Flink源码系列——获取StreamGraph的过程
接着《Flink源码系列——一个简单的数据处理功能的实现过程》一文的结尾继续分析,在完成对数据流的转换操作之后,需要执行任务,这时会调用如下代码:
env.execute("Socket Window WordCount");在StreamExecutionEnvironment中,这是一个抽象方法,具体的实现在其子类中,其子类StreamContextEnvironment的实现如下:
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull("Streaming Job name should not be null.");
StreamGraph streamGraph = this.getStreamGraph();
streamGraph.setJobName(jobName);
transformations.clear();
// execute the programs
if (ctx instanceof DetachedEnvironment) {
LOG.warn("Job was executed in detached mode, the results will be available on completion.");
((DetachedEnvironment) ctx).setDetachedPlan(streamGraph);
return DetachedEnvironment.DetachedJobExecutionResult.INSTANCE;
} else {
return ctx
.getClient()
.run(streamGraph, ctx.getJars(), ctx.getClasspaths(), ctx.getUserCodeClassLoader(), ctx.getSavepointRestoreSettings())
.getJobExecutionResult();
}
}这里先分析StreamGraph的获取过程,所以这里只看这句代码的执行过程:
StreamGraph streamGraph = this.getStreamGraph();进一步的调用了父类的方法,实现如下:
public StreamGraph getStreamGraph() {
if (transformations.size() <= 0) {
throw new IllegalStateException("No operators defined in streaming topology. Cannot execute.");
}
return StreamGraphGenerator.generate(this, transformations);
}这里的transformations这个列表就是在对数据流的处理过程中,会将flatMap、reduce这些转换操作对应的StreamTransformation保存下来的列表,根据对数据流做的转换操作,这个列表中,当前保存的对象有:
a、表示flatMap操作的OneInputTransformation对象,其input属性指向的是数据源的转换SourceTransformation。
b、表示reduce操作的OneInputTransformation对象,其input属性指向的是表示keyBy的转换PartitionTransformation,而PartitionTransformation的input属性指向的是flatMap的转换OneInputTransformation;
c、sink操作对应的SinkTransformation对象,其input属性指向的是reduce转化的OneInputTransformation对象。
接着调用StreamGraphGenerator的generate方法来获取transformations列表对应的StreamGraph。从这里可以看出,数据流在经过各种转换操作之后,各种转换的相关信息都已经保存在了transformations这个列表里的元素中了。继续向下看代码:
public static StreamGraph generate(StreamExecutionEnvironment env, List> transformations) {
return new StreamGraphGenerator(env).generateInternal(transformations);
} 可以看到,先以evn为构造函数的入参,构建了一个StreamGraphGenerator实例,看下构造函数的实现:
private StreamGraphGenerator(StreamExecutionEnvironment env) {
this.streamGraph = new StreamGraph(env);
this.streamGraph.setChaining(env.isChainingEnabled());
this.streamGraph.setStateBackend(env.getStateBackend());
this.env = env;
this.alreadyTransformed = new HashMap<>();
}这个构造函数是private的,所以StreamGraphGenerator的实例构造只能通过其静态的generate方法。另外在构造函数中,初始化了一个StreamGraph实例,并设置了一些属性值,然后给env赋值,并初始化alreadyTransformed为一个空map。再看下StreamGraph的构造函数实现。
public StreamGraph(StreamExecutionEnvironment environment) {
this.environment = environment;
this.executionConfig = environment.getConfig();
this.checkpointConfig = environment.getCheckpointConfig();
/** 构建一个空的新StreamGraph */
clear();
}
public void clear() {
streamNodes = new HashMap<>();
virtualSelectNodes = new HashMap<>();
virtualSideOutputNodes = new HashMap<>();
virtualPartitionNodes = new HashMap<>();
vertexIDtoBrokerID = new HashMap<>();
vertexIDtoLoopTimeout = new HashMap<>();
iterationSourceSinkPairs = new HashSet<>();
sources = new HashSet<>();
sinks = new HashSet<>();
}可以看出其构造函数中就是做了一些初始化的操作,给StreamGraph的各个属性设置初始值,都是一些空集合。
在获取到StreamGraphGenerator的实例后,继续看其generatorInternal方法的逻辑:
private StreamGraph generateInternal(List>> transformations) {
