逻辑斯谛回归模型( Logistic Regression,LR)& 最大熵模型(Max Entropy,ME)
文章目录
- 1. Logistic Regression 模型
- 1.1 logistic 分布
- 1.2 二项逻辑斯谛回归模型
- 1.3 模型参数估计
- 1.4 多项逻辑斯谛回归
- 1.5 Python代码
- 2. Maximum Entropy 模型
- 2.1 最大熵原理
- 2.2 最大熵模型的定义
- 2.3 最大熵模型的学习
- 2.4 例题
- 3. 模型学习的最优化算法
- 4. 鸢尾花LR分类实践
1. Logistic Regression 模型
1.1 logistic 分布
定义:设 X X X 是连续随机变量, X X X 服从 logistic 分布是指 X X X 具有下列分布函数和密度函数:
F ( x ) = P ( X ≤ x ) = 1 1 + e − ( x − μ ) / γ F(x) = P(X \leq x) = \frac{1}{1+e^{{-(x-\mu)} / \gamma}} F(x)=P(X≤x)=1+e−(x−μ)/γ1
f ( x ) = F ′ ( x ) = e − ( x − μ ) / γ γ ( 1 + e − ( x − μ ) / γ ) 2 f(x)=F'(x)= \frac {e^{{-(x-\mu)} / \gamma}}{\gamma {(1+e^{{-(x-\mu)}/\gamma})}^2} f(x)=F′(x)=γ(1+e−(x−μ)/γ)2e−(x−μ)/γ
式中 μ \mu μ 为位置参数, γ > 0 \gamma > 0 γ>0 为形状参数
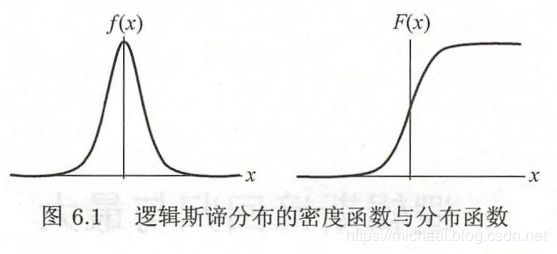
分布函数 F ( x ) F(x) F(x) 是一条S形曲线 sigmoid curve,曲线以点 ( μ , 1 2 ) (\mu, \frac{1}{2}) (μ,21) 为中心对称,即满足: F ( − x + μ ) − 1 2 = − F ( x + μ ) + 1 2 F(-x+\mu)-\frac{1}{2} = -F(x+\mu)+\frac{1}{2} F(−x+μ)−21=−F(x+μ)+21
形状参数 γ \gamma γ 的值越小,曲线在中心附近增长越快
1.2 二项逻辑斯谛回归模型
binomial logistic regression model 是一种分类模型,由条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 表示, 形式为参数化的逻辑斯谛分布。这里,随机变量 X X X 的取值为实数,随机变量 Y Y Y 取值为 1 或者 0。用监督学习的方法来估计模型参数。
二项逻辑斯谛回归模型具有下面条件概率分布:
P ( Y = 1 ∣ x ) = exp ( w x + b ) 1 + exp ( ω x + b ) P(Y=1|x) = \frac{\exp(wx+b)}{1+\exp(\omega x+b)} P(Y=1∣x)=1+exp(ωx+b)exp(wx+b)
P ( Y = 0 ∣ x ) = 1 1 + exp ( ω x + b ) P(Y=0|x) = \frac{1}{1+\exp(\omega x+b)} P(Y=0∣x)=1+exp(ωx+b)1
ω \omega ω 是权值向量, b b b 是偏置, ω ⋅ x \omega· x ω⋅x 为 ω \omega ω 和 x x x 的内积(内积,对应位置相乘,再加总)
按照上面式子,可以求得 P ( Y = 1 ∣ x ) P(Y=1|x) P(Y=1∣x) 和 P ( Y = 0 ∣ x ) P(Y=0|x) P(Y=0∣x),LR模型将实例 x x x 分到概率较大的那一类。
事件的几率(odds)是指该事件发生的概率 p p p 比上 不发生的概率 1 − p 1-p 1−p,该事件的对数几率即 log i t ( p ) = log p 1 − p \log it(p) = \log\frac{p}{1-p} logit(p)=log1−pp
对于LR来讲, log P ( Y = 1 ∣ x ) 1 − P ( Y = 1 ∣ x ) = w ⋅ x \log \frac{P(Y=1|x)}{1-P(Y=1|x)} = w· x log1−P(Y=1∣x)P(Y=1∣x)=w⋅x,就是说, Y = 1 Y=1 Y=1 的对数几率是输入 x x x 的线性函数
1.3 模型参数估计
LR模型学习时,对于给定的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}, 其中, x i ∈ R n , y i ∈ { 0 , 1 } x_i \in R^n, \quad y_i \in \{0,1\} xi∈Rn,yi∈{0,1}, 应用极大似然估计,得到 LR 模型
假设: P ( Y = 1 ∣ x ) = π ( x ) , P ( Y = 0 ∣ x ) = 1 − π ( x ) P(Y=1|x)=\pi(x), \quad\quad P(Y=0|x)=1-\pi(x) P(Y=1∣x)=π(x),P(Y=0∣x)=1−π(x)
