第二章 模型评估与选择--机器学习(周志华) 参考答案
机器学习(周志华) 参考答案 第二章 模型评估与选择
机器学习(周志华西瓜书) 参考答案 总目录
- http://blog.csdn.net/icefire_tyh/article/details/52064910
1.数据集包含1000个样本,其中500个正例,500个反例,将其划分为包含70%样本的训练集和30%样本的测试集用于留出法评估,试估算共有多少种划分方式。
一个组合问题,从 500 正反例中分别选出 150 正反例用于留出法评估,所以可能取法应该是 (C150500)2 种。
2.数据集包含100个样本,其中正反例各一半,假定学习算法所产生的模型是将新样本预测为训练样本数较多的类别(训练样本数相同时进行随机猜测),试给出用10折交叉验证法和留一法分别对错误率进行评估所得的结果。
10折交叉检验:由于每次训练样本中正反例数目一样,所以讲结果判断为正反例的概率也是一样的,所以错误率的期望是 50 %。
留一法:如果留下的是正例,训练样本中反例的数目比正例多一个,所以留出的样本会被判断是反例;同理,留出的是反例,则会被判断成正例,所以错误率是 100 %。
3.若学习器A的F1值比学习器B高,试析A的BEP值是否也比B高。
F1值的大小与BEP值并没有明确的关系。
两个分类器的 F1 值得大小与他们的BEP值大小并没有明确的关系(没去找)
这道题这里用反推,设计两个BEP值相同的分类器,如果他们的 F1 值不一样,那么这道题的结论就是否定的
再加点我看了评论后的疑惑:
BEP值就是 F1 值吗?
BEP值是在P=R时取到的,也就是BEP=P=R。如果在计算F时也要定义P=R,那么 F1 和 Fβ 将会恒等于BEP,那么P,R,F在这里有什么意义呢?
这里分两种情况:
第一就是我的理解,在计算F1时就是按照分类器真实的分类结果来计算P,R,再根据PR计算F1。当这个分类器正好P=R时,有P=R=BEP=F1。否则BEP的计算不能用当前的PR,而是通过一步一步尝试到查准率=查全率时,P’=R’=BEP。
第二种就是不存在我下面假设的分类器,分类器始终会在P=R的位置进行截断(截断指的是分类器将所有样本按分为正例的可能性排序后,选择某个位置。这个位置前面分类为正,后面分类为负)。但是这个可能吗?这种情况下 F1=Fβ=BEP 恒成立,分类器的评价本质将会变成了样本的正例可能性排序,而不是最终的样本划分结果。
分类器将所有训练样本按自己认为是正例的概率排序,排在越前面分类器更可能将它判断为正例。按顺序逐个把样本标记为正,当查准率与查全率相等时, BEP =查准率=查全率。当然分类器的真实输出是在这个序列中的选择一个位置,前面的标记为正,后面的标记为负,这时的查准率与查全率用来计算 F1 值。可以看出有同样的BEP值的两个分类器在不同位置截断可能有不同的 F1 值,所以 F1 值高不一定 BEP 值也高。
比如:
| 1/+ | 2/+ | 3/+ | 4/+ | 5/+ | 6/- | 7/- | 8/- | 9/- | 10/- |
|---|---|---|---|---|---|---|---|---|---|
| 1/+ | 2/+ | 3/+ | 4/+ | 6/- | 5/- | 7/- | 8/- | 9/- | 10/- |
| 1/+ | 2/+ | 3/+ | 4/+ | 6/+ | 5/- | 7/- | 8/- | 9/- | 10/- |
第一行是真实的测试样本编号与分类,第二三行是两个分类器对所有样本按为正例可能性的排序,以及判断的结果。显然两个分类器有相同的BEP值,但是他们的 F1 值一个是 0.89 ,一个是 0.8 。
4.试述真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)之间的联系。
查全率: 真实正例被预测为正例的比例
真正例率: 真实正例被预测为正例的比例
显然查全率与真正例率是相等的。
查准率:预测为正例的实例中真实正例的比例
假正例率: 真实反例被预测为正例的比例
两者并没有直接的数值关系。
5.试证明(2.22) AUC=1−lrank
从书 34 页b图看来, AUC 的公式不应该写的这么复杂,后来才发现原来这个图并没有正例反例预测值相等的情况。当出现这种情况时, ROC 曲线会呈斜线上升,而不是这种只有水平和垂直两种情况。
由于一开始做题时并没有想过ROC曲线不可以是斜线,所以画了这张图,如果不存在正例反例预测值相等的情况,那么斜线也没必要存在。
但是在维基百科上看到一副图,貌似也存在斜线的ROC,但是不知道含义是否和我这里写的一样。
