漫谈云计算网络(一):云计算网络技术介绍
声明:本文CSDN作者原创投稿文章,未经许可禁止任何形式的转载。
作者:张钦,云途腾高级云解决方案架构师,负责企业级云计算网络解决方案的架构设计及客户培训。曾就职于金山云和中国电信,任职售前解决方案架构师及云数据中心网络架构师,思科CCIE认证工程师。
责编: 钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件[email protected],另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。
编者按:本文是《漫谈云计算网络》系列的第一篇,本系列文章面向的对象为网络工程师和对网络技术感兴趣的童鞋。作者从云计算网络技术介绍,云计算网络的架构模式以及在企业实践SDN/NFV解决方案的经验总结三个维度进行分享。
一、数据中心网络技术的变革
数据中心的网络架构和技术在云计算诞生后,与数据中心的计算及存储一起都在发生着变化。起初数据中心网络分为内部与外部,数据中心外部网络指的通常是三层网络,也就是我们最开始所认知所学习的诸如:BGP、IS-IS、OSPF等三层路由协议的使用与三层网络架构的设计,怎么才能规划路由,怎么才能使得流量按照路由的规划选址最优的路径提供出去,如果说数据中心外部网络关注更多的是提升用户的体验,那么数据中心内部网络就是运维兄弟关注的重点之一,提升网络系统的效率。数据中心内部网络是云计算引入后发展非常迅速的一个领域,也是更新迭代最快的领域。最开始我们认知的数据中心网络局限在同一个物理数据中心内部,随着云计算的发展,数据中心网络逐渐进化为同地域多物理数据中心的网络被抽象成一个虚拟化的内部网络,到现在不同地域乃至全球范围的物理数据中心网络都可以互相二层打通的云化网络。
新的标准、新的架构、新的产品层出不穷,可延续、可扩展、高灵活、稳定的高度整合是越来越多的中心所追求的一个新的网络体系架构。大二层网络是在云计算引入进来以后引入的一个新的概念,曾经被定义为下一代数据中心网络,原有的网络架构由于没有考虑二层网络横向扩展与交换原理的诞生时并没有考虑到二层网络会有今天如此之大的需求,二层网络的困境逐渐的体现出来,不论是公有云还是私有云同样都面对了同一个问题,就是传统二层网络问题,其中包括了二层网络的广播风暴、低延迟、STP生成树协议的限制、二层网络边界逐渐扩大、vlan的数量问题、vlan tag的转换、多租户之间的私有网络的灵活性问题迫使整个数据中心网络在今天的云时代下已经发生了翻天覆地的变化。下面是笔者基于自己的理解,对云计算网络中的技术应用进行的整理和总结
1.1 Overlay
随着网络变化越来越大,需求不断改变,传统的网络设计思路的局限性逐渐凸显,而且数据中心之间的通信本质还是依赖运营商提供的资源,如果有钱可以选择裸光纤,但是IT本身就是为了业务更好更快地发展所提供的一种高效工具,那么更多的数据中心网络其实还是依赖运营商的网络,在这个网络之上进行叠加加以利用,或者租用运营商提供的网络资源,随着越来越多需要叠加的逻辑网络的需求不断涌出,下面我们先来回顾一下网络世界里不得不提,也是每一个网络从业者所需要了解的一个网络技术知识-Overlay。
Overlay的本质理念就是叠加,在原有的传统网络上虚拟出或者叠加出一个逻辑网络来,传统网络不需要做任何改变,就可以将新的网络通信协议在其上展开,其主要技术路线,就是对数据中心网络的建设模式进行了完全的颠覆,原有的接入层、汇聚层、核心层的三层设计架构逐渐演变为二层汇聚与三层网关的叶脊架构。
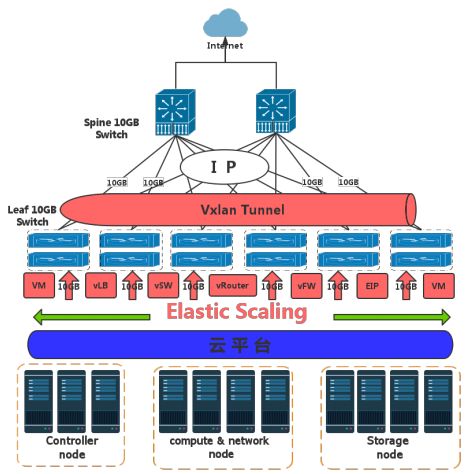
Overlay无状态网络技术也是未来数据中心网络发展的一个重要组成部分。其主要意义就是叠加,通过其定义的逻辑网络,实现业务所需要的逻辑网络,从而解决数据中心云化的网络问题,极大地节省了传统的IT投资成本,Overlay也是一种将(业务的) 二层网络构架在(传统网络的)三层/四层报文中进行传递的网络技术。这样的技术实际上就是一种隧道封装技术。最关键的业务模型就是要实现一种无状态的网络模型,即使跨越运营商资源,也可以实现多个数据中心互访,甚至虚拟机迁移都可以无感知地在这张逻辑网络上运行,同时对上层应用提供无感知的网络服务。
1.2 MPLS VPN
其实在网络技术里已经有了不少的封装技术,MPLS VPN就是其典型代表之一,在90年代初期,当时路由器由于转发效率低下,无法保证完整的QOS设计等原因,其发展远远落后于网络,当时的路由查找算法必须依赖软件查找,路由器性能也会因此受到影响,网络处于不重视结果的尽力而为的困境,ATM网络随后诞生,同时IP网络中的MPLS也诞生出来。
MPLS(multi-protocollabelswitch)是Internet核心多层交换计算的最新发展。MPLS将转发部分的标记交换和控制部分的IP路由组合在一起,加快了转发速度。而且,MPLS可以运行在任何链接层技术之上,从而简化了向基于SONET/WDM和IP/WDM结构的下一代光Internet的转化。MPLS与链路层区分开来,定义为2.5层协议,可以在其网络结构上承载其他报文,与1997年正式命名为MPLS。
通常,MPLS包头有32Bit,其中有:
- 20Bit用作标签(Label)标签只有本地有意义不会缺少
- 3个Bit的EXP, 协议中没有明确,通常用作COS
- 1个Bit的S,用于标识是否是栈底,表明MPLS的标签可以嵌套
- 8个Bit的TTL

