NLP系列——文本分类
目录
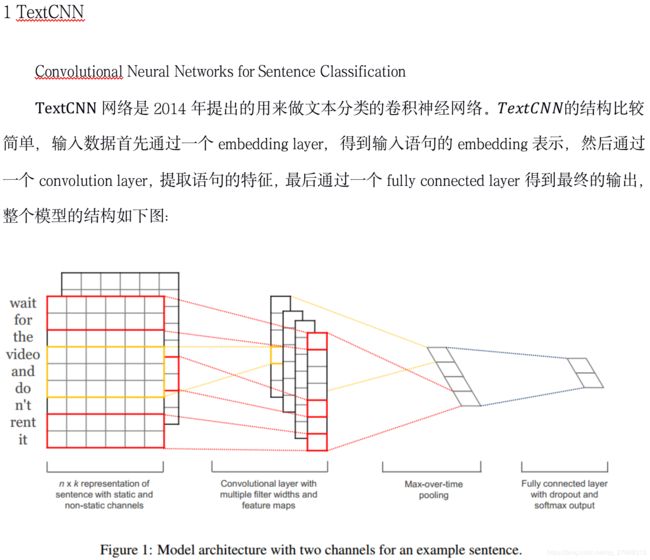
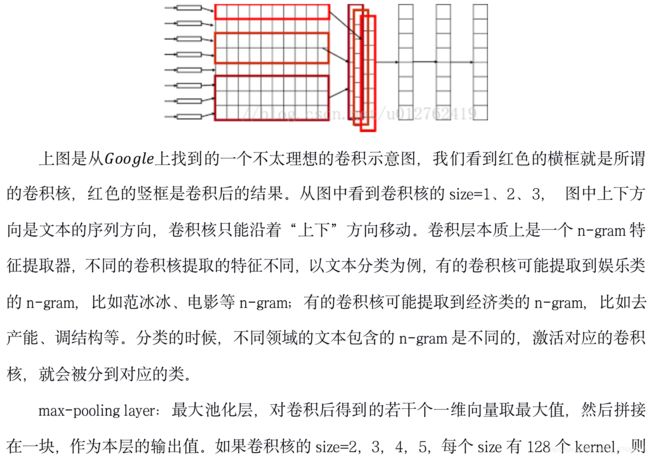
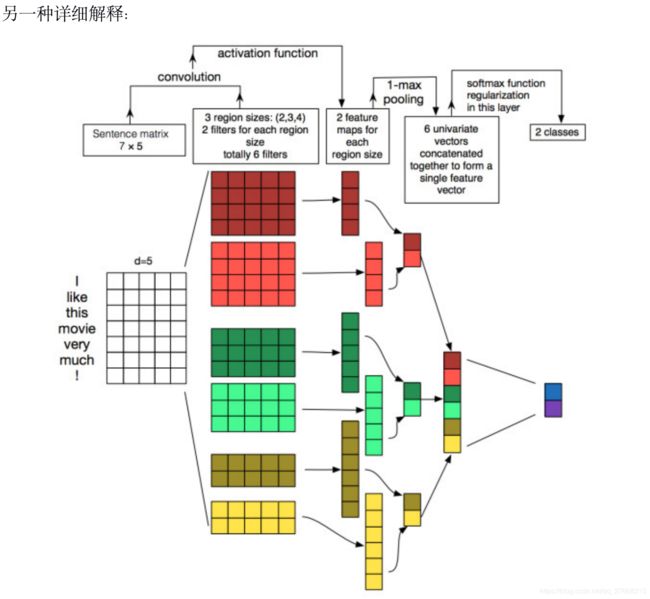
1. TextCNN
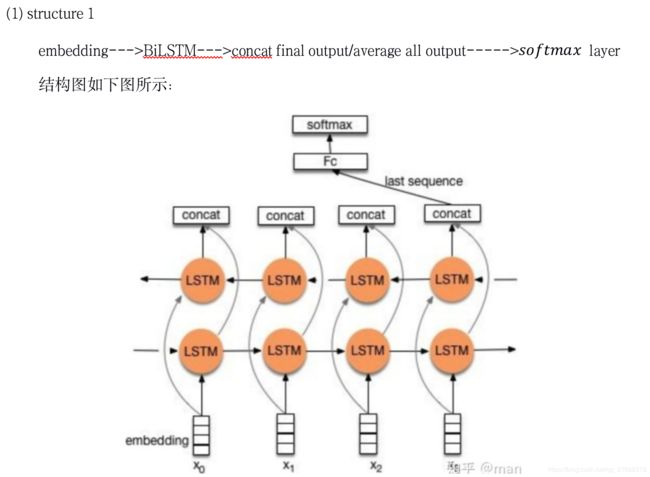
2. TextRNN
3. TextRNN + Attention
4. TextRCNN






Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3) # [128, 256, 31]
x = F.max_pool1d(x, x.size(2)).squeeze(2) # [128, 256]
return x
def forward(self, x):
out = self.embedding(x[0]) # [128, 32, 300], 32表示句子最大长度, x[0]是句子, x[1]是标签
out = out.unsqueeze(1) # [128, 1, 32, 300]
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1) # [128, 768], 768=3*256, 3表示卷积核数量
out = self.dropout(out)
out = self.fc(out) # [128, 10]
return out