似然函数为: ∏ i = 1 N [ π ( x i ) ] y i [ 1 − π ( x i ) ] 1 − y i \prod\limits_{i=1}^N [\pi(x_i)]^{y_i} [1-\pi(x_i)]^{1-y_i} i=1∏N[π(xi)]yi[1−π(xi)]1−yi
对数似然函数:
L ( ω ) = ∑ i = 1 N [ y i log π ( x i ) + ( 1 − y i ) log ( 1 − π ( x i ) ) ] = ∑ i = 1 N [ y i log π ( x i ) 1 − π ( x i ) + log ( 1 − π ( x i ) ) ] = ∑ i = 1 N [ y i ( ω • x i ) − log ( 1 + exp ( ω • x i ) ) ] \begin{aligned} L(\omega) &= \sum_{i=1}^N [y_i\log\pi(x_i)+(1-y_i)\log(1-\pi(x_i))] \\ &= \sum_{i=1}^N[y_i\log \frac{\pi(x_i)}{1-\pi(x_i)}+\log(1-\pi(x_i))]\\ &=\sum_{i=1}^N[y_i(\omega•x_i)-\log(1+\exp(\omega•x_i))] \end{aligned} L(ω)=i=1∑N[yilogπ(xi)+(1−yi)log(1−π(xi))]=i=1∑N[yilog1−π(xi)π(xi)+log(1−π(xi))]=i=1∑N[yi(ω•xi)−log(1+exp(ω•xi))]
对 L ( ω ) L(\omega) L(ω) 求极大值,得到 ω \omega ω 的估计值。
1.4 多项逻辑斯谛回归
上面介绍的是两类分类LR模型,可以推广到多类分类。
假设离散随机变量 Y Y Y 的取值集合是 { 1 , 2 , . . . , K } \{1,2,...,K\} {1,2,...,K}, 那么多项LR模型是:
P ( Y = k ∣ x ) = exp ( ω k • x ) 1 + ∑ k = 1 K − 1 exp ( ω k • x ) , k = 1 , 2 , . . . , K − 1 P(Y=k|x) = \frac{\exp(\omega_k•x)}{1+\sum\limits_{k=1}^{K-1}\exp(\omega_k•x)}, \quad k=1,2,...,K-1 P(Y=k∣x)=1+k=1∑K−1exp(ωk•x)exp(ωk•x),k=1,2,...,K−1
P ( Y = K ∣ x ) = 1 1 + ∑ k = 1 K − 1 exp ( ω k • x ) P(Y=K|x)=\frac{1}{1+\sum\limits_{k=1}^{K-1}\exp(\omega_k•x)} P(Y=K∣x)=1+k=1∑K−1exp(ωk•x)1
这里, x ∈ R n + 1 , ω k ∈ R n + 1 x \in R^{n+1},\quad \omega_k \in R^{n+1} x∈Rn+1,ωk∈Rn+1 (把 ω • x + b \omega•x+b ω•x+b 合并写做 ω • x \omega•x ω•x,所以 n n n 维变成 n + 1 n+1 n+1 维)
1.5 Python代码
sklearn.linear_model.LogisticRegression
# -*- coding:utf-8 -*-
# @Python Version: 3.7
# @Time: 2020/3/15 23:27
# @Author: Michael Ming
# @Website: https://michael.blog.csdn.net/
# @File: 6.LogisticRegression_MaxEntropy.py
# @Reference: https://github.com/fengdu78/lihang-code
from math import exp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
data = np.array(df.iloc[:100, [0, 1, -1]])
return data[:, :2], data[:, -1]
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
class LRclassifier():
def __init__(self, max_iter=200, learning_rate=0.01):
self.max_iter = max_iter
self.learning_rate = learning_rate
self.weights = None
def sigmoid(self, x):
return 1 / (1 + exp(-x))
def data_matrix(self, X):