- 标签(Lable):是一个比较短的,定长的,通常只具有局部意义的标识,这些标签通常位于数据链路层的数据链路层封装头和三层数据包之间,标签通过绑定过程同FEC相映射。
- FEC(Forwarding Equivalence Class,转发等价类):是在转发过程中以等价的方式处理的一组数据分组, MPLS本来规定:可以通过地址、隧道、COS等来标识创建FEC,现在看到的MPLS中只是一条路由对应一个FEC:通常在一台设备上,对一个FEC分配相同的标签。(一组不同数据从相同的接口进来相同的接口出去)
- LSP(标签交换通道):一个FEC的数据流,在不同的节点被赋予确定的标签,数据转发按照这些标签进行。数据流所走的路径就是LSP。
- LSR(Label Switching Router): LSR是MPLS的网络的核心交换机,它提供标签交换和标签分发功能。
- LER(Label Switching Edge Router):在MPLS的网络边缘,进入到MPLS网络的流量由LER分为不同的FEC,并为这些FEC请求相应的标签。它提供流量分类和标签的映射、标签的移除功能。(变IP转发为标签转发)
MPLS VPN专业术语: - PE路由器:又称作提供商边缘路由器。该路由器负责用户端网络到提供商网络的接入。
- P路由器:又称提供商路由器。P路由器是提供商网络中不连接任何CE设备的路由器。
- CE路由器:又称用户边缘设备。CE路由器通过连接至一个或多个提供商边缘(PE)路由器的数据链路为用户提供对服务提供商的接入。
- **VPN-IPV4地址:**VPN用户通常使用私有地址来规划自己的网络。当不同的VPN用户使用相同的私有地址规划时就会出现路由查找问题。
- 路由区分符RD:路由区分符RD即VPN-Ipv4地址的前8字节,用来区分不同VPN中的相同私网地址。
- 路由目标RT: RT为MP-BGP中的扩展共同体属性之一。路由目标属性定义了PE路由器发布路由的一组站点(VRF)的集合。PE路由器使用这一属性来对输入远端路由到其VRF进行约束。
- VPN路由转发表(VRF):每个PE路由器为其直连的站点维持一个VRF。每个用户链接被映射至一个特定的VRF。每个VRF与PE路由器的一个端口相关联。
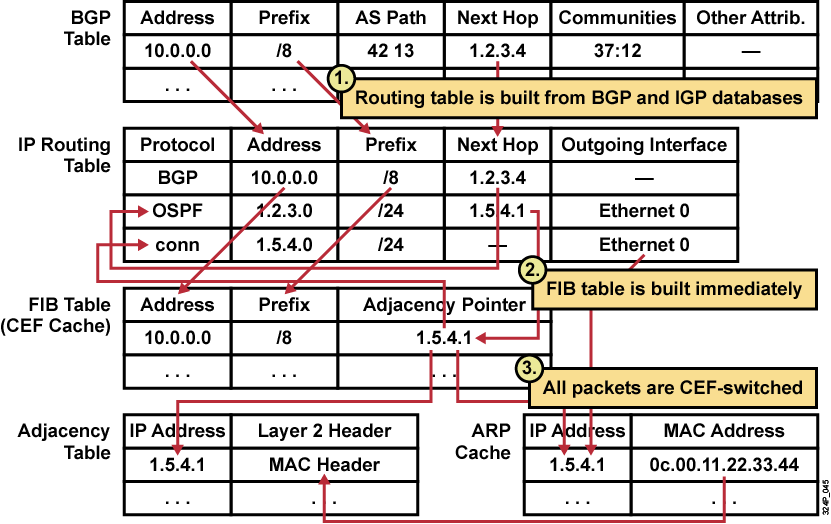
LDP方式传递:

LSR控制平面:

Edge LSR控制平面:

1.3 MPLS VPN-VPLS
虚拟专用局域网业务VPLS(Virtual Private LAN Service)是公用网络中提供的一种点到多点的L2VPN(Layer 2 virtual private network)业务,使地域上隔离的用户站点能通过MAN/WAN(Metropolitan Area Network/Wide Area Network)相连,并且使各个站点间的连接效果像在一个LAN(Local Area Network)中一样。它是一种基于MPLS(MultiProtocol Label Switching)网络的二层VPN技术,也被称为透明局域网业务TLS(Transparent LAN Service)。典型的VPLS组网如下:处于不同物理位置的用户通过接入不同的PE设备,实现用户之间的互相通信。从用户的角度来看,整个VPLS网络就是一个二层交换网,用户之间就像直接通过LAN互连在一起一样。
目前,随着企业的分布范围日益扩大以及公司员工的移动性不断增加,企业中VoIP、即时消息、网络会议的应用越来越广泛,因此这些应用对端到端的数据通信技术有了更高的要求。端到端数据通信功能的实现依赖于一个能够支持多点业务的网络。
传统的ATM(Asynchronous Transfer Mode)、FR(Frame Relay)技术只能实现二层点到点互连,而且具有网络建设成本高、速率较慢、部署复杂等缺点。随着IP技术的发展,一种在IP(Internet Protocol)网络上提供VPN(Virtual Private Network)服务、可方便设定速率、配置简单的技术随之产生,这种技术即MPLS VPN技术。基于MPLS的VPN技术有两种,分别是MPLS L2VPN和MPLS L3VPN:
- 传统VLL(Virtual Leased Line)方式的MPLS L2VPN是在公网中提供一种点到点的L2VPN业务,不能直接在服务提供者处进行多点间的交换。
MPLS L3VPN网络虽可提供多点业务,但PE设备会感知私网路由,造成设备的路由- 信息过于庞大,对PE设备的路由控制性能要求较高。
针对以上问题,VPLS在传统MPLS L2VPN方案的基础上发展而成,是一种基于以太网和MPLS标签交换的技术:
- 由于以太网本身就具有支持多点通信特点,使得VPLS技术可以实现多点通信的要求。
- 同时VPLS是一种二层标签交换技术,从用户侧来看,整个MPLS IP骨干网是一个二层交换设备,PE设备不需要感知私网路由。
因此,VPLS技术为企业提供了一种更加完备的多点业务解决方案。它结合了以太网技术和MPLS技术的优势,是对传统LAN全部功能的仿真,其主要目的是通过运营商提供的IP/MPLS网络连接地域上隔离的多个由以太网构成的LAN,使它们像一个LAN那样工作。
VPLS pw自动部署

