【大数据】——TDengine原理及使用
一、前言
应用背景:随着移动互联网的普及,数据通讯成本的急剧下降,以及各种低成本的传感技术和智 能设备的出现,除传统的手机、计算机在实时采集数据之外,从手环、共享自行车、 出租车、智能电表、环境监测设备到电梯、大型设备、工业生产线等都在源源不断的 产生海量的实时数据发往云端。这些海量数据是企业宝贵的财富,能够帮助企业实时 监控业务或设备的运行情况,生成各种维度的报表,而且通过大数据分析和机器学 习,对业务进行预测和预警,帮助企业进行科学决策、节约成本并创造新的价值。
仔细研究发现,所有机器、设备、传感器、以及交易系统所产生的数据都是时序的, 而且很多还带有位置信息。这些数据具有明显的特征,1: 数据是时序的,一定带有时 间戳;2:数据是结构化的;3: 数据极少有更新或删除操作;4:无需传统数据库的事 务处理;5:相对互联网应用,写多读少;6:用户关注的是一段时间的趋势,而不是 某一特点时间点的值;7: 数据是有保留期限的;8:数据的查询分析一定是基于时间 段和地理区域的;9:除存储查询外,还往往需要各种统计和实时计算操作;10:数 据量巨大,一天采集的数据就可以超过 100 亿条。 看似简单的事情,但由于数据记录条数巨大,导致数据的实时写入成为瓶颈,查询分 析极为缓慢,成为新的技术挑战。传统的关系型数据库或 NoSQL 数据库以及流式计 算引擎由于没有充分利用这些数据的特点,性能提升极为有限,只能依靠集群技术, 投入更多的计算资源和存储资源来处理,企业运营维护成本急剧上升。
TDengine 正是涛思数据面对这一高速增长的物联网大数据市场和技术挑战推出的创 新性的大数据处理产品,它不依赖任何第三方软件,也不是优化或包装了一个开源的 数据库或流式计算产品,而是在吸取众多传统关系型数据库、NoSQL 数据库、流式 计算引擎、消息队列等软件的优点之后自主开发的产品,在时序空间大数据处理上, 有着自己独到的优势。
- 10 倍以上的性能提升:定义了创新的数据存储结构,单核每秒就能处理至少 2 万次请求,插入数百万个数据点,读出一千万以上数据点,比现有通用数据库 快了十倍以上。
- 硬件或云服务成本降至 1/5:由于超强性能,计算资源不到通用大数据方案的 1/5;通过列式存储和先进的压缩算法,存储空间不到通用数据库的 1/10
- 全栈时序数据处理引擎:将数据库、消息队列、缓存、流式计算等功能融合一 起,应用无需再集Kafka/Redis/HBase/Spark/HDFS 等软件,大幅降低应 用开发和维护的复杂度成本。
- 强大的分析功能:无论是十年前还是一秒钟前的数据,指定时间范围即可查 询。数据可在时间轴上或多个设备上进行聚合。临时查询可通过 Shell, Python, R, Matlab 随时进行。
- 与第三方工具无缝连接:不用一行代码,即可与 Telegraf, Grafana, Matlab, R 集成。后续将支持 MQTT, OPC, Hadoop,Spark 等, BI 工具也将无缝连接。
- 零运维成本、零学习成本:安装、集群一秒搞定,无需分库分表,实时备份。 标准 SQL,支持 JDBC, RESTful, 支持 Python/Java/C/C++/Go, 与 MySQL 相似,零学习成本。
二、存储结构
为提高压缩和查询效率,TDengine 采用列式存储。基于时序数据特点,与众多的时 序数据库不一样的是,TDengine 将每一个采集点的数据作为数据库中的一张独立的 表来存储。这样对于一个采集点的数据而言,无论在内存还是硬盘上,数据点在介质 TDengine 上是连续存放的,这样大幅减少随机读取操作,减少 IO 操作次数,数量级的提升读 取和查询效率。而且由于不同数据采集设备产生数据的过程完全独立,每个设备只产 生属于自己的数据,一张表也就只有一个写入者。这样每个表就可以采用无锁方式来 写,写入速度就能大幅提升。同时,对于一个数据采集点而言,其产生的数据是时序 的,因此写的操作可用追加的方式实现,进一步大幅提高数据写入速度。

数据具体写如流程如图所示:

