要对数据流中的数据进行求和操作、求最大/最小值等(都是归纳为一个数据的情况),此处就可以用到 reduce() 方法
reduce() 返回单个的结果值,并且 reduce 操作每处理一个元素总是会创建一个新的值。常用的聚合操作例如 min()、max() 等都可使用 reduce() 方法实现。Flink 中未实现的 average(平均值), count(计数) 等操作,也都可以通过 reduce()方法实现。
类型转换:
KeyedStream → DataStream
场景:通过 Socket 方式,实时获取输入的数据,并对数据流中的单词进行分组,分组后进行 count 计数操作。(如何通过Socket输入数据,请参考:Java编写实时任务WordCount)
/**
* TODO reduce()方法操作
*
* @author liuzebiao
* @Date 2020-2-9 17:11
*/
public class ReduceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//通过Socket实时获取数据
DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<Tuple2<String, Integer>> streamOperator = dataStreamSource.map(str -> Tuple2.of(str, 1)).returns(Types.TUPLE(Types.STRING,Types.INT));
//keyBy() Tuple元组以下标的形式,进行分组
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = streamOperator.keyBy(0);
//对分组后的数据进行 reduce() 操作
//old,news 为两个 Tuple2类型(通过f0,f1可以获得相对应下标的值)
SingleOutputStreamOperator<Tuple2<String, Integer>> count = keyedStream.reduce((old, news) -> {
old.f1 += news.f1;
return old;
}).returns(Types.TUPLE(Types.STRING, Types.INT));
count.print();