BGP AD VPLS PW的自动部署过程详细描述如下:
两台PE上属于相同VPLS域的VSI根据到远端(BGP AD中的Next Hop)的LDP会话状态相互发起LDP Mapping(FEC 129)信令,其中携带AGI、SAII、TAII和标签等信息。
BGP AD VPLS在成员发现后,采用主动触发LDP协议创建LDP会话的方式,使LDP能够按照业务的需求来建立会话。当VPLS业务撤销,不再使用该LDP会话时,再主动触发LDP协议拆除LDP会话。这样既能减少LDP会话拓扑的维护工作量,又能提高系统资源的利用率,减少网络资源的开销,提升网络性能。
PE接收到远端的LDP Mapping(FEC 129)信令后,解析获取VPLS-ID、PW Type、MTU、TAII等信息,将这些信息与本地VSI比较,如果协商通过,并且满足建立PW的条件时,创建到对端的PW。
一个VPLS转发实例:
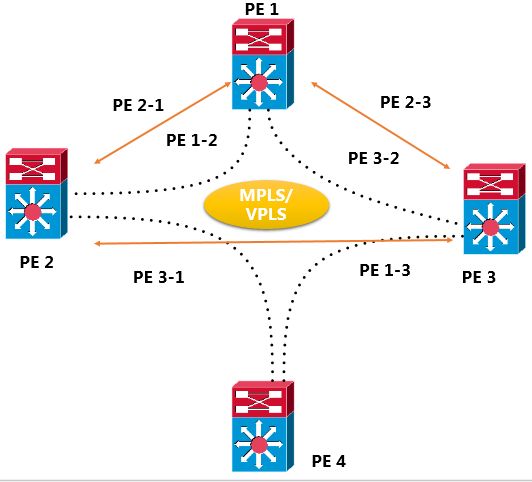
VPLS限制:VPLS在过去mpls大规模发展过程当中,虽然解决了跨站点间的2层通讯问题,但是同样对于运维人员来说就是一场噩梦,首先我们需要组建自己的一整张MPLS VPN的网络,这里面就涉及到了资源的购买,或者直接租赁第三方的MPLS VPN网络,但是租用网络后,我们运行VPLS,就需要运维人员每天都去维护不同的pw,并且要在维护一张路由表的同时还需要维护一张Fwording Table(标签转发信息库),除此之外,还需要运维人员维护不同的二层网络。VPLS虽说一时解决了二层跨站点通信的问题,但是同样它的缺陷也是显而易见的,首先VPLS基于vlan的情况下,广播,arp,生成树协议依然存在;每个vlan的转发依然是单边走向路径,冗余链路并不能及时利用,造成链路的浪费;过多的网络资源实际是依赖运营商的网络资源,运营商的网络资源我想每一个数据中心都深有体会;同时,运维人员还要面对MPLS VPN 当中配置的复杂性,对于整个运维团队在维护数据中心网络的同时又增加了一个不小的挑战。
1.4 LISP
LISP(Locator/Identifier Separarion Protocal——位置/身份分离协议)是为了改变由于云计算到来造成数据中心的资源地理位置的不确定性的通信问题的一种尝试手段,从IP层协议进行介入,解决数据网络在云计算大规模到来时的网络瓶颈的一种尝试性网络技术。是一种添加了控制平面的IPsec VPN服务,并且可以轻松应对传统点到点与点到多点的业务需求模型。
LISP在传统IP网络层中添加了两个重要的新的网络元素:
- ITR(Ingress Tunnel Router—-入向隧道路由器)
- ETR(Egress Tunnel Router—-出向隧道路由器)
其转发的基本原理为:部署在LISP网络边界的ITR路由器接受非LISP站点发来的数据包,并添加上新的ROLC包头作为源包头,依据LISP中ROLC的转发规则进行路由查表转发,到达位于LISP数据路径的最后一站的ETR路由器,还原原始普通IP数据包,并转发给传统非LISP站点进行解封装原始数据包。
相较于传统的IP数据包,LISP最大的变化之一就是将IP数据包分为了外层与内层两层数据包头,外层为LISP通信的RLOCs,通常为一个ETR位置,内存携带的EID信息是一个非LISP常规站点信息。下图为LISP包头信息