写入数据时,先将数据点写进 Commit 日志,然后转发给同一虚拟节点组里的其他节 点,再按列写入分配的内存块。当内存块的剩余空间达到一定临界值或设定的commit 时间时, 内存块的数据将写入硬盘。内存块是固定大小(如 16K)的, 但依据系 统内存的大小,每个采集点可以分配一个到多个内存块,采取 LRU 策略进行管理。 在一个内存块里,数据是连续存放的,但块与块是不连续的,因此 TDengine 为每一 个表在内存里建立有块的索引,以方便写入和查询。 数据写入硬盘是以添加日志的方式进行的,以大幅提高落盘的速度。为避免合并操 作,每个采集点(表)的数据也是按块存储,在一个块内,数据点是按列连续存放 的,但块与块之间可以不是连续的。 TDengine 对每张表会维护一索引,保存每个数 据块在文件中的偏移量,起始时间、数据点数、压缩算法等信息。每个数据文件仅仅 保存固定一段时间的数据(比如一周,可以配置),因此一个表的数据会分布在多个数 据文件中。查询时,根据给定的时间段,TDengine 将计算出查找的数据会在哪个数 据文件,然后读取。这样大幅减少了硬盘操作次数。多个数据文件的设计还有利于数 据同步、数据恢复、数据自动删除操作,更有利于数据按照新旧程度在不同物理介质 上存储,比如最新的数据存放在 SSD 盘上,最老的数据存放在大容量但慢速的硬盘 上。通过这样的设计,TDengine 将硬盘的随机读取几乎降为零,从而大幅提升写入 和查询效率,让 TDengine 在很廉价的存储设备上也有超强的性能。 为减少文件个数,一个虚拟节点内的所有表在同一时间段的数据都是存储在同一个数 据文件里,而不是一张表一个数据文件。但是对于一个数据节点,每个虚拟节点都会 有自己独立的数据文件。
三、编译
1、To build TDengine, use CMake 2.8 or higher versions in the project directory. Install CMake for example on Ubuntu:
sudo apt-get install -y cmake build-essential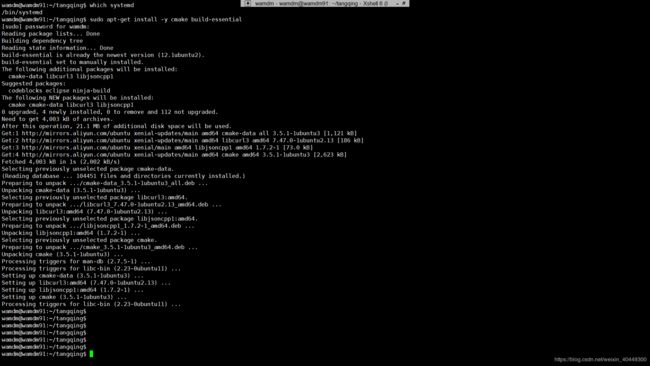
2、 To compile and package the JDBC driver source code, you should have a Java jdk-8 or higher and Apache Maven 2.7 or higher installed. To install openjdk-8 on Ubuntu:
sudo apt-get install openjdk-8-jdk3、To install Apache Maven on Ubuntu:
sudo apt-get install maven4、Build TDengine:
mkdir build && cd build
cmake .. && cmake --build .四、运行
1、To quickly start a TDengine server after building, run the command below in terminal:(服务端)
./build/bin/taosd -c test/cfg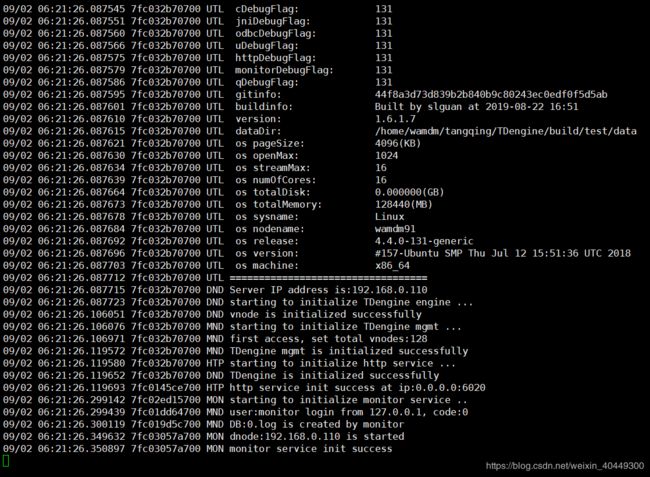
2、In another terminal, use the TDengine shell to connect the server:(客户端)
./build/bin/taos -c test/cfg注:option "-c test/cfg" specifies the system configuration file directory.

五、安装
1、After building successfully, TDengine can be installed by:
make install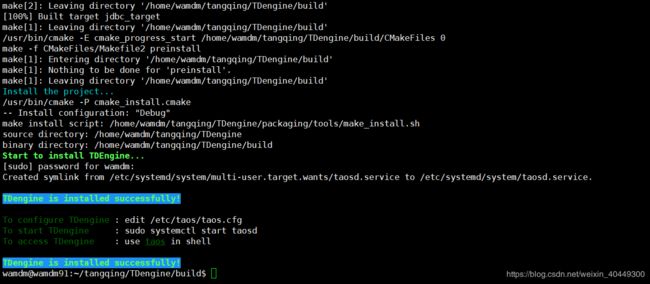
2、Users can find more information about directories installed on the system in the directory and files section. It should be noted that installing from source code does not configure service management for TDengine. Users can also choose to install from packages for it.
To start the service after installation, in a terminal, use:
taosd3、Then users can use the TDengine shell to connect the TDengine server. In a terminal, use:
taosIf TDengine shell connects the server successfully, welcome messages and version info are printed. Otherwise, an error message is shown.
六、使用
It is easy to run SQL commands from TDengine shell which is the same as other SQL databases.
create database db;
use db;
create table t (ts timestamp, a int);
insert into t values ('2019-07-15 00:00:00', 1);
insert into t values ('2019-07-15 01:00:00', 2);
select * from t;
drop database db;七、参考资料
1、github:https://github.com/taosdata/TDengine
2、推广文章:推广文章
3、官网:taosdata.com