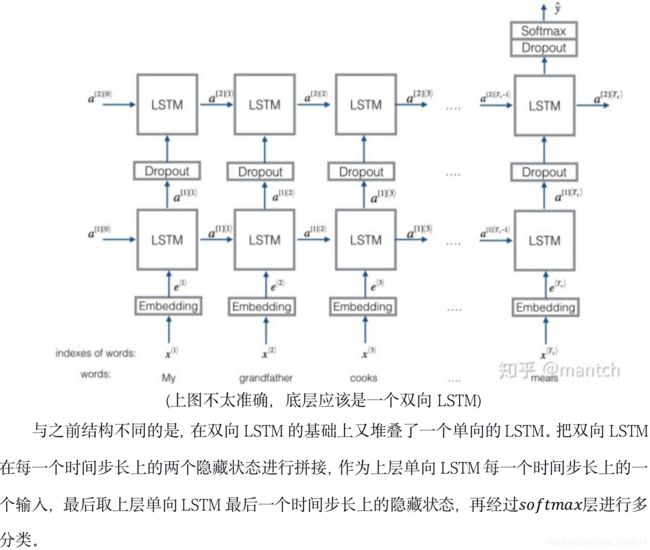
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
x, _ = x
out = self.embedding(x) # [batch_size, seq_len, embedding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的输出
return out

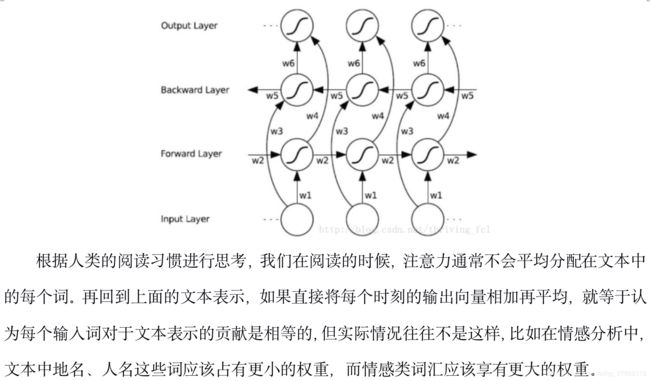

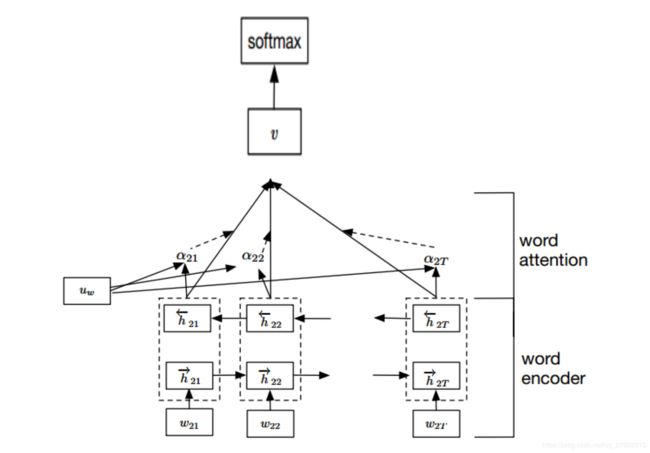

class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
self.w = nn.Parameter(torch.Tensor(config.hidden_size * 2))
self.tanh2 = nn.Tanh()
self.fc1 = nn.Linear(config.hidden_size * 2, config.hidden_size2)
self.fc = nn.Linear(config.hidden_size2, config.num_classes)
def forward(self, x):
x, _ = x
emb = self.embedding(x) # [batch_size, seq_len, embedding]=[128, 32, 300]
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size * num_direction]=[128, 32, 256]
M = self.tanh1(H) # [128, 32, 256]
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1) # [128, 32, 1]
out = H * alpha # [128, 32, 256]
out = torch.sum(out, 1) # [128, 256]
out = F.relu(out)
out = self.fc1(out)
out = self.fc(out) # [128, 64]
return out

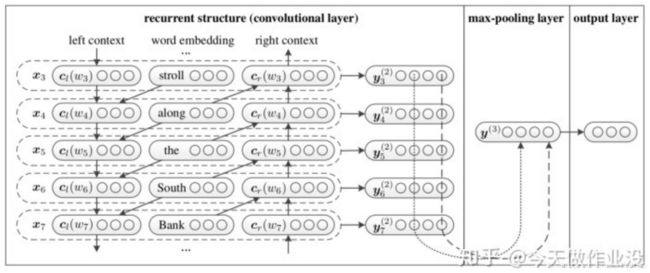

class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
x, _ = x
embed = self.embedding(x) # [batch_size, seq_len, embedding]
out, _ = self.lstm(embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).squeeze() # [batch_size, hidden_size*2 + embedding]
out = self.fc(out)
return out
上面代码中用的是双向RNN,论文中貌似是两个单向RNN