1.5 Fabric-Path
LISP还属于典型的数据中心外部网络设计技术方案,而数据中心内部网络平台才是将云计算各个系统之间串联的关键网络技术平台。
随着虚拟化技术的出现,数据中心网络逐渐发生改变,现在的数据中心需要“一个大二层”网络满足多租户内网与虚机迁移,同时只有灵活的二层网络才能实现即插即用的特殊协议的应用需求。但是传统网络中为了避免二层环路所出现的二层特性STP(Spaning Tree)协议所构建的网络与现在数据中心所需要的网络模型确是背道而驰,即使是快速生成树协议的30秒组网速度也不能满足现在数据中心网络所需,同时STP协议带来最大的问题就是带宽的浪费与根桥枪战导致网络中断的问题。
特点:
新增一个二层帧头(原地址、目的地址、TTL):
源地址和目的地址:新定义Switch ID的全新命名空间,最为唯一的标识,进行路由寻址。增加一套简化的IS-IS路由协议:
引入IS-IS路由协议作为控制层面的依据,链路状态路由协议,相比MAC地址寻址这样的距离矢量路由协议来说,链路状态路由协议可以在整网当中更新一整张路由拓扑结构,新增加的节点与随时更新整个链路状态数据库,从而达到从最短的距离上去转发数据包。
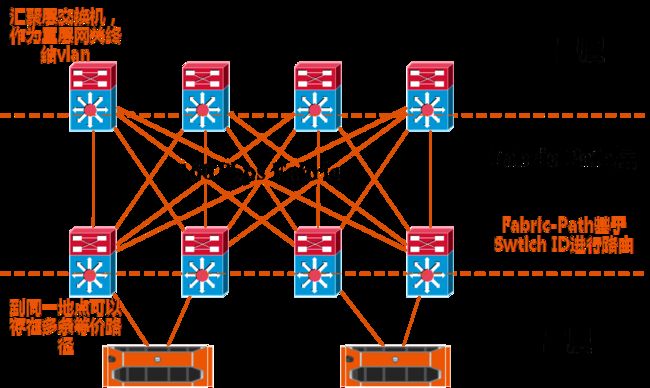
Cisco FabricPath技术是一种二层交换技术与三层路由技术的融合体,它既拥有二层交换技术的易于配置,即插即用和快速部署的优势。还拥有路由技术所独有的多链路负载均衡,快速收敛和高扩展性的特点。是一种真正意义上二三层技术融合的产物。整个Fabric-Path交换网络的组成可以看做是一个大的交换机也就是一个整体的二层交换域,但是其控制平面采用了三层路由协议IS-IS,每台Fabric-Path交换机通过Switch ID来进行组网,Switch ID就像以太网中的IP地址一样,是所有FabricPath交换机的唯一标示,实现了二层网络在链路状态路由协议上的转发,免去了原有二层网络设计的树状方式的不便捷性,同时实现了二层FULL-MESH架构。
数据包结构:

组网架构图:
1.6 Trill
传统二层网络作为一种源于局域网互联技术,一般采用xSTP协议防止广播风暴,具有简单易于维护等特点,在数据中心得到了广泛应用。在目前阶段,规模化、虚拟化、云计算已成为数据中心的发展方向。由于云计算数据中心对转发带宽的需求非常大,而且传统的xSTP为了避免环路会阻塞某个端口导致部分带宽的浪费,因此三层IP转发作为一种过渡技术也被应用在数据中心。对于一些较大的数据中心提供商,一个数据中心的服务器容量已经不能满足他们的需求,出于扩容和灾备两方面的目的,大型厂商通常会考虑建立多个数据中心。在扩容时,需要利用虚拟机迁移技术进行数据中心的建设部署。
随着数据中心的规模不断扩张,业务需求的不断增大,服务器以及接入交换机都大规模增加,不管是传统的二层网络还是作为过渡的三层IP转发都不能很好地满足数据中心的需求。与TRILL协议相比,xSTP协议从适用的组网、网络规模及带宽利用率等方面都不具备优势。另外,在传统的IPv4和IPv6网络中,由于设备的接口需要配置IP地址,造成IP网络的配置复杂。而当一个接口由一个子网切换到另一个子网时,必须要改变它的IP地址,这也给虚拟机的迁移增大了管理成本。而且,为了避免地址的浪费,IP地址的管理也需要占用大量的人力资源。因此,三层IP技术的这些问题导致它在二层网络中表现并不优越。TRILL作为大二层的控制协议,通过扩展IS-IS路由协议,把二层配置的灵活性与三层的大规模性有效结合在一起,部署方便。
2.6.1 Trill原理描述:
TRILL网络中的设备名称:
- RB(Router Bridge):指运行TRILL协议的二层交换机。
DRB(Designated Router Bridge):指在TRILL网络中作为中间设备被指定承担某些特殊任务的RB。在TRILL广播网中,两台RB如果处于同一个VLAN(Virtual Local Area Network),在建立邻居关系时需要根据接口的DRB优先级或者MAC地址的大小来选举DRB,DRB负责与网络中每台设备进行通信,最终使整个VLAN的LSDB(Link State DataBase)达到一致状态,减少了多台设备两两通信带来的巨大开销。
TRILL中的VLAN-
- Carrier VLAN:
VLAN是将一个物理的LAN在逻辑上划分成多个广播域的技术。同一VLAN内的设备之间可以直接通信,而不同VLAN之间的设备不能直接通信,这样,广播报文被限制在一个VLAN内,保证了局域网的安全性。
Carrier VLAN用于承载TRILL数据和收发协议报文,不承载普通ETH数据报文,一台RB最多可配置三个不同的Carrier VLAN。 - CE VLAN:
CE VLAN也叫做接入VLAN,用以接入TRILL网络,只负责承载普通ETH数据报文。 - Designated VLAN:
指定VLAN,在TRILL网络中需要指定某个Carrier VLAN为转发数据流量及TRILL控制报文的VLAN,该指定的TRILL VLAN被称为Designated VLAN,以下简称为DVLAN。 - Nickname:
Nickname相当于IP地址,用来唯一标识一台交换机。一台RB仅支持配置一个nickname,且须保证nickname全网唯一。
- Carrier VLAN:
TRILL协议地址结构
与IS-IS协议类似,TRILL协议采用NSAP(Network Service Access Point)地址结构,如00.1234.5678.9abc.00,可以看作由以下三部分组成:- Area ID:区域地址用来标识区域。与IS-IS不同的是,TRILL的区域地址规定为“00”。
- System ID:系统ID用来唯一标识一台主机或交换机,在设备的实现中,它的长度固定为48 Bit。
实际应用中,System ID可以自动生成也可以通过配置得到。自动生成的System ID与RB的桥MAC地址相同,如果手动配置的话,需要保证全网唯一。 - SEL(Selector):作用类似IP中的“协议标识符”,不同的传输协议对应不同的SEL。TRILL协议的SEL为“00”。
NET
网络实体名称NET(Network Entity Title)指的是交换机本身的网络层信息,可以看作是一类特殊的NSAP。例如有NET为:00.1234.5678.9abc.00,则其中区域地址为00,System ID为1234.5678.9abc,SEL为00。