data_mat = []
for d in X:
data_mat.append([1.0, *d]) # 数据加了一个截距项
return data_mat
def fit(self, X, y):
data_mat = self.data_matrix(X)
self.weights = np.zeros((len(data_mat[0]), 1), dtype=np.float32)
for iter_ in range(self.max_iter):
for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights)) # w x 内积
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]])
# 学习算法,更新 w
print('LR Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter))
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test)
for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights)
if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
def predict(self, X_test):
result = np.dot(self.data_matrix(X_test), self.weights)
if result > 0:
return 1
else:
return 0
lr_clf = LRclassifier()
lr_clf.fit(X_train, y_train)
print(lr_clf.score(X_test, y_test))
x_points = np.arange(4, 8)
y_ = -(lr_clf.weights[1] * x_points + lr_clf.weights[0]) / lr_clf.weights[2]
plt.plot(x_points, y_)
plt.scatter(X[:50, 0], X[:50, 1], label='0')
plt.scatter(X[50:, 0], X[50:, 1], label='1')
plt.legend()
plt.show()
# X_train, y_train = np.array([[3, 3, 3], [4, 3, 2], [2, 1, 2], [1, 1, 1], [-1, 0, 1], [2, -2, 1]]), np.array([1, 1, 1, 0, 0, 0])
# X_test = [[1, 2, -2]]
# lr_clf = LRclassifier()
# lr_clf.fit(X_train, y_train)
# print(lr_clf.predict(X_test))
# ---------sklearn--LR-----------------------
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(max_iter=200)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
print(clf.coef_, clf.intercept_)
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0] * x_ponits + clf.intercept_) / clf.coef_[0][1]
plt.plot(x_ponits, y_)
plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='0')
plt.plot(X[50:, 0], X[50:, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
plt.show()
2. Maximum Entropy 模型
2.1 最大熵原理
-
最大熵原理认为,学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。
-
通常用约束条件来确定概率模型的集合,所以,最大熵原理也可以表述为在满足约束条件的模型集合中选取熵最大的模型。
假设离散随机变量 X X X 的概率分布是 P ( X ) P(X) P(X), 则其熵(熵介绍请点击)是:
H ( P ) = − ∑ x P ( x ) log P ( x ) H(P) = -\sum\limits_{x}P(x)\log P(x) H(P)=−x∑P(x)logP(x)
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大。
信息熵是信息论中用于度量信息量的一个概念。一个系统越是有序,信息熵就越低;
反之,一个系统越是混乱,信息熵就越高。
