[课程复习] 数据结构之经典题目回顾 (一)选择题、填空题1
作者最近在复习考博,乘此机会分享一些计算机科学与技术、软件工程等相关专业课程考题,一方面分享给考研、考博、找工作的博友,另一方面也是自己今后完成这些课程的复习资料,同时也是在线笔记。基础知识,希望对您有所帮助,不喜勿喷~
文章目录
- 一.基础、栈和队列
- 二.数组和广义表
- 三.树和二叉树
- 四.图
- 五.查找
- 六.排序
一.基础、栈和队列
1、栈和队列的共同特点是: 只允许在端点出插入和删除元素 。
2、用链接方式存储的队列,在进行插入运算时( D )。
- A. 仅修改头指针
- B. 头、尾指针都要修改
- C. 仅修改尾指针
- D.头、尾指针可能都要修改
3、通常从四个方面评价算法的质量:(可读性)、(正确性)、(健壮性)和(高效性)。
4、设顺序循环队列Q[0:M-1]的头指针和尾指针分别为F和R,头指针F总是指向队头元素的前一位置,尾指针R总是指向队尾元素的当前位置,则该循环队列中的元素个数为:(R-F+M)%M。
5、下面程序段的功能实现数据x进栈,要求在下划线处填上正确的语句。
typedef struct {int s[100]; int top;} sqstack;
void push(sqstack &stack,int x)
{
if (stack.top==m-1) printf(“overflow”);
else {____________________; _________________;}
}
答案:stack.top++,stack.s[stack.top]=x
6、中序遍历二叉排序树所得到的序列是___________序列(填有序或无序)。
解析:二叉排序树的性质: 按中序遍历二叉排序树,所得到的中序遍历序列是一个递增有序序列。
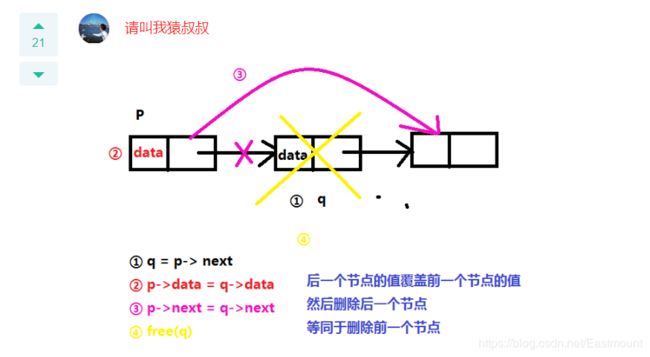
7、设指针变量p指向单链表中结点A,若删除单链表中结点A,则需要修改指针的操作序列为( )。
A.q=p->next;p->data=q->data;p->next=q->next;free(q);
B.q=p->next;q->data=p->data;p->next=q->next;free(q);
C.q=p->next;p->next=q->next;free(q);
D.q=p->next;p->data=q->data;free(q);
解析:此题参考 牛客网 下面这位大神的回答,答案选A,此题不是很好,删除过程通常是不需要赋值data的。
8、数据的物理结构主要包括_____________和______________两种情况。
答案:顺序存储结构、链式存储结构
9、设输入序列为1、2、3,则经过栈的作用后可以得到___________种不同的输出序列。
解析:
卡特兰数,C=(2n)!/(n+1)!n!=6!/4!3!=65/32=5
321、123、132、213、231,答案为5种。
10、不论是顺序存储结构的栈还是链式存储结构的栈,其入栈和出栈操作的时间复杂度均为____________。
答案:O(1)
11、设用链表作为栈的存储结构则退栈操作 ( )。
答案:必须判别栈是否为空
12、设指针变量p指向双向循环链表中的结点X,则删除结点X需要执行的语句序列为_____________________(设结点中的两个指针域分别为llink和rlink)。