- TRILL报文格式:

Trill虽然是大二层网络的一个新型的扩展协议,对于数据中心内部的组网来说,小规模部署还是没有问题的,但是对于数据中心未来的发展,个人认为其并不是最理想的网络架构模型,首先trill解决了二层网络环路与生成树的限制性问题,但是其在一个组播组下所组建的vlan实例数量是有限的,并且trill并没有真正解决二层网络当中vlan不足的问题,同时无法在传统网络上进行叠加,也就是设备选型必须统一,而且不能跨越任何运营商网络,也就是不能达到多站点间网络部署的规划,那么对于云计算来说,trill这种网络协议不能随着时代进步而替代现有网络架构,其也并没有解决vlan tag转换的问题。那么多个数据中心直接vlan domain仍然同属一个vlan domain空间。
1.7 OTV
VPLS的到来其实要早于云计算的到来,最初的VPLS到来只是为了增添IP协议与ATM之间的一场争夺战,VPLS本身可以建立二层网络在三层网络上的传递,但是由于其依托于MPLS VPN对于企业来说不管从技术部署与运维层面,还是从网络资源方面都是一个不小的挑战,广播、load-balance、stp、ARP这些限制性问题依然存在,后来的LISP、Fabric-Path、Ttill等新起的大二层网络协议也都是属于一个数据中心内部的二层网络协议,但是当云计算到来的今天,越来越多的数据中心不再局限在单个机房内部或者虚拟资源池的规模也不会只是属于单一的数据中心,越来越多的需求由单数据中心逐渐的引申到多数据中心组网,二层网络也会随之延伸至全地域,对于数据中心二层网络的需求对于之间的协议也就带来了新的挑战。

OTV是cisco2010年在其数据中心Nexus 7000上发布的一项软件特性,OTV实际是一种VPN隧道技术,简化了数据平面机制,不用再像VPLS一样维护众多尾纤(PW),是一种基于IS-IS作为控制层面的对MAC地址进行寻址的VPN协议。可以作为TRILL或者Fabric-Path的城域网版本的协议。路由表中将MAC地址需要通过哪个OTV节点进行表项化,MAC寻址更像路由协议,每个OTV节点的路由信息在第一个数据包发送出去后就已经进行了信息同步,同Fabric-Path和TRILL,是一种类似链路状态路由协议,本质是在广域网链路架构了一个Overlay的叠加网络。
OTV控制平面依据Hello报文进行链路信息同步,同时支持两种控制平面传输模式,一种为组播模式,一种为单播模式,区别在于当运营商网络支持组播,每个OTV节点发送一个Hello报文就可以将整个OTV网络信息进行同步,每个OTV节点都会帧听到相同的组播地址所发布的Hello消息。单播模式情况下,那么需要OTV节点一对一的进行Hello报文的传递,直至所有节点都发送完毕,才建立一张整体OTV逻辑网络。同时OTV可以基于vlan进行广域网流量负载均衡,比如基于奇数vlan与偶数vlan分别进行load-balance。

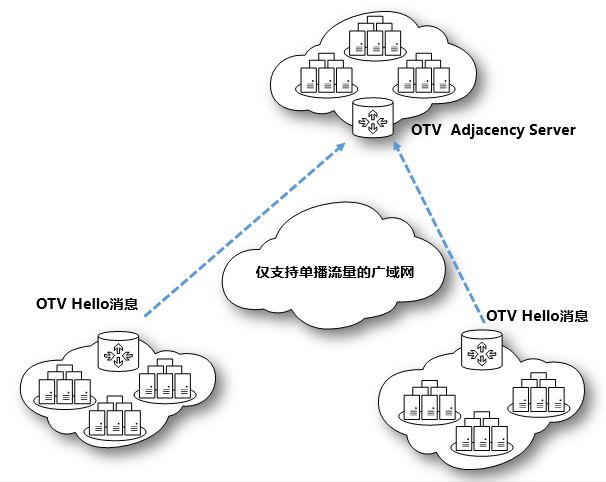
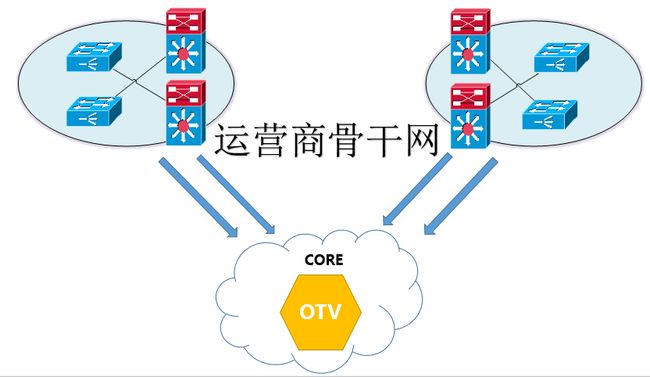
OTV在当时是一款非常不错的跨站点的网络协议,在跨越运营商网络的同时,节省昂贵的专线费用。但是由于其协议的属性属于私有协议,对于一般的中小企业可能难以支持其昂贵的价格,但是不可否认,OTV在对于高密度出口交换机当中的一个完整解决架构,确实是一个非常不错的架构方式。在运营高密度交换机时,可以将云计算底层虚拟化流量全部汇聚到Spine层交换机上,承载了大量的二层流量,同时可以对外BGP的方式与运营商对接,既可以承载出口流量,也可以承载数据中心内部穿越SITE的二层内部流量,对于东西向流量横向扩展来说,具有历史性的意义。
1.8 Vxlan
Vxlan是由Cisco、VMware、Broadcom等厂家向IETF提出一项云计算环境下,大二层网络解决方案的一项草案,全称Virtual eXtensible Local Area Network,即虚拟扩展本地网络。虚拟化技术大规模部署的到来,使得原有的软件服务同物理硬件的分离,单个程序或者单个系统不用在单一的硬件物理服务器上运行,同时实现了硬件服务器的资源池化,保证了业务的连续性。一个完整的应用系统有着更大的发展,网络、存储、安全等问题逐渐的出现在整个资源池当中,而贯穿这些联系的因素之一就是网络,全万兆网络的架构方式改变了原有的低延迟问题,但是其本质还是属于物理架构的方式,内部各个逻辑网络的建立都以租户的形式体现出来,每个租户的隔离,每个虚拟网络的隔离,每个业务的隔离,都会耗费大量的vlan,随着vlan 的不足,数据中心规模随之逐渐扩大,多SITE的需求逐渐显现,那么每一个SITE之间的VLan domain不应该再按照原有的网络部署模式去规划,即同属于一个网络vlan domain内。原来没有的领域开始了逐渐的变化,已更好的为当下云计算体系服务,不管数据中心或者运营商都是如此,数据网络的变化就是其一。