熵满足不等式: 0 ≤ H ( P ) ≤ log ∣ X ∣ 0 \le H(P) \le \log|X| 0≤H(P)≤log∣X∣
∣ X ∣ |X| ∣X∣ 是 X X X 的取值个数,当且仅当 X X X 是 均匀分布 时右边等号成立; X X X 均匀分布时(离散较大,混乱,不集中), 熵最大
最大熵原理认为,要选择的概率模型首先必须满足已有约束条件。在没有更多信息的情况下,那些不确定的部分都是“等可能的 ”。最大熵原理通过熵的最大化来表示等可能性。
2.2 最大熵模型的定义
- 假设分类模型是一个条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)
- X ∈ X ⊆ R n X \in \mathcal{X} \subseteq R^n X∈X⊆Rn 表示输入
- Y ∈ Y Y \in \mathcal{Y} Y∈Y 表示输出, X , Y \mathcal{X} , \mathcal{Y} X,Y 是输入、输出的集合
- 模型:对给定的输入 X X X,以条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X) 输出 Y Y Y
- 训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}
模型应满足的条件,根据训练集,可以确定联合分布 P ( X , Y ) P(X,Y) P(X,Y) 的经验分布
- P ~ ( X = x , Y = y ) = ν ( X = x , Y = y ) N \tilde P(X=x,Y=y) = \frac{\nu(X=x,Y=y)}{N} P~(X=x,Y=y)=Nν(X=x,Y=y)
边缘分布 P ( X ) P(X) P(X) 的经验分布
- P ~ ( X = x ) = ν ( X = x ) N \tilde P(X=x)=\frac{\nu(X=x)}{N} P~(X=x)=Nν(X=x), ν \nu ν 表示频数, N N N 表示样本容量
特征函数
f ( x , y ) = { 1 , x 与 y 满 足 某 一 事 实 0 , 否 则 f(x,y)=\left\{ \begin{aligned} 1, \quad x与y满足某一事实 \\ 0, \quad 否则\quad \quad \quad \quad \quad \quad \end{aligned} \right. f(x,y)={1,x与y满足某一事实0,否则
特征函数 f ( x , y ) f(x,y) f(x,y) 关于经验分布 P ~ ( X , Y ) \tilde P(X,Y) P~(X,Y) 的期望值:
E P ~ ( f ) = ∑ x , y P ~ ( x , y ) f ( x , y ) E_{\tilde P}(f) = \sum\limits_{x,y} \tilde P(x,y)f(x,y) EP~(f)=x,y∑P~(x,y)f(x,y)
特征函数 f ( x , y ) f(x,y) f(x,y) 关于模型 P ( Y ∣ X ) P(Y|X) P(Y∣X) 与经验分布 P ~ ( X ) \tilde P(X) P~(X) 的期望值:
E P ( f ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) f ( x , y ) E_P(f) = \sum\limits_{x,y} \tilde P(x)P(y|x)f(x,y) EP(f)=x,y∑P~(x)P(y∣x)f(x,y)
如果模型能够获取训练数据中的信息,那么就可以假设这两个期望值相等,即
E P ( f ) = E P ~ ( f ) E_P(f) = E_{\tilde P}(f) EP(f)=EP~(f)
∑ x , y P ~ ( x ) P ( y ∣ x ) f ( x , y ) = ∑ x , y P ~ ( x , y ) f ( x , y ) \sum\limits_{x,y} \tilde P(x)P(y|x)f(x,y) = \sum\limits_{x,y} \tilde P(x,y)f(x,y) x,y∑P~(x)P(y∣x)f(x,y)=x,y∑P~(x,y)f(x,y)
将上式作为模型学习的约束条件。如果有 n n n 个特征函数 f i ( x , y ) f_i(x,y) fi(x,y) ,就有 n n n 个约束条件。
最大熵模型(定义):
- 假设满足所有约束条件的模型集合为:
C ≡ { P ∈ P ∣ E P ( f i ) = E P ~ ( f i ) , i = 1 , 2 , . . . , n } \mathcal{C} \equiv \{P \in \mathcal{P} | E_P(f_i)=E_{\tilde P}(f_i),i=1,2,...,n\} C≡{P∈P∣EP(fi)=EP~(fi),i=1,2,...,n} - 定义在条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X) 上的条件熵为:
H ( P ) = − ∑ x , y P ~ ( x ) P ( y ∣ x ) log P ( y ∣ x ) H(P) = -\sum\limits_{x,y} \tilde P(x)P(y|x)\log P(y|x) H(P)=−x,y∑P~(x)P(y∣x)logP(y∣x) - 则模型集合 C \mathcal{C} C 中条件熵 H ( P ) H(P) H(P) 最大的模型称为最大熵模型,对数为自然对数 e e e
2.3 最大熵模型的学习
学习过程就是约束最优化问题。
对于给定的训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)},以及特征函数 f i ( x , y ) , i = 1 , 2 , . . . , n f_i(x,y), i = 1,2,...,n fi(x,y),i=1,2,...,n,ME 模型的学习等价于约束最优化问题:
max P ∈ C H ( P ) = − ∑ x , y P ~ ( x ) P ( y ∣ x ) log P ( y ∣ x ) \max\limits_{P \in \mathcal C} \quad H(P) = - \sum\limits_{x,y} \tilde P(x)P(y|x) \log P(y|x) P∈CmaxH(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)
s . t . E P ( f i ) = E P ~ ( f i ) , i = 1 , 2 , . . . , n s.t. \quad\quad E_P(f_i)=E_{\tilde P}(f_i),i=1,2,...,n s.t.EP(fi)=EP~(fi),i=1,2,...,n
∑ y P ( y ∣ x ) = 1 \quad\quad\quad \sum\limits_y P(y|x) = 1 y∑P(y∣x)=1
按照最优化的习惯,改为求最小值问题:
min P ∈ C − H ( P ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) log P ( y ∣ x ) \color{red} \min\limits_{P \in \mathcal C} \quad -H(P) = \sum\limits_{x,y} \tilde P(x)P(y|x) \log P(y|x) P∈Cmin−H(P)=x,y∑P~(x)P(y∣x)logP(y∣x)
s . t . E P ( f i ) − E P ~ ( f i ) = 0 , i = 1 , 2 , . . . , n \color{red}s.t. \quad\quad E_P(f_i)-E_{\tilde P}(f_i) = 0, i=1,2,...,n s.t.EP(fi)−EP~(fi)=0,i=1,2,...,n
∑ y P ( y ∣ x ) = 1 \color{red}\quad\quad\quad \sum\limits_y P(y|x) = 1 y∑P(y∣x)=1
求解:
引进拉格朗日乘子 ω 0 , ω 1 , ω 2 , . . . , ω n \omega_0,\omega_1,\omega_2,...,\omega_n ω0,ω1,ω2,...,ωn,定义拉格朗日函数 L ( P , ω ) L(P,\omega) L(P,ω) :
L ( P , ω ) ≡ − H ( P ) + ω 0 ( 1 − ∑ y P ( y ∣ x ) ) + ∑ i = 1 n ω i ( E P ~ ( f i ) − E P ( f i ) ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) log P ( y ∣ x ) + ω 0 ( 1 − ∑ y P ( y ∣ x ) ) + ∑ i = 1 n ω i ( ∑ x , y P ~ ( x , y ) f i ( x , y ) − ∑ x , y P ~ ( x ) P ( y ∣ x ) f i ( x , y ) ) \begin{aligned} L(P,\omega) &\equiv -H(P) + \omega_0 \Bigg (1-\sum\limits_y P(y|x)\Bigg) + \sum\limits_{i=1}^n \omega_i(E_{\tilde P}(f_i)-E_{ P}(f_i))\\ &= \sum\limits_{x,y} \tilde P(x)P(y|x) \log P(y|x) + \omega_0 \Bigg (1-\sum\limits_y P(y|x)\Bigg) + \\ &\quad \sum\limits_{i=1}^n \omega_i\Bigg (\sum\limits_{x,y} \tilde P(x,y)f_i(x,y) - \sum\limits_{x,y} \tilde P(x)P(y|x)f_i(x,y) \Bigg ) \end{aligned} L(P,ω)≡−H(P)+ω0(1−y∑P(y∣x))+i=1∑nωi(EP~(fi)−EP(fi))=x,y∑P~(x)P(y∣x)logP(y∣x)+ω0(1−y∑P(y∣x))+i=1∑nωi(x,y∑P~(x,y)fi(x,y)−x,y∑P~(x)P(y∣x)fi(x,y))