for (StreamTransformation> transformation: transformations) {
transform(transformation);
}
return streamGraph;
} 逻辑很明了,就是顺序遍历transformations列表中的元素,然后依次转换,最后返回转化好的StreamGraph的实例。
1、flatMap对应StreamTransformation子类实例的转化
接下来就看下,对于transformations列表中的每个元素是如何转化的。
private Collection transform(StreamTransformation transform) {
/** 判断传入的transform是否已经被转化过, 如果已经转化过, 则直接返回转化后对应的结果 */
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
/** 对于该transform, 如果没有设置最大并行度, 则尝试获取job的最大并行度, 并设置给它 */
if (transform.getMaxParallelism() <= 0) {
/** 如果最大并行度没有设置, 如果job设置了最大并行度,则获取job最大并行度 */
int globalMaxParallelismFromConfig = env.getConfig().getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
/** 这里调用该方法的目的就是为了尽早发现, 输出数据类型信息是否丢失, 抛出异常 */
transform.getOutputType();
/** 针对不同的StreamTransformation的子类实现,委托不同的方法进行转化 */
Collection transformedIds;
if (transform instanceof OneInputTransformation) {
transformedIds = transformOneInputTransform((OneInputTransformation) transform);
} else if (transform instanceof TwoInputTransformation) {
transformedIds = transformTwoInputTransform((TwoInputTransformation) transform);
} else if (transform instanceof SourceTransformation) {
transformedIds = transformSource((SourceTransformation) transform);
} else if (transform instanceof SinkTransformation) {
transformedIds = transformSink((SinkTransformation) transform);
} else if (transform instanceof UnionTransformation) {
transformedIds = transformUnion((UnionTransformation) transform);
} else if (transform instanceof SplitTransformation) {
transformedIds = transformSplit((SplitTransformation) transform);
} else if (transform instanceof SelectTransformation) {
transformedIds = transformSelect((SelectTransformation) transform);
} else if (transform instanceof FeedbackTransformation) {
transformedIds = transformFeedback((FeedbackTransformation) transform);
} else if (transform instanceof CoFeedbackTransformation) {
transformedIds = transformCoFeedback((CoFeedbackTransformation) transform);
} else if (transform instanceof PartitionTransformation) {
transformedIds = transformPartition((PartitionTransformation) transform);
} else if (transform instanceof SideOutputTransformation) {
transformedIds = transformSideOutput((SideOutputTransformation) transform);
} else {
throw new IllegalStateException("Unknown transformation: " + transform);
}
/** 将转化结果记录到alreadyTransformed这个map中,这里做条件判断,是考虑到迭代转换下,transform会先添加自身,再转化反馈边界 */
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
/** 将transform的相应属性设置到其在streamGraph中对应的节点上 */
if (transform.getBufferTimeout() > 0) {
streamGraph.setBufferTimeout(transform.getId(), transform.getBufferTimeout());
}
if (transform.getUid() != null) {
streamGraph.setTransformationUID(transform.getId(), transform.getUid());
}
if (transform.getUserProvidedNodeHash() != null) {
streamGraph.setTransformationUserHash(transform.getId(), transform.getUserProvidedNodeHash());
}
if (transform.getMinResources() != null && transform.getPreferredResources() != null) {
streamGraph.setResources(transform.getId(), transform.getMinResources(), transform.getPreferredResources());
}
/** 返回转化结果 */
return transformedIds;
} 在进行一些校验和设置后,会根据StreamTransformation的不同实现子类,调用不同的方法进行转化,转化完成后,记录到alreadyTransformed这个map中,再将一些属性设置到streamGraph中对应的节点上,并返回转化结果。