面对这些问题,我们不得不去面对,也不得不去解决,要跨过vlan、广播、生成树这些等等传统的限制问题,网络必须进行改革,Overlay的技术逐渐体现出来,Vxlan实际上利用的原理跟OTV实现的方式差不多,但是更多得是Vxlan的支持力度却要远远大于OTV的支撑力度。
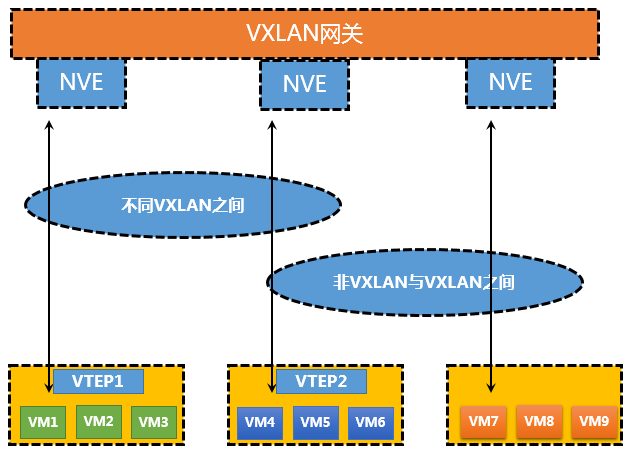
Vxlan实际上定义了一个Vtep的实体(VXLAN Tunnel End Point—虚拟扩展本地网络隧道终极节点),将虚拟化产生的流量由原有的vlan封装模式完全变为vxlan的封装模式,将产生的数据包转变为UDP的包头从内部发出,虚拟化本身的MAC地址等二层信息则会封装在内层包头内,Vtep的封装工作可以是虚拟化层或者硬件层面,但是其消耗的性能指标是我们需要考虑的一项因素。如果在虚拟化层面实现Vtep的封装工作,那么底层虚拟化流量在到达机顶交换机的时候,就已经被打上了Vtep的标签,换句话说,底层流量对于上层网络的唯一需求就是三层可达,那么对于云计算这个系统内部,若转变成三层协议进行转发,那么就回归到了传统的路由协议里面,这样的网络转发的效率与安全性就会大大增加,原有的STP等限制性因素就逐渐被打破了。
虚拟机本身的信息对外已经不可见,对外看到的只是一个传统的IP数据包,Vxlan通过新得网络标识VNI来对每一个租户的网络进行隔离,VNI取代了原有的vlan tag标识,VNI是一个24 bit的二进制标识,传统的4096个vlan的上限,VNI将可以达到16万7千VXLAN网络段,从而解决vlan 不足、vlan tag的转换问题,同时解决了多站点间同属于一个vlan domain的困境。
UDP包头:
目的端口使用4798,但是可以根据需要进行修改。UDP的校验和必须设置成全0。
IP头(外层的新三层头):
外层头的IP地址不再是原有的虚拟机通信双方的地址,而是隧道两端的网络地址,虚拟化层面来说也就是软件服务器的地址网卡IP地址,目的IP地址可以是单播地址,也可以是多播地址。单播情况下,目的IP地址是Vxlan Tunnel End Point(VTEP)的IP地址。在多播情况下引入VXLAN管理层,利用VNI和IP多播组的映射来确定VTEPs。
- protocol:设置值为0x11,显示说明这是UDP数据包
- Source ip: 源vTEP_IP;
- Destination ip: 目的VTEP IP。
外层二层头:
不再是原有的真实MAC地址,而是虚拟化软件服务器的MAC地址或者物理交换机封装Vtep隧道的接口MAC地址,这样完全就建立一个新的二层头部,而内层真实的头部在到达隧道终点将会自动进行解封装,重新封装原有数据包,实现了跨越三层传递二层信息的技术。

