tf.keras入门学习简述
文章目录
- 创建一个简单的网络模型
- Sequential model
- 配置网络层
- 训练和评估模型
- 配置训练
- 训练numpy格式数据
- 训练从 tf.data dataset 来的数据
- 评估和预测
- 构建复杂模型
- 从Model派生出个人模型
- 自定义层
- Callbacks
- 保存和恢复模型
- 仅保存模型权重值
- 仅保存模型的结构配置
- 保存整个模型到一个文件中
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
tf.keras.backend.clear_session() # 清除原有的TF图和会话,重新开始
创建一个简单的网络模型
Sequential model
可以通过将layers叠加在一起来构建模型,创建一个连续普通的神经网络使用函数 tf.keras.Sequential
接下来,构建全连接神经网络
model = tf.keras.Sequential()
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10)) # 输出单元为10
配置网络层
网络中可以配置的参数主要:
- activation激活函数(值来源
tf.nn)
例如:tf.nn.sigmoid、tf.nn.tanh、tf.nn.relu - kernel_initializer参数W初始化,默认初始化为
Glorot uniform,即称作Xavier正态分布初始化。(值来源tf.keras.initializers) - bias_initializer参数b初始化,默认初始化为全0。(值来源
tf.keras.initializers) - kernel_regularizer参数正则化(值来源
tf.keras.regularizers)
例如:tf.keras.regularizers.l2
以下举例:
# 创建一个激活函数为relu的网络层
layers.Dense(64, activation='relu')
# 或者,等同于
activation = tf.nn.relu
layers.Dense(64, activation=activation)
# 将l2正则化用于参数W
regularizer = tf.keras.regularizers.l2
layers.Dense(64, kernel_regularizer = regularizer)
# 将参数b初始化为全2
initializer = tf.keras.initializers.Constant(2.0)
layers.Dense(64, bias_initializer = initializer)
使用keras的functional API 是一种比tf.keras.SequentialAPI创建模型更灵活的方法。functional API可以处理具有非线性拓扑结构的模型、具有共享层的模型以及具有多个输入或输出的模型。
举例,若构建如下要求的模型
(input: 784-dimensional vectors)
↧
[Dense (64 units, relu activation)]
↧
[Dense (64 units, relu activation)]
↧
[Dense (10 units, softmax activation)]
↧
(output: logits of a probability distribution over 10 classes)
这是一个三层网络模型,现在利用functional API来构建模型,首先从构建输入层开始
# 如果你的输入特征有784个
inputs = keras.layers.Input(shape=(784, ))
inputs.shape, inputs.dtype
输出
(TensorShape([None, 784]), tf.float32)
你可以通过如下方式在输出层后添加新的一层
# 在输入层后添加新的一层
dense = layers.Dense(64, activation='relu')
x = dense(inputs)
# 再继续添加新层
x = layers.Dense(64, activation='relu')(x)
outputs = layers.Dense(10, name='OutputLayer')(x)
现在可以构建了一个具备输入层和输出层的网络模型
model = keras.Model(inputs=inputs, outputs=outputs, name='test_model')
现在来查看网络的模型构建情况
model.summary()
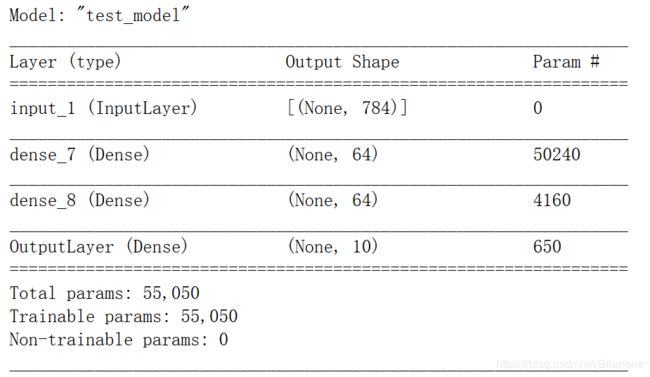 同时,也可以输出模型的图,倘若提示无法import pydot,则求助于链接:
同时,也可以输出模型的图,倘若提示无法import pydot,则求助于链接:
pydot安装教程
keras.utils.plot_model(model, 'test_model.jpg')
 你可以选择输出带维度的模型图
你可以选择输出带维度的模型图
keras.utils.plot_model(model,'test_model_with_shape.jpg',show_shapes=True)

训练和评估模型
配置训练
当构建好网络结构后,应该进行训练模型的配置,使用模型的compile方法
tf.keras.Model.compile方法的主要参数:
- optimizer(值来源
tf.keras.optimizers。例如tf.keras.optimizers.Adam,tf.keras.optimizers.RMSprop - loss(值来源
tf.keras.losses)例如tf.keras.losses.binary_crossentropy,
tf.keras.losses.CategoricalCrossentropy,tf.keras.losses.mean_squared_error - metrics(值来源
tf.keras.metrics)例如tf.keras.metrics.Accuracy,tf.keras.metrics.mae - 额外的参数
