Oracle关于执行计划的简要分析
一、如何打开执行计划:
打开执行计划(执行 set autotrace traceonly/off),如果提示SP2-0611,SP2-0618,按以下办法建立相应用户即可。
1、SYS用户登录,执行@$Oracle_HOME/rdbms/admin/utlxplan.sql,创建PLAN_TABLE ;
2、执行@$Oracle_HOME/sqlplus/admin/plustrce.sql,创建plustrace角色;
3、赋给用户grant plustrace to public;
执行 set autotrace traceonly即可。也可以采用以下方式:
1、explain plan for select * from student;
2、select * from table(DBMS_XPLAN.display);
二、执行计划的内容解析:
目前Oracle优化器采用的是基于cost的cbo方式来对sql进行优化,因此优化器的判断非常依赖于数据库对象的统计分析信息。只有提供给优化器正确的对象信息(DBMS_STAT),才能使得优化器做出正确的选择。
优化器选择的方式无怪乎本文以下几种方式,只要正确的理解执行计划中这些内容,就可以根据数据库对象的数据量和索引情况来改进sql的性能。
看执行计划时,首先Operation列是指当前操作的内容。从缩进最大的行看,它是最先被执行的步骤,对于两行缩进相同的行,最上面的最先被执行;ROW列,是Oracle估算当前行的返回结果集;COST和TIME是Oracle估算的成本和时间。
Oracle访问数据的存取方式有:
全表扫描(TABLE ACCESS FULL):对所有表中记录进行扫描。使用多块读操作,一次I/O能读取多块数据块。表字段不涉及索引时往往采用这种方式。较大的表不建议使用全表扫描,除非结果数据超出全表数据总量的10%;
通过ROWID的表存取(Table Access by ROWID):一次I/O只能读取一个数据块。通过rowid读取表字段,rowid可能是索引键值上的rowid;
索引扫描(Index Scan):索引扫描是首先扫描索引得到rowid值,该步骤的数据直接由内存读取,速度较快;然后通过rowid读出具体数据,如果表较大效率会下降。索引扫描有4种类型的索引扫描:
1、索引唯一扫描(index unique scan),如果表字段有UNIQUE 或PRIMARY KEY 约束,Oracle实现索引唯一扫描,这种扫描方式条件比较极端,出现比较少;
2、索引范围扫描(index range scan),这种是最常见的索引扫描方式。在非唯一索引上都使用索引范围扫描。
使用index rang scan的3种情况:
1 ) 在唯一索引列上使用了以下圈定范围的操作符(> < <> >= <= between等)
2 ) 在组合索引上,只使用部分列进行查询,导致查询出多行
3 ) 对非唯一索引列上进行的任何查询。
3、 索引全扫描(index full scan):这种情况下,是查询的数据都属于索引字段,一般都含有排序操作
4、索引快速扫描(index fast full scan):如果查询的数据都属于索引字段,并且没有进行排序操作,那么是属于这种情况。条件比较极端,出现比较少;
表之间的连接方式有
1、排序 - 合并连接(Sort Merge Join):该种排序限制较大,出现比较少;
内部连接过程:
1) 首先生成表1需要的数据,然后对这些数据按照连接操作关联列进行排序;
2) 随后生成表2需要的数据,然后对这些数据按照与表1对应的连接操作关联列进行排序;
3) 最后两边已排序的行被放在一起执行合并操作,即将2个表按照连接条件连接起来。
2、嵌套循环(Nested Loops)
该连接过程就是一个2层嵌套循环,所以外层循环的次数越少越好。如果driving row source(外部表)比较小,并且在inner row source(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。
3、哈希连接(Hash Join)
在2个较大的row source之间连接时会取得相对较好的效率,在一个row source较小时则能取得更好的效率。
三、统计数据的含义:
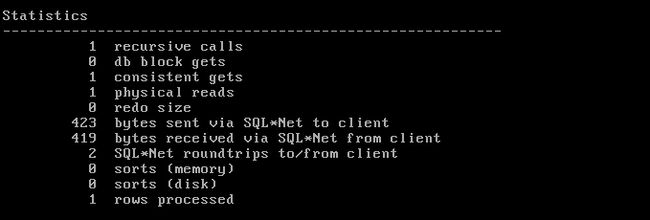
1. recursive calls 递归调用次数;
2. db block gets 当期操作时从内存读取的当前最新块数据,并不是在一致性读的情况的块数,即通过update/delete/select for update读的块数;
3. consistent gets 当期操作时在一致性读状态下读取的块数,即通过不带for update的select 读的块数;
4. physical reads 物理读,Oracle从磁盘读的数据块数量 其产生的主要原因是:在数据库高速缓存中不存在这些块;全表扫描;磁盘排序。其中逻辑读指的是Oracle从内存读到的数据块数量。一般来说是'consistent gets' + 'db block gets'。当在内存中找不到所需的数据块的话就需要从磁盘中获取,于是就产生了'phsical reads'。
5. redo size 执行SQL的过程中产生的重做日志;
6. 423 bytes sent via SQL*Net to client 通过网络发送给客户端的数据
7. 419 bytes received via SQL*Net from client 通过网络从客户端接收到的数据
8. SQL*Net roundtrips to/from client
9. sorts (memory) 在内存中发生的排序;
10. sorts (disk) 在硬盘中发生的排序;
11. rows processed
--------------------------------------分割线 --------------------------------------
在CentOS 6.4下安装Oracle 11gR2(x64) http://www.linuxidc.com/Linux/2014-02/97374.htm
Oracle 11gR2 在VMWare虚拟机中安装步骤 http://www.linuxidc.com/Linux/2013-09/89579p2.htm
Debian 下 安装 Oracle 11g XE R2 http://www.linuxidc.com/Linux/2014-03/98881.htm
--------------------------------------分割线 --------------------------------------
更多Oracle相关信息见Oracle 专题页面 http://www.linuxidc.com/topicnews.aspx?tid=12