Vxlan数据平面:
VTEP为虚拟机的数据包加上了层包头,这些新的报头之有在数据到达目的VTEP后才会被去掉。中间路径的网络设备只会根据外层包头内的目的地址进行数据转发,对于转发路径上的网络来说,一个Vxlan数据包跟一个普通IP包相比,出了个头大一点外没有区别。
由于VXLAN的数据包在整个转发过程中保持了内部数据的完整,因此VXLAN的数据平面是一个基于隧道的数据平面。
部署场景:
- 纯vxlan场景:这种场景完全可以按照传统的部署方式去部署vxlan网络,在虚拟化层虚机直接打上vxlan的标签。
- Vxlan与vlan的混合模式:对于这种部署场景,需要一个叫做二层vxlan gateway才可以将vlan与vxlan之间进行对应,并且实现二层通信,当二层流量汇聚到三层网关时,传统SVI接口承载的是vlan模式的trunk流量,那么对于vxlan的解决方式,我们可以借用vxlan网关进行二层流量的终结,路由到运营商网络出网。
1.9 EVI
对于Vxlan来说,也许对于传统来说可能是一种选择。但是对于跨越运营商的网络,尤其是运作大型数据中心网络,如IDC,云服务提供商来说,想要建立一张完整的跨地域大二层网络,仅仅依靠Vxlan技术是不足的,evi技术可以说是基于mpls的一个整体二层逻辑网络,可以跨域运营商网络的同时,不用依靠mpls就可以建立远端邻居,将统一流量接入相同EVI就可以实现跨地域甚至跨越全球的私有网络建设。有人会说,VXLAN也可以实现类似的隧道机制,但是随着云计算的到来,我们忽视mac地址数量,PBB-EVPN的技术可以实现在边缘设备进行MAC地址汇聚,这样在建设全球性私有逻辑网络的时候,就能够对虚拟云主机的MAC地址进行汇总并宣告出去,经过隧道传递的图中,不用担心类似MAC地址的追踪,暴露自己私有MAC地址的行为。保证了整体数据中心的私有安全性问题。

如图,接入端(AC)接入,首先建立EDGE BD 为每条AC,分配一个I-SID编号,通过建立CORE BD 并且与 EDGE BD相互关联,汇聚成为一个EVI,每个evi相当于一个实例,将封装在不同vlan的子端口,桥接到一个EVI当中,路由器对数据包进行重新封装,可以进行不同vlan间的2层通讯,在3层网络上,压入标签进行转发传递主机信息,从而达到跨越数据中心的主机进行2层通讯。


二、对SDN/NFV的理解
SDN: SDN(software Defind Networking,软件定义网络)是一种由云计算的发展而带来的数据中心网络架构的升级,最大的特点就是其具有松耦合的控制平面与数据平面、支持集中化的网络状态控制,实现了底层网络对于上层应用的透明,具有灵活的网络编程能力,使得网络自动化管理与控制能力获得了空前的提升,能够有效地解决当前网络系统所面临的资源规模扩展受限,网络与业务难以进行紧密结合的需求等问题。