先来看transformations这个列表中的第一个元素,flatMap对应的OneInputTransformation的转化过程。通过上述代码,对于OneInputTransformation,执行如下:
if (transform instanceof OneInputTransformation) {
transformedIds = transformOneInputTransform((OneInputTransformation) transform);
}
private Collection transformOneInputTransform(OneInputTransformation transform) {
/** 先递归转化对应的input属性 */
Collection inputIds = transform(transform.getInput());
/** 在递归调用过程中,有可能已经被转化过 */
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
/** 判断transform的槽共享组的名称 */
String slotSharingGroup = determineSlotSharingGroup(transform.getSlotSharingGroup(), inputIds);
/** 添加新的节点 */
streamGraph.addOperator(transform.getId(),
slotSharingGroup,
transform.getOperator(),
transform.getInputType(),
transform.getOutputType(),
transform.getName());
/** 属性设置 */
if (transform.getStateKeySelector() != null) {
TypeSerializer keySerializer = transform.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(transform.getId(), transform.getStateKeySelector(), keySerializer);
}
streamGraph.setParallelism(transform.getId(), transform.getParallelism());
streamGraph.setMaxParallelism(transform.getId(), transform.getMaxParallelism());
/** 构建edge */
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}
/** 将transform的id封装成一个集合返回 */
return Collections.singleton(transform.getId());
} 转化过程,先递归转化其input,由于递归转化中,可能自身已经被转化,如果转化,则返回转化好的结果,如果没有,则继续获取其槽共享组名称,在streamGraph中添加operator节点,然后进行属性设置,再进行edge的构建,最后返回自身id构成的集合。
对于这里的flatMap对应的OneInputTransformation,其input属性的值是数据源的转换SourceTransformation,所以先来看下递归调用转化SourceTransformation的逻辑。
private Collection transformSource(SourceTransformation source) {
/** 对于数据流的源来说, 如果用户没有指定slotSharingGroup, 这里返回的就是"default" */
String slotSharingGroup = determineSlotSharingGroup(source.getSlotSharingGroup(), new ArrayList());
streamGraph.addSource(source.getId(),
slotSharingGroup,
source.getOperator(),
null,
source.getOutputType(),
"Source: " + source.getName());
if (source.getOperator().getUserFunction() instanceof InputFormatSourceFunction) {
InputFormatSourceFunction fs = (InputFormatSourceFunction) source.getOperator().getUserFunction();
streamGraph.setInputFormat(source.getId(), fs.getFormat());
}
streamGraph.setParallelism(source.getId(), source.getParallelism());
streamGraph.setMaxParallelism(source.getId(), source.getMaxParallelism());
return Collections.singleton(source.getId());
} 对于每个StreamTransformation在转化的时候,都会需要决定其所属的槽共享组的名称,来看下决定的逻辑。
private String determineSlotSharingGroup(String specifiedGroup, Collection inputIds) {
/** 如果以及指定了,则直接返回指定值 */
if (specifiedGroup != null) {
return specifiedGroup;
} else {
/** 如果没有指定,则遍历输入节点对应的槽共享组名称 */
String inputGroup = null;
for (int id: inputIds) {
String inputGroupCandidate = streamGraph.getSlotSharingGroup(id);
if (inputGroup == null) {
inputGroup = inputGroupCandidate;
} else if (!inputGroup.equals(inputGroupCandidate)) {
return "default";
}
}
/** 如果还没null,则返回"default" */
return inputGroup == null ? "default" : inputGroup;
}
} 上述逻辑分为以下几种情况:
a、如果指定了分组名,则直接返回指定的值;
b、如果没有指定分组名,则遍历输入的各个节点的分组名;b.1、如果所有输入的分组名都是一样的,则将这个一样的分组名作为当前节点的分组名;
b.2、如果所有输入的分组名有不一样的,则返回默认分组名”default”;
对于这里,在转化SourceTransformation时,由于没有设定指定的槽共享分组名,同时它是数据源,没有输入,所有其slotSharingGroup的值为”default”。分组名确定后,就会向streamGraph中添加一个source。对于source来说,输入数据类型为null,操作符名称拼接够就是”Source: Socket Stream”,添加逻辑如下:
public <IN, OUT> void addSource(Integer vertexID,
String slotSharingGroup,
StreamOperator<OUT> operatorObject,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
addOperator(vertexID, slotSharingGroup, operatorObject, inTypeInfo, outTypeInfo, operatorName);
sources.add(vertexID);
}先调用addOperator方法,添加一个新的节点,然后将节点的id,其实就是SourceTransformation的ID,这里就是1,添加到sources这个集合中。看下添加操作符节点的逻辑。
public void addOperator(
Integer vertexID,
String slotSharingGroup,
StreamOperator operatorObject,
TypeInformation inTypeInfo,
TypeInformation outTypeInfo,
String operatorName) {
/** 根据操作符的不同类型, 决定不同的节点类, 进行节点的构造 */
if (operatorObject instanceof StoppableStreamSource) {
addNode(vertexID, slotSharingGroup, StoppableSourceStreamTask.class, operatorObject, operatorName);
} else if (operatorObject instanceof StreamSource) {
addNode(vertexID, slotSharingGroup, SourceStreamTask.class, operatorObject, operatorName);
} else {
addNode(vertexID, slotSharingGroup, OneInputStreamTask.class, operatorObject, operatorName);
}
/** 确定输入和输出的序列化器, 类型不为null, 且不是MissingTypeInfo, 则构造对应的序列化器, 否则序列化器为null */
TypeSerializer inSerializer = inTypeInfo != null && !(inTypeInfo instanceof MissingTypeInfo) ? inTypeInfo.createSerializer(executionConfig) : null;
TypeSerializer outSerializer = outTypeInfo != null && !(outTypeInfo instanceof MissingTypeInfo) ? outTypeInfo.createSerializer(executionConfig) : null;
/** 设置序列化器 */
setSerializers(vertexID, inSerializer, null, outSerializer);
/** 根据操作符类型, 进行输出数据类型设置 */
if (operatorObject instanceof OutputTypeConfigurable && outTypeInfo != null) {
@SuppressWarnings("unchecked")
OutputTypeConfigurable outputTypeConfigurable = (OutputTypeConfigurable) operatorObject;
outputTypeConfigurable.setOutputType(outTypeInfo, executionConfig);
}
/** 根据操作符类型, 进行输入数据类型判断 */
if (operatorObject instanceof InputTypeConfigurable) {
InputTypeConfigurable inputTypeConfigurable = (InputTypeConfigurable) operatorObject;
inputTypeConfigurable.setInputType(inTypeInfo, executionConfig);
}
/** 根据配置, 打印调试日志 */
if (LOG.isDebugEnabled()) {
LOG.debug("Vertex: {}", vertexID);
}
} 其中会根据operatorObject的不同类型,在添加节点,以及后续的节点配置中,做一些特定配置。逻辑比较清晰,详见注解。
addNode方法的逻辑如下,就是新建了一个StreamNode实例作为新的节点,然后保存到streamNodes这个map中,key是节点id,value就是节点StreamNode。StreamNode就是用来描述流处理中的一个节点,其包含了该节点对数据的操作符,并行度,输入输出数据类型,分区等属性,以及这个节点与上游节点链接的StreamEdge集合,与下游节点链接的StreamEdge集合。
protected StreamNode addNode(Integer vertexID,
String slotSharingGroup,
Class vertexClass,
StreamOperator operatorObject,
String operatorName) {
/** 校验添加新节点的id, 与已添加的节点id, 是否有重复, 如果有, 则抛出异常*/
if (streamNodes.containsKey(vertexID)) {
throw new RuntimeException("Duplicate vertexID " + vertexID);
}
StreamNode vertex = new StreamNode(environment,
vertexID,
slotSharingGroup,
operatorObject,
operatorName,
new ArrayList>(),
vertexClass);
/** 将新构建的节点保存记录 */
streamNodes.put(vertexID, vertex);
return vertex;
} 到这里,数据源节点就添加到了streamGraph中,然后就可以回到flatMap对应的OneInputTransformation的转化操作中。
flatMap对应的OneInputTransformation在递归转化完其输入后,也会决定其slotSharingGroup的值,这里决定的结果也是”default”。然后调用streamGraph的addOperator方法进行节点添加,对应的节点的id是2,并增加到StreamGraph的属性streamNodes这个map中,key的值是2。
在节点这两个节点构建好之后,会进行edge的构建,如下:
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId, transform.getId(), 0);