env.execute("ReduceDemo");
}
}
返回结果:
8> (hadoop,1)
7> (flink,1)
8> (hadoop,2)
8> (hadoop,3)
8> (hadoop,4)
8> (hadoop,5)
7> (flink,2)
3.6 sum()、min() 、minBy()、max()、maxBy()
sum():求和
min():返回最小值 max():返回最大值(指定的field是最小,但不是最小的那条记录)
minBy(): 返回最小值的元素 maxBy(): 返回最大值的元素(获取的最小值,同时也是最小值的那条记录)
类型转换:
KeyedStream → DataStream
场景:通过 Socket 方式,实时获取输入的数据,并对数据流中的单词进行分组,分组后进行 sum() 求和计数(min()、max() 方法,同 sum() 的使用相同)。请参考:Java编写实时任务WordCount
3.7 fold()
一个有初始值的分组数据流的滚动折叠操作。合并当前元素和前一次折叠操作的结果,并产生一个新的值。
类型转换:
KeyedStream → DataStream
fold() 方法只是对分组中的数据进行折叠操作。比如有 3 个分组,然后我们通过如下代码来完成对分组中数据的折叠操作。分组如下:
组1:【11,22,33,44,55】
组2:【88】
组3:【98,99】
代码如下:
DataStream<String> result =
keyedStream.fold("start", new FoldFunction<Integer, String>() {
@Override
public String fold(String current, Integer value) {
return current + "-" + value;
}
});
最终折叠后的结果为:
组1:【start-11、start-11-22、start-11-22-33、start-11-22-33-44、start-11-22-33-44-55】
组2:【start-88】
组3:【start-98、start-98-99】
总结:
fold() 方法,只会对本分组中的数据进行折叠操作,如果当前分组结束开始操作下一个分组,那么折叠操作将会重新开始。
附:Demo
/**
* TODO fold()方法操作
*
* @author liuzebiao