通过求解对偶问题求解原始问题。
最优化原始问题: min P ∈ C max ω L ( P , ω ) \min\limits_{P \in \mathcal {C} }\max\limits_{\omega} L(P,\omega) P∈CminωmaxL(P,ω)
对偶问题: max ω min P ∈ C L ( P , ω ) \max\limits_{\omega} \min\limits_{P \in \mathcal {C} } L(P,\omega) ωmaxP∈CminL(P,ω)
先求对偶问题内部的极小化问题 min P ∈ C L ( P , ω ) \min\limits_{P \in \mathcal {C} } L(P,\omega) P∈CminL(P,ω), min P ∈ C L ( P , ω ) \min\limits_{P \in \mathcal {C} } L(P,\omega) P∈CminL(P,ω) 是 ω \omega ω 的函数,记为:
Ψ ( ω ) = min P ∈ C L ( P , ω ) = L ( P ω , ω ) \Psi(\omega) = \min\limits_{P \in \mathcal{C}}L(P,\omega) = L(P_\omega , \omega) Ψ(ω)=P∈CminL(P,ω)=L(Pω,ω), 称为对偶函数
对偶函数的解记为: P ω = arg min P ∈ C L ( P , ω ) = P ω ( y ∣ x ) P_\omega = \argmin\limits_{P \in \mathcal {C} }L(P,\omega) = P_\omega(y|x) Pω=P∈CargminL(P,ω)=Pω(y∣x)
L ( P , ω ) L(P,\omega) L(P,ω) 对 P ( y ∣ x ) P(y|x) P(y∣x) 求偏导数:
∂ L ( P , ω ) ∂ P ( y ∣ x ) = ∑ x , y P ~ ( x ) ( log P ( y ∣ x ) + 1 ) − ∑ y ω 0 − ∑ x , y ( P ~ ( x ) ∑ i = 1 n ω i f i ( x , y ) ) = ∑ x , y P ~ ( x ) ( log P ( y ∣ x ) + 1 − ω 0 − ∑ i = 1 n ω i f i ( x , y ) ) \begin{aligned} \frac{\partial L(P,\omega) }{\partial P(y|x)} &= \sum\limits_{x,y} \tilde P(x) (\log P(y|x)+1) - \sum\limits_y \omega_0 -\sum\limits_{x,y}\Bigg(\tilde P(x) \sum\limits_{i=1}^n \omega_if_i(x,y) \Bigg)\\ &= \sum\limits_{x,y} \tilde P(x) \Bigg(\log P(y|x) + 1 - \omega_0 - \sum\limits_{i=1}^n \omega_if_i(x,y) \Bigg) \end{aligned} ∂P(y∣x)∂L(P,ω)=x,y∑P~(x)(logP(y∣x)+1)−y∑ω0−x,y∑(P~(x)i=1∑nωifi(x,y))=x,y∑P~(x)(logP(y∣x)+1−ω0−i=1∑nωifi(x,y))
令偏导数等于0,在 P ~ ( x ) > 0 \tilde P(x) > 0 P~(x)>0 的情况下,有
P ( y ∣ x ) = exp ( ∑ i = 1 n ω i f i ( x , y ) + ω 0 − 1 ) = exp ( ∑ i = 1 n ω i f i ( x , y ) ) exp ( 1 − ω 0 ) P(y|x) = \exp \Bigg( \sum\limits_{i=1}^n \omega_if_i(x,y) + \omega_0 -1 \Bigg) = \frac{\exp \Bigg( \sum\limits_{i=1}^n \omega_if_i(x,y) \Bigg)}{\exp (1- \omega_0)} P(y∣x)=exp(i=1∑nωifi(x,y)+ω0−1)=exp(1−ω0)exp(i=1∑nωifi(x,y))
由于 ∑ y P ( y ∣ x ) = 1 \sum\limits_y P(y|x) = 1 y∑P(y∣x)=1, 得