}这里来说,inputId这个集合只有一个值,就是1,表示数据源节点。而这里就会构建一个节点id为1到节点id为2的edge。
public void addEdge(Integer upStreamVertexID, Integer downStreamVertexID, int typeNumber) {
addEdgeInternal(upStreamVertexID,
downStreamVertexID,
typeNumber,
null,
new ArrayList(),
null);
} 真正的添加逻辑在addEdgeInternal方法中。该方法中,会构建一个StreamEdge。StreamEdge是用来描述流拓扑中的一个边界,其有对一个的源StreamNode和目标StreamNode,以及数据在源到目标直接转发时,进行的分区与select等操作的逻辑。接下来看StreamEdge的新增逻辑。
private void addEdgeInternal(Integer upStreamVertexID,
Integer downStreamVertexID,
int typeNumber,
StreamPartitioner partitioner,
List outputNames,
OutputTag outputTag) {
/** 根据源节点的id,判断进入不同的处理逻辑 */
if (virtualSideOutputNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSideOutputNodes.get(virtualId).f0;
if (outputTag == null) {
outputTag = virtualSideOutputNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, null, outputTag);
} else if (virtualSelectNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualSelectNodes.get(virtualId).f0;
if (outputNames.isEmpty()) {
// selections that happen downstream override earlier selections
outputNames = virtualSelectNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);
} else if (virtualPartitionNodes.containsKey(upStreamVertexID)) {
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);
} else {
/** 根据上下节点的id,分别获取对应的StreamNode实例 */
StreamNode upstreamNode = getStreamNode(upStreamVertexID);
StreamNode downstreamNode = getStreamNode(downStreamVertexID);
/** 如果没有指定分区器,并且上游节点和下游节点的操作符的并行度也是一样的话,就采用forward分区,否则,采用rebalance分区 */
if (partitioner == null && upstreamNode.getParallelism() == downstreamNode.getParallelism()) {
partitioner = new ForwardPartitioner 对于这里的flatMap的OneInputTransformation的转化来说,这里在添加StreamEdge时,是直接进入else逻辑,由于数据源和flatMap都是并行度为1,所以会得到ForwardPartitioner的实例作为分区器。
这样就处理完了flatMap对应的OneInputTransformation的转化操作,并将转化结果记录在StreamGraph中,source和faltMap对应的StreamNode之间构建了一个StreamEdge。
2、reduce对应StreamTransformation子类实例的转化
接下来再看继续分析transformations这个列表中的第二个元素,表示reduce操作的OneInputTransformation对象,其input属性指向的是表示keyBy的转换PartitionTransformation,而PartitionTransformation的input属性指向的是flatMap的转换OneInputTransformation。
由于flatMap以及source在前面已经转化完成,所以在递归调用的过程中,都是直接返回转化后的结果。然后就会轮到keyBy对应的PartitionTransformation的转化。
private Collection transformPartition(PartitionTransformation partition) {
StreamTransformation input = partition.getInput();
List resultIds = new ArrayList<>();
/** 递归转化输入 */
Collection transformedIds = transform(input);
for (Integer transformedId: transformedIds) {
int virtualId = StreamTransformation.getNewNodeId();
streamGraph.addVirtualPartitionNode(transformedId, virtualId, partition.getPartitioner());
resultIds.add(virtualId);
}
return resultIds;
} 由于其输入是flatMap转换,已经转化过,可以直接获取到transformedIds集合的元素就是2。因为分区转换是虚拟操作,所以产生一个虚拟节点的id为6,然后就是在streamGraph中添加一个虚拟分区节点。
public void addVirtualPartitionNode(Integer originalId, Integer virtualId, StreamPartitioner partitioner) {
if (virtualPartitionNodes.containsKey(virtualId)) {
throw new IllegalStateException("Already has virtual partition node with id " + virtualId);
}
virtualPartitionNodes.put(virtualId,
new Tuple2>(originalId, partitioner));
} 逻辑很清晰,对于这里,就是originalId=2,virtualId=6,所以在virtualPartitionNodes这个map中就新增映射:6 ——> [2, partitioner]。