run_eagerly,令其为True可以使得模型训练和评估立即执行求值
注意其中提到的logits:指的是神经网络的输出,此输出还未经过最后一层网络的激活函数处理,即最后一层网络中激活函数的输入,而如上层定义,我们并未在最后一层定义激活函数,因此网络层输出的结果为logits
# 构建一个简单网络模型
model = tf.keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(32,)),
layers.Dense(64, activation='relu'),
layers.Dense(10)])
# 设置模型训练的配置
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
通过不同配置满足不同的模型要求
# 配置一个均方误差的回归模型
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss='mse',# 使用tf.keras.losses.mean_squared_error
metrics=['mae'] # 使用tf.keras.metrics.mean_absolute_error
)
# 配置一个多标签分类模型
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.01),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']) # 使用tf.keras.metrics.Accuracy
训练numpy格式数据
对于小规模的数据,可以将训练数据直接传入到numpy中,利用模型的fit方法进行模型训练
import numpy as np
# 训练集数据
train_data = np.random.random((1000, 32))
train_labels = np.random.random((1000, 10))
# 验证集数据
val_data = np.random.random((100,32))
val_labels = np.random.random((100,10))
tf.keras.Model.fit方法的主要参数:
- epochs在数据集大小为batch_size上的迭代次数
- batch_size将整个数据集按照batch_size大小划分开,每次训练以batch_size大小数据集为输入,注意划分后最后一批数据大小小于等于batch_size
- validation_data输入验证数据集,以元组的形式输入(特征值,标签值),将会在每轮迭代中输出模型在验证集上的评估效果
model.fit(train_data, train_labels,
validation_data=(val_data, val_labels),
epochs=10, batch_size=32)
训练从 tf.data dataset 来的数据
使用Dataset API可以扩展到大型数据集和多设备训练,通过tf.data.Dataset实例去使用fit方法
# 初始化一个dataset实例
dataset = tf.data.Dataset.from_tensor_slices((train_data, train_labels))
dataset = dataset.batch(32) # 将数据集分批
len(list(dataset.as_numpy_iterator()))
# 因为dataset已经被分批处理,所以fit中不需要使用参数batch_size
model.fit(dataset, epochs=10)
dataset也可以用于验证集数据
val_dataset = tf.data.Dataset.from_tensor_slices((val_data, val_labels))
val_dataset = val_dataset.batch(32)
model.fit(dataset, epochs=10,
validation_data=val_dataset)
评估和预测
tf.keras.Model.evaluate和tf.keras.Model.predit方法使用numpy数据和tf.data.Dataset数据
# 用于numpy数据
data = np.random.random((1000, 32))
labels = np.random.random((1000, 10))
model.evaluate(data, labels, batch_size=32)
# 用于dataset数据
dataset = tf.data.Dataset.from_tensor_slices((data, labels))
dataset = dataset.batch(32)
model.evaluate(dataset)
接下来演示如何预测数据
result = model.predict(data, batch_size=32)
print(result.shape)
构建复杂模型
从Model派生出个人模型
构建自己的模型类,继承于tf.keras.Model,可以自定义前向传播。在类的__init__方法中定义层,并可以在call方法中定义前向传播
举例:简单的个人模型定义并运行
class MyModel(tf.keras.Model):
def __init__(self, num_classes):
super(MyModel, self).__init__(name='my_model')
self.num_classes = num_classes
# 定义层
self.dense_1 = layers.Dense(32, activation='relu')
self.dense_2 = layers.Dense(num_classes)
def call(self, inputs):
# 定义前向传播,使用在__init__中定义的层
x = self.dense_1(inputs)
return self.dense_2(x)
model = MyModel(num_classes=10)
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(data, labels, batch_size=32, epochs=5)