答案:p>llink->rlink=p->rlink; p->rlink->llink=p->rlink
13、设有一个顺序循环队列中有M个存储单元,则该循环队列中最多能够存储________个队列元素;当前实际存储________________个队列元素(设头指针F指向当前队头元素的前一个位置,尾指针指向当前队尾元素的位置)。
答案:M-1,(R-F+M)%M
14、设顺序线性表中有n个数据元素,则第i个位置上插入一个数据元素需要移动表中_______个数据元素;删除第i个位置上的数据元素需要移动表中_______个元素。
答案:n+1-i,n-i。
建议画图举例解析
二.数组和广义表
1、设有一个二维数组A[m][n],假设A[0][0]存放位置在644(10),A[2][2]存放位置在676(10),每个元素占一个空间,问A[3][3]存放在什么位置?脚注(10)表示用10进制表示。
- A.688
- B.678
- C.692
- D.696
解析:
计算公式A[i][j]:A[0][0]+nj+i;
644 + 2 * n + 2 = 676,则计算出:n=15。A[3][3]=644+3*15+3=692。答案选C。
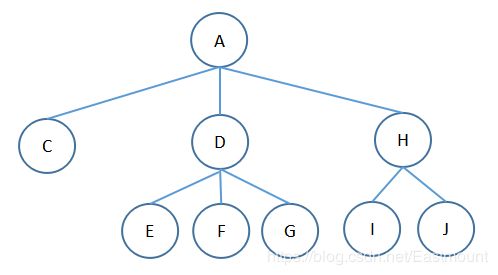
2、假定一棵树的广义表表示为A(C,D(E,F,G),H(I,J)),则树中所含的结点数为_________个,树的深度为___________,树的度为_________。
解析:
树的度为树内各节点的度的最大值,故答案为:9、3、3。
3、设一维数组中有n个数组元素,则读取第i个数组元素的平均时间复杂度为( )。
答案: O(1)
三.树和二叉树
1、二叉树的第k层的结点数最多为: 2k-1 。
2、后缀算式9 2 3 ± 10 2 / - 的值为__________。中缀算式(3+4X)-2Y/3对应的后缀算式为______________________。
答案:3, 4 X * + 2 Y * 3 / -
3、若用链表存储一棵二叉树时,每个结点除数据域外,还有指向左孩子和右孩子的两个指针。在这种存储结构中,n个结点的二叉树共有________个指针域,其中有________个指针域是存放了地址,有______个指针是空指针。
答案:2n n-1 n+1
4、向一棵B_树插入元素的过程中,若最终引起树根结点的分裂,则新树比原树的高度___________。
答案:增加1
5、设哈夫曼树中的叶子结点总数为m,若用二叉链表作为存储结构,则该哈夫曼树中总共有(2m )个空指针域。
解析:哈夫曼树中只有N0和N2节点,如果用二叉链表来存储,度为2的结点的左右孩子都存在,没有空指针,度为0的叶子没有孩子,因此左右孩子的链域都为空,因此该Huffman树一共有2m个空指针。
6、设某棵二叉树的中序遍历序列为ABCD,前序遍历序列为CABD,则后序遍历该二叉树得到序列为( )。
解析:通过中序遍历和前序遍历可以将树构建出来,再求其后序遍历结果。
前序遍历(先根排序),故C为根节点,再看中序遍历可知,AB为C的左子树,D为其右子树。AB - C - D
前序遍历第二个节点为A,则A为根节点,再看中序遍历B在A后面,则B为右子树,最终构建树如下图所示。
答案:后序遍历结果为 BADC。