* @Date 2020-2-10 9:00
*/
public class FoldDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> source = env.fromElements(11, 11, 11, 22, 33, 44, 55);
SingleOutputStreamOperator<Tuple2<Integer, Integer>> streamOperator = source.map(num ->Tuple2.of(num,1)).returns(Types.TUPLE(Types.INT,Types.INT));
KeyedStream<Tuple2<Integer, Integer>, Tuple> keyedStream = streamOperator.keyBy(0);
DataStream<String> result = keyedStream.fold("start",(current,tuple) ->current + "-" + tuple.f0).returns(Types.STRING);
result.print();
env.execute("FoldDemo");
}
}
分组后:
组1:【11, 11, 11】
组2:【22】
组3:【33】
组4:【44】
组5:【55】
返回结果:
7> start-11
7> start-11-11
7> start-11-11-11
3> start-22
2> start-33
1> start-44
8> start-55
3.8 union()
在 DataStream 上使用 union 算子可以合并多个同类型的数据流,并生成同类型的新数据流,即可以将多个 DataStream 合并为一个新的 DataStream。数据将按照先进先出(First In First Out) 的模式合并,且不去重。
图示:

类型转换:
DataStream → DataStream
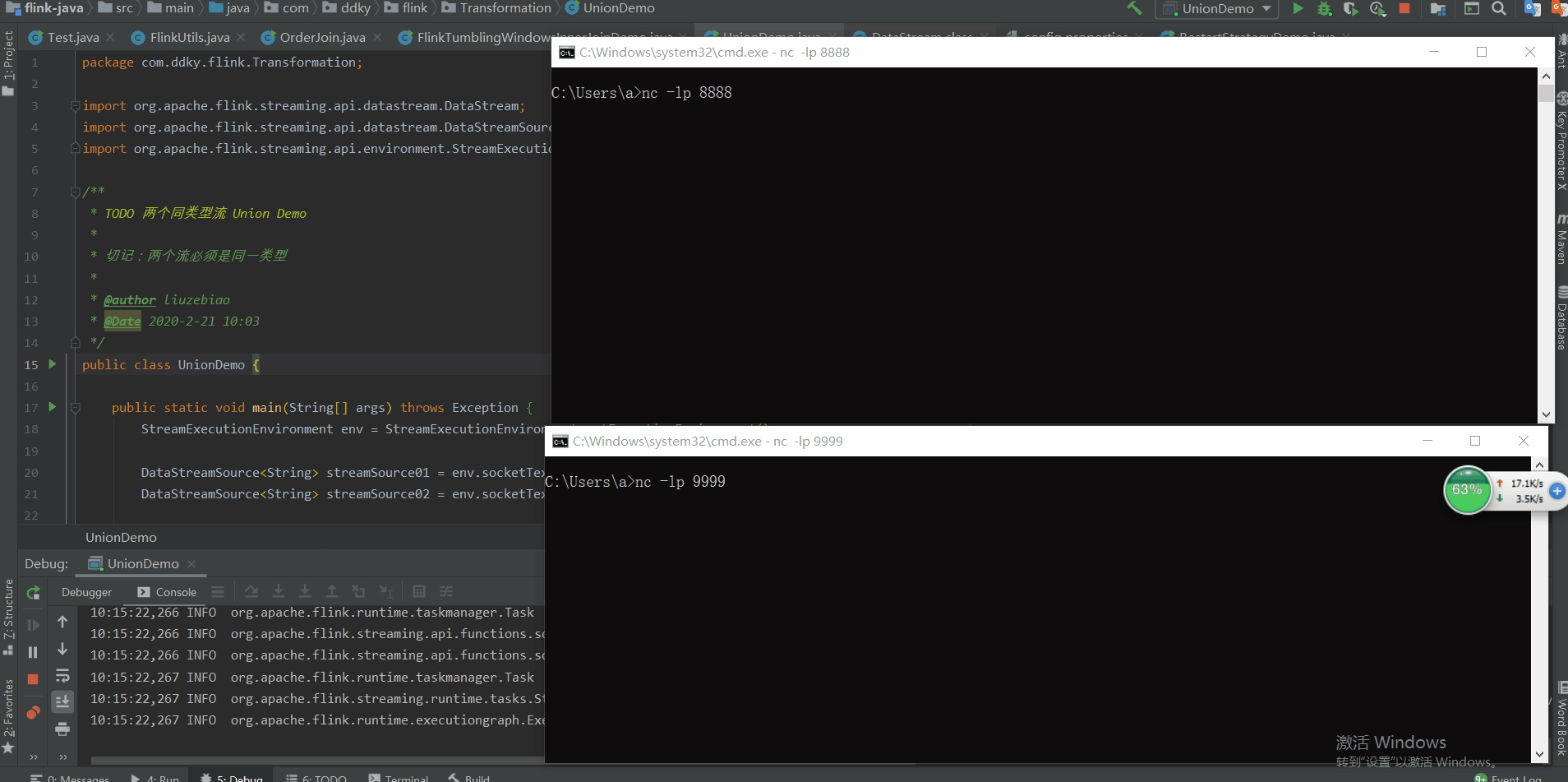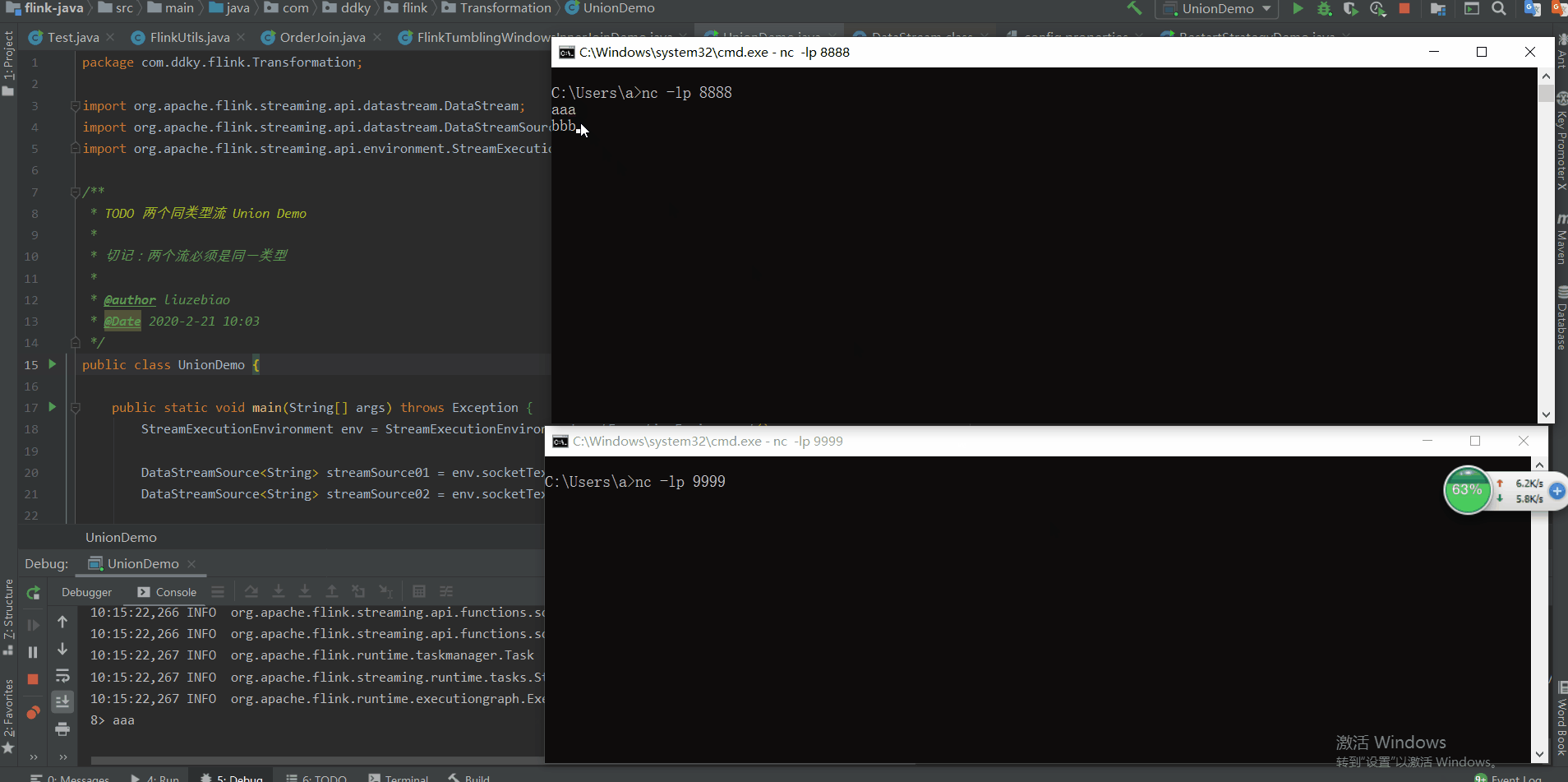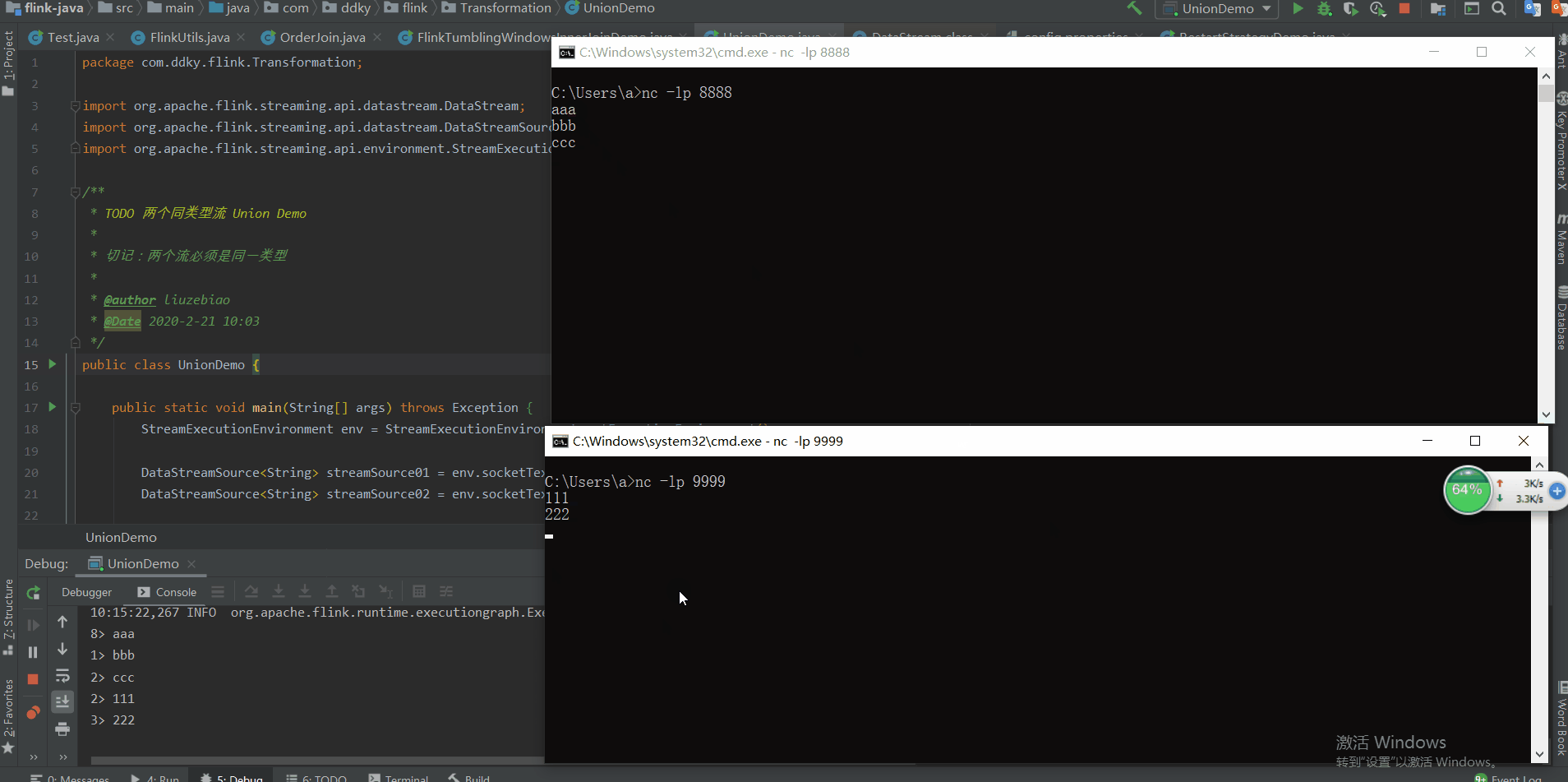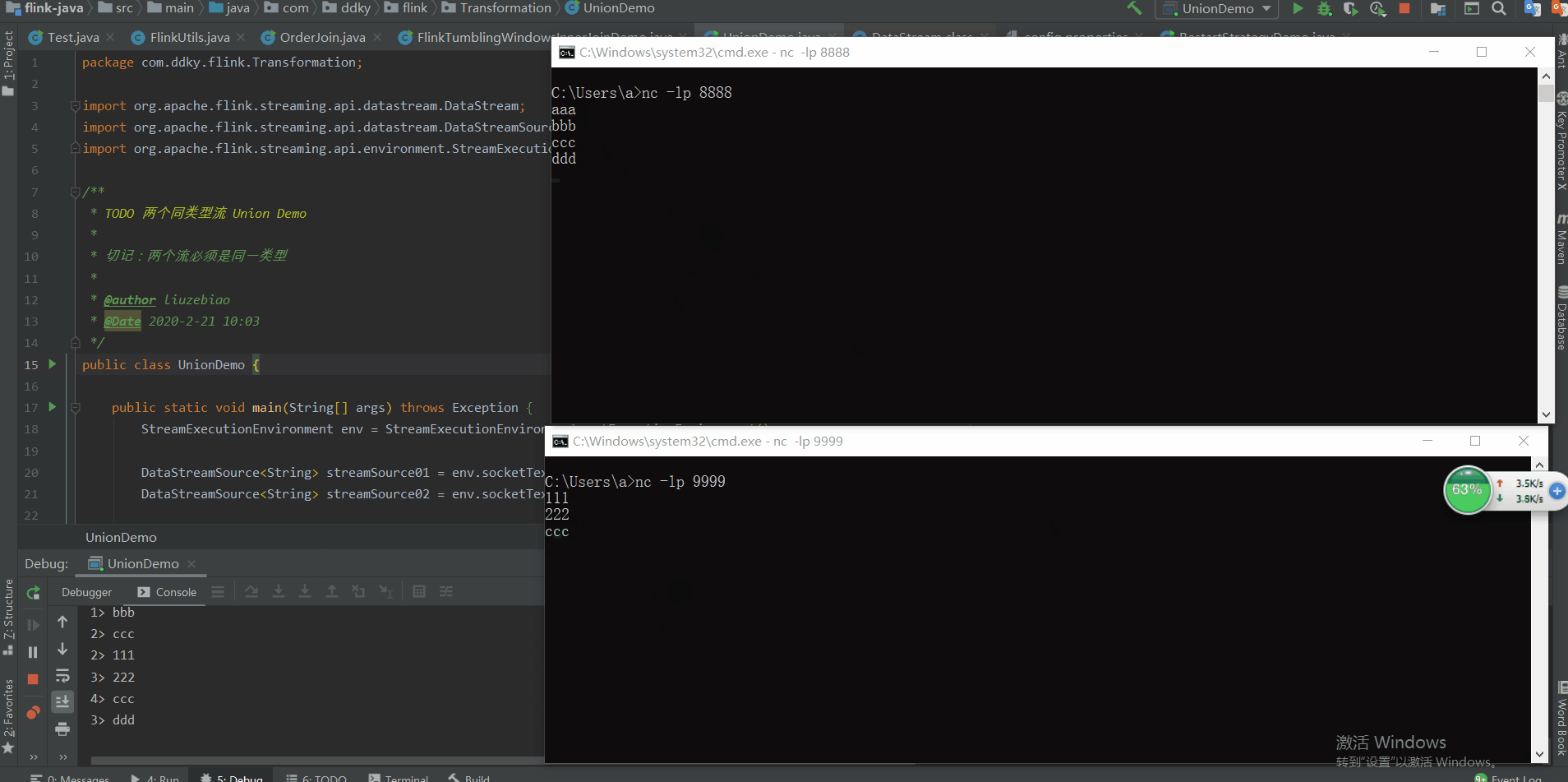