P ω ( y ∣ x ) = 1 Z ω ( x ) exp ( ∑ i = 1 n ω i f i ( x , y ) ) , 其 中 Z ω ( x ) = ∑ y exp ( ∑ i = 1 n ω i f i ( x , y ) ) \color{red} P_\omega(y|x) = \frac{1}{Z_\omega(x)} \exp \Bigg( \sum\limits_{i=1}^n \omega_if_i(x,y) \Bigg), 其中 Z_\omega(x) = \sum\limits_y\exp \Bigg( \sum\limits_{i=1}^n \omega_if_i(x,y) \Bigg) Pω(y∣x)=Zω(x)1exp(i=1∑nωifi(x,y)),其中Zω(x)=y∑exp(i=1∑nωifi(x,y))
Z ω ( x ) Z_\omega(x) Zω(x) 是规范化因子; f i ( x , y ) f_i(x,y) fi(x,y) 是特征函数; ω i \omega_i ωi 是特征的权值。
红色部分就是最大熵模型, ω \omega ω 是ME模型中的参数向量。
再求解对偶问题外部的极大化问题 max ω Ψ ( ω ) \max\limits_\omega \Psi(\omega) ωmaxΨ(ω)
其解记为 ω ∗ \omega^* ω∗, ω ∗ = arg max ω Ψ ( ω ) \omega^* = \argmax\limits_\omega \Psi(\omega) ω∗=ωargmaxΨ(ω)
应用最优化算法求对偶函数 Ψ ( ω ) \Psi(\omega) Ψ(ω) 的极大化, 得到 ω ∗ \omega^* ω∗, 用来表示 P ∗ ∈ C P^* \in \mathcal{C} P∗∈C, 这里 P ∗ = P ω ∗ = P ω ∗ ( y ∣ x ) P^* = P_{\omega^*} = P_{\omega^*}(y|x) P∗=Pω∗=Pω∗(y∣x) 是学习到的最优模型(最大熵模型)。
2.4 例题
假设随机变量 X X X 有5个取值 { A , B , C , D , E } \{A,B,C,D,E\} {A,B,C,D,E},要估计各个值的概率 P ( A ) , P ( B ) , P ( C ) , P ( D ) , P ( E ) P(A),P(B),P(C),P(D),P(E) P(A),P(B),P(C),P(D),P(E),其中 P ( A ) + P ( B ) = 3 10 P(A)+P(B) = \frac{3}{10} P(A)+P(B)=103,求最大熵模型。
解:
用 y 1 , y 2 , y 3 , y 4 , y 5 y_1,y_2,y_3,y_4,y_5 y1,y2,y3,y4,y5 表示 A , B , C , D , E A,B,C,D,E A,B,C,D,E,最大熵模型学习的最优化问题是:
min − H ( P ) = ∑ i = 1 5 P ( y i ) log P ( y i ) \min \quad -H(P) = \sum\limits_{i=1}^5 P(y_i) \log P(y_i) min−H(P)=i=1∑5P(yi)logP(yi)
s . t . P ( y 1 ) + P ( y 2 ) = P ~ ( y 1 ) + P ~ ( y 2 ) = 3 10 s.t. \quad\quad P(y_1)+P(y_2) = \tilde P(y_1)+\tilde P(y_2) = \frac{3}{10} s.t.P(y1)+P(y2)=P~(y1)+P~(y2)=103
∑ i = 1 5 P ( y i ) = ∑ i = 1 5 P ~ ( y i ) = 1 \quad\quad\quad \sum\limits_{i=1}^5 P(y_i) = \sum\limits_{i=1}^5 \tilde P(y_i) = 1 i=1∑5P(yi)=i=1∑5P~(yi)=1
- 引进拉格朗日乘子 ω 0 , ω 1 \omega_0, \omega_1 ω0,ω1 , 定义拉格朗日函数:
L ( P , ω ) = ∑ i = 1 5 P ( y i ) log P ( y i ) + ω 1 ( P ( y 1 ) + P ( y 2 ) − 3 10 ) + ω 0 ( ∑ i = 1 5 P ( y i ) − 1 ) L(P,\omega) = \sum\limits_{i=1}^5 P(y_i) \log P(y_i) + \omega_1 \Bigg(P(y_1)+P(y_2) - \frac{3}{10} \Bigg) + \omega_0 \Bigg( \sum\limits_{i=1}^5 P(y_i)-1 \Bigg) L(P,ω)=i=1∑5P(yi)logP(yi)+ω1(P(y1)+P(y2)−103)+ω0(i=1∑5P(yi)−1)
根据拉格朗日对偶性,可以通过求解对偶最优化问题得到原始最优化问题的解,所以求解: max ω min P L ( P , ω ) \max\limits_\omega \min\limits_P L(P,\omega) ωmaxPminL(P,ω)
- 求解 L ( P , ω ) L(P,\omega) L(P,ω) 关于 P P P 的极小化问题,求偏导:
∂ L ( P , ω ) ∂ P ( y 1 ) = 1 + log P ( y 1 ) + ω 1 + ω 0 ∂ L ( P , ω ) ∂ P ( y 2 ) = 1 + log P ( y 2 ) + ω 1 + ω 0 ∂ L ( P , ω ) ∂ P ( y 3 ) = 1 + log P ( y 3 ) + ω 0 ∂ L ( P , ω ) ∂ P ( y 4 ) = 1 + log P ( y 4 ) + ω 0 ∂ L ( P , ω ) ∂ P ( y 5 ) = 1 + log P ( y 5 ) + ω 0 \begin{aligned} \frac{\partial L(P,\omega)}{\partial P(y_1)} &= 1+\log P(y_1) + \omega_1 + \omega_0\\ \frac{\partial L(P,\omega)}{\partial P(y_2)} &= 1+\log P(y_2) + \omega_1 + \omega_0\\ \frac{\partial L(P,\omega)}{\partial P(y_3)} &= 1+\log P(y_3) + \omega_0\\ \frac{\partial L(P,\omega)}{\partial P(y_4)} &= 1+\log P(y_4) + \omega_0\\ \frac{\partial L(P,\omega)}{\partial P(y_5)} &= 1+\log P(y_5) + \omega_0\\ \end{aligned} ∂P(y1)∂L(P,ω)∂P(y2)∂L(P,ω)∂P(y3)∂L(P,ω)∂P(y4)∂L(P,ω)∂P(y5)∂L(P,ω)=1+logP(y1)+ω1+ω0=1+logP(y2)+ω1+ω0=1+logP(y3)+ω0=1+logP(y4)+ω0=1+logP(y5)+ω0
- 令各偏导数等于0,解得:
P ( y 1 ) = P ( y 2 ) = e − ω 1 − ω 0 − 1 P ( y 3 ) = P ( y 4 ) = P ( y 5 ) = e − ω 0 − 1 \begin{aligned} P(y_1) &= P(y_2) = e^{-\omega_1-\omega_0-1}\\ P(y_3) &= P(y_4) = P(y_5) = e^{-\omega_0-1} \end{aligned} P(y1)P(y3)=P(y2)=e−ω1−ω0−1=P(y4)=P(y5)=e−ω0−1
于是:
min P L ( P , ω ) = L ( P ω , ω ) = − 2 e − ω 1 − ω 0 − 1 − 3 e − ω 0 − 1 − 3 10 ω 1 − ω 0 \min\limits_P L(P,\omega) = L(P_\omega,\omega) = -2e^{-\omega_1-\omega_0-1}-3e^{-\omega_0-1}-\frac{3}{10}\omega_1-\omega_0 PminL(P,ω)=L(Pω,ω)=−2e−ω1−ω0−1−3e−ω0−1−103ω1−ω0
- 再求解 L ( P ω , ω ) L(P_\omega,\omega) L(Pω,ω) 关于 ω \omega ω 的极大化问题:
max ω L ( P ω , ω ) = − 2 e − ω 1 − ω 0 − 1 − 3 e − ω 0 − 1 − 3 10 ω 1 − ω 0 \max\limits_\omega L(P_\omega,\omega) = -2e^{-\omega_1-\omega_0-1}-3e^{-\omega_0-1}-\frac{3}{10}\omega_1-\omega_0 ωmaxL(Pω,ω)=−2e−ω1−ω0−1−3e−ω0−1−103ω1−ω0
上式对 ω 0 , ω 1 \omega_0, \omega_1 ω0,ω1求偏导数并令其等于0,有:
e − ω 1 − ω 0 − 1 = 3 20 e^{-\omega_1-\omega_0-1} = \frac{3}{20} e−ω1−ω0−1=203
e − ω 0 − 1 = 7 30 e^{-\omega_0-1} = \frac{7}{30} e−ω0−1=307
于是求得概率分布:
P ( y 1 ) = P ( y 2 ) = 3 20 P ( y 3 ) = P ( y 4 ) = P ( y 5 ) = 7 30 \begin{aligned} P(y_1) &= P(y_2) = \frac{3}{20}\\ P(y_3) &= P(y_4) = P(y_5) = \frac{7}{30} \end{aligned} P(y1)P(y3)=P(y2)=203=P(y4)=P(y5)=307
3. 模型学习的最优化算法
常用的方法有 改进的迭代尺度法、梯度下降法、牛顿法或拟牛顿法。牛顿法或拟牛顿法一般收敛速度更快。
(略)
4. 鸢尾花LR分类实践
基于sklearn的LogisticRegression二分类实践
基于sklearn的LogisticRegression鸢尾花多类分类实践