7、设某棵二叉树中有2000个结点,则该二叉树的最小高度为( )。
解析:
满二叉树高度与节点个数关系是num=2n-1,则:210 < 2000 < 211。答案为:11
8、设某棵二叉树中度数为0的结点数为N0,度数为1的结点数为N1,则该二叉树中度数为2的结点数为_________;若采用二叉链表作为该二叉树的存储结构,则该二叉树中共有_______个空指针域。
答案:N0-1,2N0+N1
二叉树中N2+1=N0,其中空指针为二叉树N0节点2个,N1节点1个。
建议该种题型画图进行分析,如下所示:叶子节点4个,N2节点3个。

9、设某数据结构的二元组形式表示为A=(D,R),D={01,02,03,04,05,06,07,08,09},R={r},r={<01,02>,<01,03>,<01,04>,<02,05>,<02,06>,<03,07>,<03,08>,<03,09>},则数据结构A是(树型结构 )。
解析:画图即可展示。
10、设一棵完全二叉树中有500个结点,则该二叉树的深度为__________;若用二叉链表作为该完全二叉树的存储结构,则共有___________个空指针域。
答案:9、501
参考 牛客网 解析:

或者将二叉树中节点从1到500编号,最后一个节点500对应的最后一个双亲节点编号为500/2=250,故有250个叶子节点。又500的双亲节点右孩子节点应该为2*250+1=501,无右孩子节点,故右指针域为空,共501个空指针域。
11、设哈夫曼树中共有n个结点,则该哈夫曼树中有________个度数为1的结点。
答案:0
12、设有n个结点的完全二叉树,如果按照从自上到下、从左到右从1开始顺序编号,则第i个结点的双亲结点编号为____________,右孩子结点的编号为___________。
答案:i/2,2i+1
13、下列算法实现在二叉排序树上查找关键值k,请在下划线处填上正确的语句。
typedef struct node{int key; struct node *lchild; struct node *rchild;}bitree;
bitree *bstsearch(bitree *t, int k)
{
if (t==0 ) return(0);
else while (t!=0)
if (t->key==k) _____________;
else if (t->key>k) t=t->lchild;
else _____________;
}
答案:return(t),t=t->rchild
14、设一棵二叉树的深度为k,则该二叉树中最多有( )个结点。
答案:2k-1
15、在二叉排序树中插入一个结点的时间复杂度为( )。
答案:O(n)
最差情况下是O(n) 如果是最一般最基础的二叉树的话, 因为深度不平衡,所以会发展成单链的形状,就是一条线 n个点那么深,如果是深度平衡的二叉树 o(logn)。
16、根据初始关键字序列(19,22,01,38,10)建立的二叉排序树的高度为____________。
答案:3

17、深度为k的完全二叉树中最少有____________个结点,最多有__________个结点。
答案:2k-1,2k-1
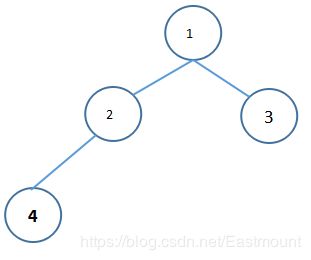
完全二叉树是一对一对应,和满二叉树有区别,满二叉树为最多结点,最少如下所示,仅4个结点。
18、设哈夫曼树中共有99个结点,则该树中有_________个叶子结点;若采用二叉链表作为存储结构,则该树中有_____个空指针域。
解析:
哈夫曼树没有N1节点,故:99=N0+N2,并且N0=N2+1,求得:N2=49,故叶子节点为50个;二空指针为叶子节点的左右孩子指针,共100个空指针。
答案:50,100
四.图
1、对于一个具有n个顶点和e条边的有向图和无向图,在其对应的邻接表中,所含边结点分别有_______个和________个。
答案:e,2e
2、AOV网是一种 有向无回路 的图。DAG图称为 有向无环图 。
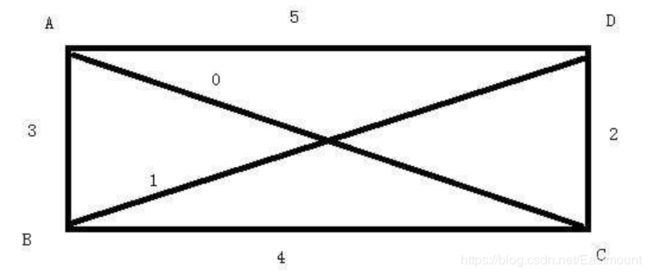
3、在一个具有n个顶点的无向完全图中,包含有________条边,在一个具有n个顶点的有向完全图中,包含有________条边。
解析:答案为:n(n-1)/2,n(n-1)。
例如,n=4,则有6个顶点。
4、设某有向图中有n个顶点,则该有向图对应的邻接表中有( )个表头结点。
答案:n
5、设某无向图中顶点数和边数分别为n和e,所有顶点的度数之和为d,则e=_______。
答案:d/2
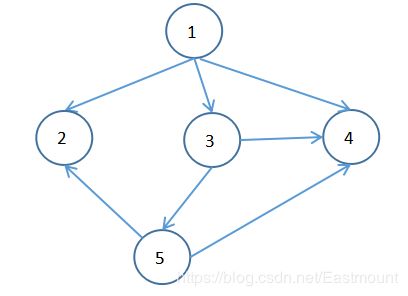
6、已知一有向图的邻接表存储结构如下:从顶点1出发,DFS遍历的输出序列是______________,BFS遍历的输出序列是_____________。