自定义层
要想创建自定义层,需要继承于tf.keras.layers.Layer并且执行如下方法:
__init__:可选择性地定义需要的Layer中的层build:创建层中的权重,使用add_weight方法添加权重call:定义该层前向传播- 可选地,可以通过实现
get_config方法和from_config方法来序列化层。
class MyLayer(layers.Layer):
def __init__(self, output_dim, **kwargs):
self.output_dim = output_dim
super(MyLayer, self).__init__(**kwargs)
def build(self, input_shape):
self.kernel = self.add_weight(
name='kernel',
shape=(input_shape[1], self.output_dim),
initializer='uniform',
trainable=True)
def call(self, inputs):
return tf.matmul(inputs, self.kernel)
def get_config(self):
base_config = super(MyLayer, self).get_config()
base_config['output_dim'] = self.output_dim
return base_config
@classmethod
def from_config(cls, config):
return cls(**config)
model = tf.keras.Sequential([MyLayer(10)])
model.compile(optimizer=tf.keras.optimizers.RMSprop(0.001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(data, labels, batch_size=32, epochs=5)
Callbacks
Callbacks是传递给模型的一个对象,可以扩展模型在训练时的行为。可以自定义callback,或者使用在tf.keras.callbacks中已经定义的callback
tf.keras.callbacks.ModelCheckpoint:定期保存模型的checkpointstf.keras.callbacks.LearningRateScheduler:动态地改变学习率,可以用于学习率衰减tf.keras.callbacks.EarlyStopping:当测试集评估表现没有得到提高时停止训练tf.keras.callbacks.TensorBoard:使用TensorBoard监控模型的行为
# 使用EarlyStopping和TensorBoard
callbacks = [
# 倘若'val_loss'在两个训练迭代都没得到改善则停止训练
tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'),
# 将TensorBoard日志写入 `./logs` 目录中
tf.keras.callbacks.TensorBoard(log_dir='./logs')
]
model.fit(data, labels, batch_size=32, epochs=5, callbacks=callbacks,
validation_data=(val_data, val_labels))
保存和恢复模型
仅保存模型权重值
tf.keras.Model.save_weights:保存权重tf.keras.Model.load_weights:恢复权重
model = tf.keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(32,)),
layers.Dense(10)])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 保存权重到TensorFlow Checkpoint文件
model.save_weights('./weights/my_model')
# 恢复权重到模型
model.load_weights('./weights/my_model')
使用保存模型权重会默认为TensorFlow Checkpoint文件格式,权重也可以选择保存为HDF5格式
# 保存权重为HDF5文件
model.save_weights('my_model.h5', save_format='h5')
# 加载权重到模型
model.load_weights('my_model.h5')
仅保存模型的结构配置
keras支持JSON和YAML序列化格式
# 将模型序列化为JSON格式
json_string = model.to_json()
json_string
import json
import pprint
pprint.pprint(json.loads(json_string))
从JSON中重建模型
fresh_model = tf.keras.models.model_from_json(json_string)
保存整个模型到一个文件中
被保存的整个模型包括权值值,模型的配置,甚至是优化的配置。这允许你checkpoints一个模型并在稍后从相同的状态恢复模型,并不需要再从头开始
# 建立一个简单模型
model = tf.keras.Sequential([
layers.Dense(10, activation='relu', input_shape=(32,)),
layers.Dense(10)
])
model.compile(optimizer='rmsprop',
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(data, labels, batch_size=32, epochs=5)
# 保存整个模型到HDF5格式文件中
model.save('my_model')
# 恢复保存的模型,权值和优化器等配置都相同
model = tf.keras.models.load_model('my_model')