场景:分别从两个 Socket 端口号中读取数据,并将这两个数据流进行合并。
代码:
/**
1. TODO 两个同类型流 Union Demo
2. 3. 切记:两个流必须是同一类型
3. 5. @author liuzebiao
4. @Date 2020-2-21 10:03
*/
public class UnionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> streamSource01 = env.socketTextStream("localhost", 8888);
DataStreamSource<String> streamSource02 = env.socketTextStream("localhost", 9999);
DataStream<String> unionStreamSource = streamSource01.union(streamSource02);
unionStreamSource.print();
env.execute("UnionDemo");
}
}
测试结果:
3.9 connect()
connect 提供了和 union 类似的功能,用来连接两个数据流,它与union的区别在于:
connect 只能连接两个数据流,union 可以连接多个数据流;connect 所连接的两个数据流的数据类型可以不一致,union所连接的两个数据流的数据类型必须一致。- 两个DataStream 经过 connect 之后被转化为 ConnectedStreams,ConnectedStreams 会对两个流的数据应用不同的处理方法,且双流之间可以共享状态。
类型转换:
DataStream,DataStream → ConnectedStreams
使用介绍:
对于 ConnectedStreams ,我们需要重写CoMapFunction或CoFlatMapFunction。
这两个接口都提供了三个参数,这三个参数分别对应第一个输入流的数据类型、第二个输入流的数据类型和输出流的数据类型。
在重写方法时,都提供了两个方法(map1/map2 或 flatMap1/flatMap2)。在重写时,对于CoMapFunction,map1处理第一个流的数据,map2处理第二个流的数据;对于CoFlatMapFunction,flatMap1处理第一个流的数据,flatMap2处理第二个流的数据。Flink并不能保证两个函数调用顺序,两个函数的调用依赖于两个数据流数据的流入先后顺序,即第一个数据流有数据到达时,map1或flatMap1会被调用,第二个数据流有数据到达时,map2或flatMap2会被调用。
场景:
使用 connect() 方法,来完成对一个字符串流 和 一个整数流进行connect操作,并对流中出现的词进行计数操作
代码:
/**
* TODO 对两个不同类型的流合并,并计算流中出现单词/数字的次数
*
* @author liuzebiao
* @Date 2020-2-21 10:03
*/
public class ConnectDemo{
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> streamSource01 = env.fromElements("aa", "bb", "aa", "dd", "dd");
DataStreamSource<Integer> streamSource02 = env.fromElements(11,22,33,22,11);
ConnectedStreams<String, Integer> connectedStream = streamSource01.connect(streamSource02);
SingleOutputStreamOperator<Tuple2<String, Integer>> outputStreamOperator = connectedStream.map(new CoMapFunction<String, Integer, Tuple2<String, Integer>>() {
//处理第一个流数据
@Override
public Tuple2<String, Integer> map1(String str) throws Exception {
return Tuple2.of(str,1);
}
//处理第二个流数据
@Override
public Tuple2<String, Integer> map2(Integer num) throws Exception {
return Tuple2.of(String.valueOf(num),1);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = outputStreamOperator.keyBy(0).sum(1);
sum.print();
env.execute("ConnectDemo");
}
}
测试结果:

3.10 split()
类型转换:
DataStream → SplitStream
使用介绍:
按照指定标准,将指定的 DataStream流拆分成多个流,用SplitStream来表示。
场景:
将输入的元素,按照奇数/偶数分成两种流。
代码:
/**
* TODO 将输入的元素,按照奇数/偶数分成两种流。
*
* 通过.select() 方法,可以根据名称将 SplitStream 中的流取出
*
* @author liuzebiao
* @Date 2020-2-21 10:03
*/
public class SplitDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> streamSource = env.fromElements(1,2,3,4,5,6,7,8,9);
SplitStream<Integer> splitStream = streamSource.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
} else {
output.add("odd");
}
return output;
}
});
DataStream<Integer> bigData = splitStream.select("odd");
bigData.map(num -> Tuple2.of(num, 1)).returns(Types.TUPLE(Types.INT,Types.INT)).print();
env.execute("SplitDemo");
}
}
测试结果:

3.11 select()
类型转换:
SplitStream → DataStream
使用介绍:
从一个 SplitStream 流中,通过 .select()方法来获得想要的流(Select one or more streams from a split stream)
代码:
请参考 3.10 split()方法中的使用
博主写作不易,来个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
博主不能保证写的所有知识点都正确,但是能保证纯手敲,错误也请指出,望轻喷 Thanks♪(・ω・)ノ