解析:
DFS是深度优先搜索,则从顶点1出发,搜索3,3继续搜索4,4邻接顶点为空,则返回上一层3搜索5,5继续搜索2,故输出:1->3->4->5->2
BFS是广度优先搜索,则顶点1出发,搜索3、2、4,接着搜索3的顶点5,故输出:1->3->2->4->5
答案:(1,3,4,5,2),(1,3,2,4,5)
注意下图需按照邻接表指针顺序遍历,1先遍历3,才到其他的。
7、设无向图G中有n个顶点e条边,则其对应的邻接表中的表头结点和表结点的个数分别为( )。
答案:n,2e

8、设某强连通图中有n个顶点,则该强连通图中至少有( n )条边。
解析:参考百度百科 oncforever大神 的答案。
有n个顶点的强连通图最多有n(n-1)条边,最少有n条边。
解释如下:
强连通图(Strongly Connected Graph)是指一个有向图(Directed Graph)中任意两点v1、v2间存在v1到v2的路径(path)及v2到v1的路径的图。
最多的情况:
即n个顶点中两两相连,若不计方向,n个点两两相连有n(n-1)/2条边,而由于强连通图是有向图,故每条边有两个方向,n(n-1)/2×2=n(n-1),故有n个顶点的强连通图最多有n(n-1)条边。
最少的情况:
即n个顶点围成一个圈,且圈上各边方向一致,即均为顺时针或者逆时针,此时有n条边。
举例:如下图ABCD四个点构成强连通图
边数最多有4×3=12条,边数最少有4条,图如下所示:


9、设有向图G用邻接矩阵A[n][n]作为存储结构,则该邻接矩阵中第i行上所有元素之和等于顶点i的________,第i列上所有元素之和等于顶点i的________。
答案:出度,入度
10、设有向图G中有n个顶点e条有向边,所有的顶点入度数之和为d,则e和d的关系为_________。
答案:e=d
11、设有向图G中有向边的集合E={<1,2>,<2,3>,<1,4>,<4,2>,<4,3>},则该图的一种拓扑序列为____________________。
答案:1->4->2->3