https://en.wikipedia.org/wiki/Receiver_operating_characteristic
引用一幅有斜线的ROC曲线
与 BEP 一样,学习器先将所有测试样本按预测概率排序,越可能是正的排在越前面。然后依次遍历,每扫描到一个位置,里面如果只有正例,则 ROC 曲线垂直向上,如果只有反例,曲线水平往右,如果既有正例也有反例,则斜向上。如图所示
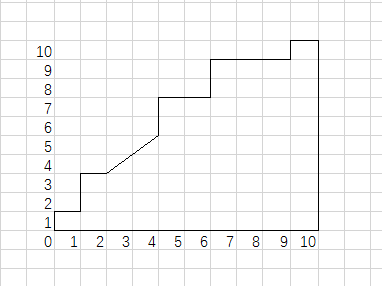
由于 TPR 与 FPR 的分母是常数,所以这里按比例扩大了坐标(分别是真实正例和真实反例的数目倍),可以更好看出曲线走势。
可以看出一共有 20 个测试样本, 10 个正, 10 个反。学习器排序的结果是
+,−,(+,+),(+,−),(+,−),(+,+),(−,−),(+,+),(−,−,−),+,− 。其中括号内的样本排在相同的位置。
< (+,+,−,−)与(+,−),(+,−) 是同样的效果>
公式 2.21 累加了所有不在正例的反例数目,其中同样的位置标记为 0.5 ,在正例前面标记为 1 。从图中可以看出,折线每次向右(右上)延伸,表示扫描到了反例,折线上方对应的面积,就是该反例后面有多少个正例,每个正例是一个正方形,对应的面积是 1 。同位置上的正例是个三角形,对应的面积是 0.5 。计算出总面积后,由于 ROC 图的坐标是归一化的,所以总面积要除以一开始放大的倍数,也就是 m+m− 。
6.试述错误率与ROC曲线之间的关系
ROC 曲线每个点对应了一个 TPR 与 FPR ,此时对应了一个错误率。
Ecost=(m+∗(1−TPR)∗cost01+m−∗FPR∗cost10)/(m++m−)
学习器会选择错误率最小的位置作为截断点。
7.试证明任意一条ROC曲线都有一条代价曲线与之对应,反之亦然。
由定义可以知道 TPR 与 FPR 都是由 0 上升到 1 ,那么 FNR 则是由 1 下降到 0 。
每条 ROC 曲线都会对应一条代价曲线,由于第一条代价线段的是 (0,0),(1,1) ,最后是 (0,1)(1,0) ,
所有代价线段总会有一块公共区域,这个区域就是期望总体代价,而这块区域的边界就是代价曲线,且肯定从 (0,0) 到 (1,0) 。
在有限个样本情况下, ROC 是一条折线,此时根据代价曲线无法还原 ROC 曲线。但若是理论上有无限个样本, ROC 是一条连续的折线,代价曲线也是连续的折线,每个点的切线可以求出 TPR 与 FNR ,从而得到唯一的 ROC 曲线。
8.Min-Max规范化与z-score规范化如下所示。试析二者的优缺点。
Min−max 规范化方法简单,而且保证规范化后所有元素都是正的,每当有新的元素进来,只有在该元素大于最大值或者小于最小值时才要重新计算全部元素。但是若存在一个极大(小)的元素,会导致其他元素变的非常小(大)。
z−score 标准化对个别极端元素不敏感,且把所有元素分布在 0 的周围,一般情况下元素越多, 0 周围区间会分布大部分的元素,每当有新的元素进来,都要重新计算方差与均值。
9.试述卡方检验过程。
略(……)
10.试述在使用 Friedman 检验中使用式(2.34)与(2.35)的区别
书上说 Friedman 检验,在 Nk 比较大时,平均序值 ri 近似于正态分布,均值为 k+12 ,
方差为 k2−112 (其实我觉得 ri 的方差是 k2−112N )。
即: ri ~ N(k+12,k2−112)
所以 12Nk2−1(ri−k+12)2 ~ χ2(1)
统计量 12Nk2−1∑k(ri−k+12)2 由于 k 个算法的平均序值 ri 是有关联的,知道其中 k−1 个就能推出最后一个,所以自由度为 k−1 ,在前面乘上 k−1k ,最终得到 Friedman 统计量为
fri=k−1k∗12Nk2−1∑k(ri−k+12)2
猜测:由于 Friedman 统计量只考虑了不同算法间的影响,而没去考虑不同数据集(其他方差)所带来的影响,所以书上说这个Friedman统计量太保守。
对序值表做方差分析:
总方差 SST=N∗(E(X2)−(EX)2)=N∗k∗(k2−1)/12 自由度 N∗(k−1)
算法间方差 SSA=N∗∑k(ri−k+12)2 自由度 k−1
其他方差 SSE=SST−SSA 自由度 (N−1)∗(k−1)
做统计量 f=SSA/(k−1)SSE/((N−1)∗(k−1))=(N−1)friN(k−1)−fri , f 服从 (k−1) 和 (N−1)∗(k−1) 的 F 分布