Kaggle实战:Plant Seedlings Classification(植物幼苗分类)
2018年初从天池大数据竞赛转战Kaggle,发现在这里有更多有趣的项目,也有更多的大神来分享经验和代码,体会良多。
经过数字识别和泰坦尼克号预测的入门,我实战的第一个比赛是Plant Seedlings Classification(植物幼苗分类),我将从以下几个方面来记录这个比赛。
1. 比赛描述
2. 评价指标
3. 迁移学习
4. Keras训练
5. 比赛结果
------------------------------------------------------------------------------------------
1. 比赛描述
比赛的主要人数就是区分农作物幼苗中的杂草,以便获得更好的作物产量和更好的环境管理。比赛所用的数据集为奥胡斯大学信号处理组与丹麦南部大学合作发布的数据集,该数据集包含在几个生长阶段的大约960种属于12种物种的植物图像。下图为下载好的训练集部分样本。
数据集一共包括十二个物种,分别为
Black-grass
Charlock
Cleavers
Common Chickweed
Common wheat
Fat Hen
Loose Silky-bent
Maize
Scentless Mayweed
Shepherds Purse
Small-flowered Cranesbill
Sugar beet

2. 评价指标
以MeanFScore作为评价指标,具体解释见链接:https://en.wikipedia.org/wiki/F1_score。
给定每个类别k的正/负率,得出的得分以以下公式进行计算:

F1分数是精确度和召回率的调和平均值,公式如下:

3. 迁移学习
由于在当时并没有高端的GPU进行深度学习训练,于是准备使用迁移学习看看效果。
首先导入一些必要的库:
%matplotlib inline
import datetime as dt
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [16, 10]
plt.rcParams['font.size'] = 16
import numpy as np
import os
import pandas as pd
import seaborn as sns
from keras.applications import xception
from keras.preprocessing import image
from mpl_toolkits.axes_grid1 import ImageGrid
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
from tqdm import tqdm
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
start = dt.datetime.now()
接着使用Keras Pretrained Models数据集(从此处下载:https://www.kaggle.com/gaborfodor/seedlings-pretrained-keras-models/data),须将预训练模型复制到keras的缓存目录(〜/ .keras / models)中:
!ls ../input/keras-pretrained-models/
cache_dir = os.path.expanduser(os.path.join('~', '.keras')) if not os.path.exists(cache_dir): os.makedirs(cache_dir) models_dir = os.path.join(cache_dir, 'models') if not os.path.exists(models_dir): os.makedirs(models_dir)
!cp ../input/keras-pretrained-models/xception* ~/.keras/models/
!ls ~/.keras/models接下来对数据集进行查看:
!ls ../input/plant-seedlings-classification
CATEGORIES = ['Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed', 'Common wheat', 'Fat Hen', 'Loose Silky-bent', 'Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet'] NUM_CATEGORIES = len(CATEGORIES)
SAMPLE_PER_CATEGORY = 200 SEED = 1987 data_dir = '../input/plant-seedlings-classification/' train_dir = os.path.join(data_dir, 'train') test_dir = os.path.join(data_dir, 'test') sample_submission = pd.read_csv(os.path.join(data_dir, 'sample_submission.csv'))
sample_submission.head(2)
for category in CATEGORIES: print('{} {} images'.format(category, len(os.listdir(os.path.join(train_dir, category)))))
train = [] for category_id, category in enumerate(CATEGORIES): for file in os.listdir(os.path.join(train_dir, category)): train.append(['train/{}/{}'.format(category, file), category_id, category]) train = pd.DataFrame(train, columns=['file', 'category_id', 'category']) train.head(2) train.shape
对训练及测试样本进行查看:
train = pd.concat([train[train['category'] == c][:SAMPLE_PER_CATEGORY] for c in CATEGORIES])
train = train.sample(frac=1)
train.index = np.arange(len(train))
train.head(2)
train.shape
test = [] for file in os.listdir(test_dir): test.append(['test/{}'.format(file), file]) test = pd.DataFrame(test, columns=['filepath', 'file']) test.head(2) test.shape
定义读图函数:
def read_img(filepath, size): img = image.load_img(os.path.join(data_dir, filepath), target_size=size) img = image.img_to_array(img) return img
查看示例图:
fig = plt.figure(1, figsize=(NUM_CATEGORIES, NUM_CATEGORIES)) grid = ImageGrid(fig, 111, nrows_ncols=(NUM_CATEGORIES, NUM_CATEGORIES), axes_pad=0.05) i = 0 for category_id, category in enumerate(CATEGORIES): for filepath in train[train['category'] == category]['file'].values[:NUM_CATEGORIES]: ax = grid[i] img = read_img(filepath, (224, 224)) ax.imshow(img / 255.) ax.axis('off') if i % NUM_CATEGORIES == NUM_CATEGORIES - 1: ax.text(250, 112, filepath.split('/')[1], verticalalignment='center') i += 1 plt.show();

对验证集进行分割:
np.random.seed(seed=SEED) rnd = np.random.random(len(train)) train_idx = rnd < 0.8 valid_idx = rnd >= 0.8 ytr = train.loc[train_idx, 'category_id'].values yv = train.loc[valid_idx, 'category_id'].values len(ytr), len(yv
提取Xception bottleneck features(Keras中的一种预训练模型)
INPUT_SIZE = 299 POOLING = 'avg' x_train = np.zeros((len(train), INPUT_SIZE, INPUT_SIZE, 3), dtype='float32') for i, file in tqdm(enumerate(train['file'])): img = read_img(file, (INPUT_SIZE, INPUT_SIZE)) x = xception.preprocess_input(np.expand_dims(img.copy(), axis=0)) x_train[i] = x print('Train Images shape: {} size: {:,}'.format(x_train.shape, x_train.size))
Xtr = x_train[train_idx] Xv = x_train[valid_idx] print((Xtr.shape, Xv.shape, ytr.shape, yv.shape)) xception_bottleneck = xception.Xception(weights='imagenet', include_top=False, pooling=POOLING) train_x_bf = xception_bottleneck.predict(Xtr, batch_size=32, verbose=1) valid_x_bf = xception_bottleneck.predict(Xv, batch_size=32, verbose=1) print('Xception train bottleneck features shape: {} size: {:,}'.format(train_x_bf.shape, train_x_bf.size)) print('Xception valid bottleneck features shape: {} size: {:,}'.format(valid_x_bf.shape, valid_x_bf.size))
LogReg模型
logreg = LogisticRegression(multi_class='multinomial', solver='lbfgs', random_state=SEED) logreg.fit(train_x_bf, ytr) valid_probs = logreg.predict_proba(valid_x_bf) valid_preds = logreg.predict(valid_x_bf)
print('Validation Xception Accuracy {}'.format(accuracy_score(yv, valid_preds)))
混淆矩阵
cnf_matrix = confusion_matrix(yv, valid_preds)
abbreviation = ['BG', 'Ch', 'Cl', 'CC', 'CW', 'FH', 'LSB', 'M', 'SM', 'SP', 'SFC', 'SB'] pd.DataFrame({'class': CATEGORIES, 'abbreviation': abbreviation})
fig, ax = plt.subplots(1) ax = sns.heatmap(cnf_matrix, ax=ax, cmap=plt.cm.Greens, annot=True) ax.set_xticklabels(abbreviation) ax.set_yticklabels(abbreviation) plt.title('Confusion Matrix') plt.ylabel('True class') plt.xlabel('Predicted class') fig.savefig('Confusion matrix.png', dpi=300) plt.show();
最后生成提交结果:
x_test = np.zeros((len(test), INPUT_SIZE, INPUT_SIZE, 3), dtype='float32') for i, filepath in tqdm(enumerate(test['filepath'])): img = read_img(filepath, (INPUT_SIZE, INPUT_SIZE)) x = xception.preprocess_input(np.expand_dims(img.copy(), axis=0)) x_test[i] = x print('test Images shape: {} size: {:,}'.format(x_test.shape, x_test.size))
test_x_bf = xception_bottleneck.predict(x_test, batch_size=32, verbose=1) print('Xception test bottleneck features shape: {} size: {:,}'.format(test_x_bf.shape, test_x_bf.size)) test_preds = logreg.predict(test_x_bf)
end = dt.datetime.now() print('Total time {} s.'.format((end - start).seconds)) print('We almost used the one hour time limit.')
最后的结果不太理想,分数为0.94+,排行中下。在有了一块1060的显卡之后进行训练。
4. Keras训练
代码比较简单,就是耗时略久。代码如下:
import pandas as pd
import numpy as np
import os
import imageio
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Activation
from keras.layers import Dropout
from keras.layers import Maximum
from keras.layers import ZeroPadding2D
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPooling2D
from keras.layers.merge import concatenate
from keras import regularizers
from keras.layers import BatchNormalization
from keras.optimizers import Adam, SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from keras.layers.advanced_activations import LeakyReLU
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from skimage.transform import resize as imresize
from tqdm import tqdm
from subprocess import check_output
print(check_output(["ls", "../input"]).decode("utf8"))
BATCH_SIZE = 16
EPOCHS = 30
RANDOM_STATE = 11
CLASS = {
'Black-grass': 0,
'Charlock': 1,
'Cleavers': 2,
'Common Chickweed': 3,
'Common wheat': 4,
'Fat Hen': 5,
'Loose Silky-bent': 6,
'Maize': 7,
'Scentless Mayweed': 8,
'Shepherds Purse': 9,
'Small-flowered Cranesbill': 10,
'Sugar beet': 11
}
INV_CLASS = {
0: 'Black-grass',
1: 'Charlock',
2: 'Cleavers',
3: 'Common Chickweed',
4: 'Common wheat',
5: 'Fat Hen',
6: 'Loose Silky-bent',
7: 'Maize',
8: 'Scentless Mayweed',
9: 'Shepherds Purse',
10: 'Small-flowered Cranesbill',
11: 'Sugar beet'
}
# Dense layers set
def dense_set(inp_layer, n, activation, drop_rate=0.):
dp = Dropout(drop_rate)(inp_layer)
dns = Dense(n)(dp)
bn = BatchNormalization(axis=-1)(dns)
act = Activation(activation=activation)(bn)
return act
# Conv. layers set
def conv_layer(feature_batch, feature_map, kernel_size=(3, 3),strides=(1,1), zp_flag=False):
if zp_flag:
zp = ZeroPadding2D((1,1))(feature_batch)
else:
zp = feature_batch
conv = Conv2D(filters=feature_map, kernel_size=kernel_size, strides=strides)(zp)
bn = BatchNormalization(axis=3)(conv)
act = LeakyReLU(1/10)(bn)
return act
# simple model
def get_model():
inp_img = Input(shape=(51, 51, 3))
# 51
conv1 = conv_layer(inp_img, 64, zp_flag=False)
conv2 = conv_layer(conv1, 64, zp_flag=False)
mp1 = MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(conv2)
# 23
conv3 = conv_layer(mp1, 128, zp_flag=False)
conv4 = conv_layer(conv3, 128, zp_flag=False)
mp2 = MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(conv4)
# 9
conv7 = conv_layer(mp2, 256, zp_flag=False)
conv8 = conv_layer(conv7, 256, zp_flag=False)
conv9 = conv_layer(conv8, 256, zp_flag=False)
mp3 = MaxPooling2D(pool_size=(3, 3), strides=(2, 2))(conv9)
# 1
# dense layers
flt = Flatten()(mp3)
ds1 = dense_set(flt, 128, activation='tanh')
out = dense_set(ds1, 12, activation='softmax')
model = Model(inputs=inp_img, outputs=out)
# The first 50 epochs are used by Adam opt.
# Then 30 epochs are used by SGD opt.
#mypotim = Adam(lr=2 * 1e-3, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
mypotim = SGD(lr=1 * 1e-1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=mypotim,
metrics=['accuracy'])
model.summary()
return model
def get_callbacks(filepath, patience=5):
lr_reduce = ReduceLROnPlateau(monitor='val_acc', factor=0.1, epsilon=1e-5, patience=patience, verbose=1)
msave = ModelCheckpoint(filepath, save_best_only=True)
return [lr_reduce, msave]
# I trained model about 12h on GTX 950.
def train_model(img, target):
callbacks = get_callbacks(filepath='model_weight_SGD.hdf5', patience=6)
gmodel = get_model()
gmodel.load_weights(filepath='model_weight_Adam.hdf5')
x_train, x_valid, y_train, y_valid = train_test_split(
img,
target,
shuffle=True,
train_size=0.8,
random_state=RANDOM_STATE
)
gen = ImageDataGenerator(
rotation_range=360.,
width_shift_range=0.3,
height_shift_range=0.3,
zoom_range=0.3,
horizontal_flip=True,
vertical_flip=True
)
gmodel.fit_generator(gen.flow(x_train, y_train,batch_size=BATCH_SIZE),
steps_per_epoch=10*len(x_train)/BATCH_SIZE,
epochs=EPOCHS,
verbose=1,
shuffle=True,
validation_data=(x_valid, y_valid),
callbacks=callbacks)
def test_model(img, label):
gmodel = get_model()
gmodel.load_weights(filepath='../input/plant-weight/model_weight_SGD.hdf5')
prob = gmodel.predict(img, verbose=1)
pred = prob.argmax(axis=-1)
sub = pd.DataFrame({"file": label,
"species": [INV_CLASS[p] for p in pred]})
sub.to_csv("sub.csv", index=False, header=True)
# Resize all image to 51x51
def img_reshape(img):
img = imresize(img, (51, 51, 3))
return img
# get image tag
def img_label(path):
return str(str(path.split('/')[-1]))
# get plant class on image
def img_class(path):
return str(path.split('/')[-2])
# fill train and test dict
def fill_dict(paths, some_dict):
text = ''
if 'train' in paths[0]:
text = 'Start fill train_dict'
elif 'test' in paths[0]:
text = 'Start fill test_dict'
for p in tqdm(paths, ascii=True, ncols=85, desc=text):
img = imageio.imread(p)
img = img_reshape(img)
some_dict['image'].append(img)
some_dict['label'].append(img_label(p))
if 'train' in paths[0]:
some_dict['class'].append(img_class(p))
return some_dict
# read image from dir. and fill train and test dict
def reader():
file_ext = []
train_path = []
test_path = []
for root, dirs, files in os.walk('../input'):
if dirs != []:
print('Root:\n'+str(root))
print('Dirs:\n'+str(dirs))
else:
for f in files:
ext = os.path.splitext(str(f))[1][1:]
if ext not in file_ext:
file_ext.append(ext)
if 'train' in root:
path = os.path.join(root, f)
train_path.append(path)
elif 'test' in root:
path = os.path.join(root, f)
test_path.append(path)
train_dict = {
'image': [],
'label': [],
'class': []
}
test_dict = {
'image': [],
'label': []
}
#train_dict = fill_dict(train_path, train_dict)
test_dict = fill_dict(test_path, test_dict)
return train_dict, test_dict
# I commented out some of the code for learning the model.
def main():
train_dict, test_dict = reader()
#X_train = np.array(train_dict['image'])
#y_train = to_categorical(np.array([CLASS[l] for l in train_dict['class']]))
X_test = np.array(test_dict['image'])
label = test_dict['label']
# I do not recommend trying to train the model on a kaggle.
#train_model(X_train, y_train)
test_model(X_test, label)
if __name__=='__main__':
main()里面有两个权重文件需要下载,链接:点击打开链接

这个训练的效果很好,可达到0.97+的分数。
5. 比赛结果
关于结果,对排行榜有一些疑问,因为前几名都是百分百的正确率,不知道怎么做到的,在Kernels里面也没有相应的解释。
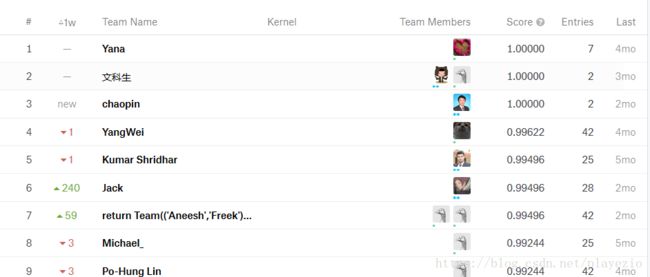
我最后的得分还是0.97103,大概排到了300名的位置,还有很大的进步空间!