NFV: NFV(Network Function Virtualization)是ETSI与2012年11月成立了专门用于讨论NFV架构和技术的ISG(Industry Specification Group,行业规范组),其目标是基于软件实现网络功能并使之运行在种类广泛的业界标准设备上,NFV目前的重点是对网络功能进行虚拟化实现,它更多的实现是在OSI 4至7层的业务应用,NFV架构将控制层面进行了更细致的划分,提出了段到段(End to End,E2E)的网络控制层,能够对多个数据中心或者运营商实现不同技术,按需供给网络模型。同时也是实现SDN理念的一项专门技术方案。
SDN实现了集中控制,开放接口,网络虚拟化三大特性。
- 集中控制:
逻辑上的集中控制是网络资源的全局信息可以根据业务需要进行统一的资源池化和调配,例如:全局负载均衡、全局的流量工程等。同时集中控制使得整个网络可以看一个整体,无需向传统网络一样主意的对单独的设备进行CLI的HOP by HOP的配置,减少了原有的配置复杂性难题。 - 开放接口:
同构开放的南北向接口,实现网络和应用的无缝联系,使得应用在需要时直接可以自定义属于私有的逻辑网络,现有的网络可以承载成百上千的逻辑网络。网络可以实现按需获取,按需分配的机制。 - 网络功能虚拟化:
通过南向接口,屏蔽底层物理硬件设备,实现上层对于底层完全无感知,并且在需要的时候可以通过中央控制器获得网络相应的服务功能,包括虚拟防火墙,虚拟路由器,虚拟负载均衡器等等传统硬件设备所实现的功能。同时不再受具体设备的物理位置的限制,逻辑网络支持多租户共享,支持多租户的定制等需求。
SDN目前支持的主流功能方面也是基于Overlay的技术设计,进行相关网络功能的实现。该设计思想主要是解耦、独立、控制三个方面。
- 解耦:是指将网络的控制从物理网络当中脱离出来,可以以plug-in等方式融入到虚拟化层面,通过虚拟化层面的统一调度,控制底层硬件设备,传统的底层硬件设备处于完全的数据平面进行转发相应的流量即可。满足用户对网络资源的按需交付的需求。
- 独立:是指该类方案承载IP网络之上,只要IP可达,便可对相应的虚拟化网络进行部署,而无需对原有的物理网络架构进行任何改变,便捷地在现有网络上部署和实施。
- 控制叠加:逻辑网络例如Vxlan网络通过软件编程的方式进行统一控制,网络资源、计算资源、存储资源等资源会被统一调度与控制并能根据上层需要进行按需交付,也可以实现虚拟化网络与物理网络设备进行协同工作,从而实现网络完全的自动化机制,通过在节点间按需搭建虚拟网络,实现网络资源的虚拟化。
Openstack是业界知名的开源云计算管理平台,它提供了丰富的管理能力,已经被众多云计算需求者所接受。在其设计与实现中,与业界领先的AWS进行了对标,当前的Openstack已经具有非常完备的服务体系,主要由compute、Glance、Swift、Neutron、Dashboard、Keystone等组件组成,其中Neutron作为核心组件,已经实现了SDN的基本设计理念,并且对于相关主流网络技术实现网络功能的虚拟化,将应用与网络进行了紧密的结合。
Neutron:Neutron基于一个可插拔的架构,提供基于租户隔离的从二层到七层的虚拟化网络服务,它作为一个框架提供了统一的网络资源模型,而各个网络厂商或者不同的网络方案可以基于这个统一的模型来做具体的实现,就是Neutron中的插件,比如L2 agent或者L3 agent、dhcp agent等,并且neutron还为传统的二层到七层的网络服务提供了统一的北向编程接口,并且为二层到七层的网络分别实现了可扩展的插件结构,如支持二层网络的ML2插件,支持三层网络的核心组件,实现高级网络服务,例如负载均衡器、防火墙、VPN服务、路由协议等高级网络特性。如今,Neutron已经成为Openstack中网络虚拟化的核心项目,各家厂商可以实现他们自己的驱动来支持他们自己的网络设备,甚至可以将完整的SDN产品与OpenStack集成起来。
SDN同其他网络技术不同,它并不是针对某个项目的具体技术的革新,而是去颠覆现有组网的方式与设计理念,比如:OpenFlow的价值:“不在于Flow,而在于Open”,开源的精髓也就是在于开放,好比Neutron一样。
我们可以去畅想SDN模式下的网络架构,可能会类似今天的手机、硬件厂商只提供了一个基础平台,如果需要任何服务功能,我们都可以去相应的商店去下载,而不会受制于手机本身平台的限制。
SDN的真正使命其实是搭建一个完全开放,自主可控,按需所取得高灵活性,高可靠性的网络平台。
OpenFlow代表了一波网络潮流的防线,而握着最广泛的行业资源和客户关系的传统网络厂商的支持无疑会加快Openflow的成熟,传统厂商的选择可能成就它们下一个十年的辉煌,但是,在开源主导一切的时代下,对于传统可能也是衰败的开始。
三、未来数据中心网络与运营商网络的发展方向
在当下云计算快速发展的时代,尤其是运营商和企业,其数据中心越来越多地开始向云化网络架构发展。传统的网络发展方向、传统的网络思想、传统的网络工程师要么转型,要么就会错过这场精彩的变革。众多国内外运营商预计将会在2020年到来之际完成网络转型,企业数据中心与运营商的网络模型将会有75%是由软件控制和管理,越来越多的控制单元将会通过SDN和NFV放入到云或者最终用户手中,网络工程师的工作模式也会转变。运营商的竞争对手可能是不止运营商之间,越来越多的竞争对手会变成像亚马逊、Google云服务公司。Google曾经说,它并不是光纤网络,而是一种可提供“身体所需的用以维持活性、能力和动力”的可食用维生素。面对越来越多的互联网服务公司的业务“跨界”,运营商不得不去调整业务和技术方向去做市场竞争。
通过虚拟化、分解与重组,使数据中心与运营商的系统更加灵活、可靠、安全和高效,通过逐渐接受开源平台,使得IDC与运营商可以灵活配置和开发软件定义服务,而不用再去雇佣大量运维人员去维护这一切,底层将会完全透明、无感知的运行,加速整个云的生态系统成长。
数据中心与运营商等传统网络企业渴望转型,然而这一切并不容易,迎接新技术、新的服务模型、我们就必须对现有的员工与技术人员一起培训、否则一切都是空想,若不接受开源软件,将会被这个时代所淘汰,从而错过了一场历史性的IT变革。
现在人们每天面对的都是各种云计算互联网公司,如果传统数据中心与运营商不再转型,将不得不面临被彻底管道化、廉价化和边缘化的命运。过去终究会过去,过去的璀璨不代表将来的收益,过去已经过去,云的里程碑不再刻有曾经的名字。
四、一个网络工程师对未来的畅想
多年以前,网络或者通信工程师们,都是将各种电线插入交换板卡,而现在都是在将各种光纤插入各种板卡当中,将电话两头接起来,就可以进行通信,一个以硬件为主导的全硬件时代已然来临。今后,随着数据中化通信时代的到来,所有通信硬件设备都将注入带有各种特性的软件。但是,随着芯片技术的发展,晶体管越来越多,通信设备并没有跟上高速发展的计算机时代,由于之前我们都过于依赖硬件,每个设备功能体现都不同,也就是每个通信设备的功能与性能都比较单调,随着云计算的到来,互联网高速发展,通信网络也逐渐面临一场实现万物互联的设想,而硬件设备的私有化,硬ni ne件架构设计的固有思想,将逐步落后于时代的发展。
现在,我们可以通过虚拟化,将传统硬件转变为软件,通过软件实现传统硬件所展现的功能,并将各功能模块进行重组,重新融入到云计算中,这也许意味着,修改某个配置、实现某个功能,只需要几行代码也许就可以搞定,如果我们不接受这一切,数据中心与运营商将无法超越互联网时代快速反应市场的变化,直致慢慢淡出这个世界,落寞地谢幕。
网络将面临一场前所未有的变革时代,新的网络模型将会去分析大量数据与信息,并且在相应时间内做出快速反应,基于大数据平台量身定制的业务投放,快速疏导智能交换等通信系统。
理想是丰满的,而现实总是骨感,如果缺乏创新,缺乏接受云计算到来的学习心态,缺乏接受现实的勇气,缺乏对于新技术的使用与维护能力,尽管对硬件操作游刃有余,但是在面对海量数据、程序化的世界,大数据、云计算等新的概念完全爆发的时候,要么接受,要么错过。
备注:在本系列《漫谈云计算网络》的第二篇分享中,笔者会对云计算网络的架构模式进行分享,内容会涵盖:
- 云计算网络模式
- 跨二层虚拟网络互通
- 同一个数据中心,物理服务器和云主机结合互通
- 跨数据中心物理网络互通
- 跨数据中心私有云互通
- 跨数据中心
- VPC虚拟二层网络互通
- 公有云和私有云互通
由CSDN重磅打造的2016中国云计算技术大会(CCTC 2016)将于5月13日-15日在北京举办,大会特设“中国Spark技术峰会”、“Container技术峰会”、“OpenStack技术峰会”、“大数据核心技术与应用实战峰会”等四大技术主题峰会,以及“云计算核心技术架构”、“云计算平台构建与实践”等专场技术论坛。80+位一线互联网公司的技术专家将到场分享他们在云计算、大数据领域的技术实践,目前大会剩票不多,欲购从速。详情请点击CCTC 2016大会官网。