五.查找
1、若有18个元素的有序表存放在一维数组A[19]中,第一个元素放A[1]中,现进行二分查找,则查找A[3]的比较序列的下标依次为( )。
- A. 1,2,3
- B. 9,5,2,3
- C. 9,5,3
- D. 9,4,2,3
解析:
mid = |(low+high)/2|,向下取整,如9.5取9。
第一次:left = 1 right = 18 ,则:mid = 9 (向下取整)
第二次:left = 1 right = 8(mid-1),则:mid = 4 (向下取整)
第三次:left = 1 right = 3(mid-1),则:mid = 2
第四次:left = 3 (mid+1) right = 3 mid = 3。答案选D。
2、假定一个线性表为(12,23,74,55,63,40),若按Key % 4条件进行划分,使得同一余数的元素成为一个子表,则得到的四个子表分别为 (12 , 40 )、(23,55, 63)、(74)和( )。
解析:
余数为0:12%4=0, 40%4=0
余数为2:74%4=2
余数为3:23%4=3, 55%4=3, 63%4=3
3、设一组有序的记录关键字序列为(13,18,24,35,47,50,62,83,90),查找方法用二分查找,要求计算出查找关键字62时的比较次数并计算出查找成功时的平均查找长度。
解析:其计算过程如下图所示。
答案:2,ASL = (1 * 1 + 2 * 2 + 3 * 4 + 4 * 2) / 9 = 25/9。

4、设二叉排序树中有n个结点,则在二叉排序树的平均查找长度为( )。
答案:O(log2n)
5、设查找表中有100个元素,如果用二分法查找方法查找数据元素X,则最多需要比较________次就可以断定数据元素X是否在查找表中。
答案:7
解析:log2100=7,2的7次方为128。
6、下列算法实现在顺序散列表中查找值为k的关键字,请在下划线处填上正确的语句。
struct record{int key; int others;};
int hashsqsearch(struct record hashtable[ ],int k)
{
int i,j; j=i=k % p;
while (hashtable[j].key!=k&&hashtable[j].flag!=0){
j=(____) %m; if (i==j) return(-1);
}
if (_______________________ ) return(j); else return(-1);
}
答案:j+1,hashtable[j].key==k
由于返回 j 表示该下标的存储的值为k,故第二个空为 hashtable[j].key==k。
7、设有序顺序表中有n个数据元素,则利用二分查找法查找数据元素X的最多比较次数不超过( )。
A.log2n+1 B.log2n-1 C.log2n D.log2(n+1)
答案:A,折半查找为log2n+1(最后一个元素的比较)。
8、设散列函数H(k)=k mod p,解决冲突的方法为链地址法。要求在下列算法划线处填上正确的语句完成在散列表hashtalbe中查找关键字值等于k的结点,成功时返回指向关键字的指针,不成功时返回标志0。
typedef struct node {int key; struct node *next;} lklist;
void createlkhash(lklist *hashtable[ ])
{
int i,k; lklist *s;
for(i=0;i<m;i++) _____________________;
for(i=0;i<n;i++)
{
s=(lklist *)malloc(sizeof(lklist)); s->key=a[i];
k=a[i] % p; s->next=hashtable[k]; _______________________;
}
}
答案:hashtable[i]=0,hashtable[k]=s
六.排序
1、对n个记录的文件进行快速排序,所需要的辅助存储空间大致为:O(log2n)
解析:
辅助空间中快速排序为O(log2n),归并排序为O(n),基数排序为O(rd+n),其他排序为O(1)。
2、在堆排序的过程中,对任一分支结点进行筛运算的时间复杂度为________,整个堆排序过程的时间复杂度为________。
解析:
堆排序的时间复杂度为O(nlog2n),则每个分支的时间复杂度为O(log2n)。
答案:O(log2n),O(nlog2n)。
3、在快速排序、堆排序、归并排序中, 归并 排序是稳定的。
解析:
稳定排序:直接插入排序、冒泡排序、归并排序、基数排序
不稳定排序:希尔排序、直接选择排序、堆排序、快速排序
4、设一组初始记录关键字序列(5,2,6,3,8),以第一个记录关键字5为基准进行一趟快速排序的结果为( 3,2,5,6,8 )。
解析:
快速排序5为基准,基本规则如下:left=3,right=8,先遍历right,寻找比基准5小的数字左移;找到之后与左边left下标替换,接着left向右移动,寻找比基准5大的数字,找到之后替换,最后left=right时,该数字与基准替换。
初始:5 2 6 3 8,right寻找到3,与left=5交换位置
接着:3 2 6 () 8,left从左边移动,找到6,与()替换位置
接着:3 2 () 6 8,此时向左移动right,right=left,停止快速排序,并用()替换基准5。
输出:3 2 5 6 8,其为第一趟快速排序的结果。
5、为了能有效地应用HASH查找技术,必须解决的两个问题是____________和_________。
答案:构造一个好的HASH函数,确定解决冲突的方法。
6、快速排序的最坏时间复杂度为___________,平均时间复杂度为__________。
答案:O(n2),O(nlog2n)

7、设一组初始记录关键字序列为(55,63,44,38,75,80,31,56),则利用筛选法建立的初始堆为___________________________。
答案:(31,38,54,56,75,80,55,63)
8、设有n个待排序的记录关键字,则在堆排序中需要( 1 )个辅助记录单元。
9、设一组初始关键字记录关键字为(20,15,14,18,21,36,40,10),则以20为基准记录的一趟快速排序结束后的结果为( )。
A.10,15,14,18,20,36,40,21
B.10,15,14,18,20,40,36,21
C.10,15,14,20,18,40,36,2l
D.10,15,14,18,20,36,40,21
解析:快排如下
20,15,14,18,21,36,40,10 => 右边开始,找到小于20的10,交换次序
10, 15,14,18,21,36,40,() => 左边继续,找到大于20的21,交换次序
10,15,14,18,(),36,40,21 => 右边继续找小于20的数字,找到()处停止
10,15,14,18,20,36,40,21 => 输出第一趟快速排序结果,故选D。
10、设有5000个待排序的记录关键字,如果需要用最快的方法选出其中最小的10个记录关键字,则用下列( 堆排序 )方法可以达到此目的。
11、设一组初始记录关键字为(72,73,71,23,94,16,5),则以记录关键字72为基准的一趟快速排序结果为___________________________。
答案:(5,16,71,23,72,94,73)
该题方法和前面一样,请同学们自行尝试。
72 73 71 23 94 16 05
05 73 71 23 94 16 ( )
05 ( ) 71 23 94 16 73
05 16 71 23 94 ( ) 73
05 16 71 23 ( ) 94 73
05 16 71 23 72 94 73
12、设一组初始记录关键字序列为(345,253,674,924,627),则用基数排序需要进行( )趟的分配和回收才能使得初始关键字序列变成有序序列。
答案:3
个位、十位、百位共三趟。
13、设有n个无序的记录关键字,则直接插入排序的时间复杂度为________,快速排序的平均时间复杂度为_________。
答案:O(n2),O(nlog2n)
14、设初始记录关键字序列为(K1,K2,…,Kn),则用筛选法思想建堆必须从第______个元素开始进行筛选。
答案:n/2
15、设一组初始记录关键字序列为(20,18,22,16,30,19),则以20为中轴的一趟快速排序结果为______________________________。
答案:(19,18,16,20,30,22)
16、设一组初始记录关键字序列为(20,18,22,16,30,19),则根据这些初始关键字序列建成的初始堆为________________________。
答案:(16,18,19,20,30,22)
PS:最近参加CSDN2018年博客评选,希望您能投出宝贵的一票。我是59号,Eastmount,杨秀璋。投票地址:https://bss.csdn.net/m/topic/blog_star2018/index

五年来写了314篇博客,12个专栏,是真的热爱分享,热爱CSDN这个平台,也想帮助更多的人,专栏包括Python、数据挖掘、网络爬虫、图像处理、C#、Android等。现在也当了两年老师,更是觉得有义务教好每一个学生,让贵州学子好好写点代码,学点技术,“师者,传到授业解惑也”,提前祝大家新年快乐。2019我们携手共进,为爱而生。
(By:Eastmount 2019-01-28 下午6点 http://blog.csdn.net/eastmount/ )