接下来开始转换reduce自身的StreamTransformation子类实例,因为也是OneInputTransformation实例,在flatMap中已经介绍过,这里就不再详细介绍,但是对于reduce又有一些不同的地方,这里就分析其不同的地方,而不同的地方就在于构建StreamEdge时,略有不同。
调用addEdge方法时的,upStreamVertexID为6,对应于keyBy产生的虚拟节点,downStreanVertexID为4,对应于reduce产生的节点。所在addEdgeInternal方法中,由于upStreamVertexID=6是被添加在virtualPartitionNodes这个map中的,所以调用时会进入对于分支,执行如下逻辑:
int virtualId = upStreamVertexID;
upStreamVertexID = virtualPartitionNodes.get(virtualId).f0;
if (partitioner == null) {
partitioner = virtualPartitionNodes.get(virtualId).f1;
}
addEdgeInternal(upStreamVertexID, downStreamVertexID, typeNumber, partitioner, outputNames, outputTag);这里会将upStreamVertexID更新为2,并将keyBy对应的分区器设置给partitioner变量,然后递归调用addEdgeInternal方法后,会走到else逻辑中,这段逻辑前面已经介绍,这里就不赘述了。
这样就在flatMap和reduce对应的StreamNode之间构建了一个StreamEdge,且该StreamEdge中包含了keyBy转换中设置的分区器。
3、sink对应StreamTransformation子类实例的转化
sink操作对应的SinkTransformation对象,其input属性指向的是reduce转化的OneInputTransformation对象,根据递归转化输入的逻辑,reduce已经转化过,所以这里会进行sink自身的转化。
private Collection transformSink(SinkTransformation sink) {
/** 递归转化输入 */
Collection inputIds = transform(sink.getInput());
/** 决定槽共享分组名 */
String slotSharingGroup = determineSlotSharingGroup(sink.getSlotSharingGroup(), inputIds);
/** 添加sink */
streamGraph.addSink(sink.getId(),
slotSharingGroup,
sink.getOperator(),
sink.getInput().getOutputType(),
null,
"Sink: " + sink.getName());
/** 属性设置 */
streamGraph.setParallelism(sink.getId(), sink.getParallelism());
streamGraph.setMaxParallelism(sink.getId(), sink.getMaxParallelism());
/** 构建edge */
for (Integer inputId: inputIds) {
streamGraph.addEdge(inputId,
sink.getId(),
0
);
}
if (sink.getStateKeySelector() != null) {
TypeSerializer keySerializer = sink.getStateKeyType().createSerializer(env.getConfig());
streamGraph.setOneInputStateKey(sink.getId(), sink.getStateKeySelector(), keySerializer);
}
return Collections.emptyList();
} 逻辑与transformOneInputTransform方法的逻辑类似,不同的地方就是添加的是sink,会在StreamGraph的sinks这个属性中,加入sink节点的id,这里sink节点的id是5。
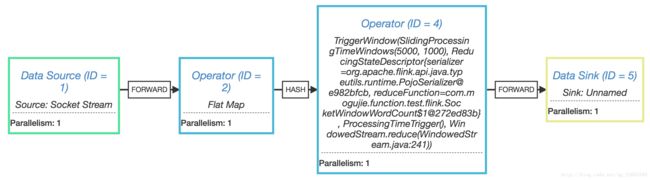
通过上述转化过程,就将对数据流的相关转换操作,都通过StreamGraph这个对象实例描述出来了。得到的StreamGraph实例的json字符串如下所示:
{"nodes":[{"id":1,"type":"Source: Socket Stream","pact":"Data Source","contents":"Source: Socket Stream","parallelism":1},{"id":2,"type":"Flat Map","pact":"Operator","contents":"Flat Map","parallelism":1,"predecessors":[{"id":1,"ship_strategy":"FORWARD","side":"second"}]},{"id":4,"type":"TriggerWindow(SlidingProcessingTimeWindows(5000, 1000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@e982bfcb, reduceFunction=com.mogujie.function.test.flink.SocketWindowWordCount$1@272ed83b}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241))","pact":"Operator","contents":"TriggerWindow(SlidingProcessingTimeWindows(5000, 1000), ReducingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.PojoSerializer@e982bfcb, reduceFunction=com.mogujie.function.test.flink.SocketWindowWordCount$1@272ed83b}, ProcessingTimeTrigger(), WindowedStream.reduce(WindowedStream.java:241))","parallelism":1,"predecessors":[{"id":2,"ship_strategy":"HASH","side":"second"}]},{"id":5,"type":"Sink: Unnamed","pact":"Data Sink","contents":"Sink: Unnamed","parallelism":1,"predecessors":[{"id":4,"ship_strategy":"FORWARD","side":"second"}]}]}将上述json字符串放如到 http://flink.apache.org/visualizer/ ,可以转化为图形表示,如下: