Pytorch 深度学习实战教程(五):今天,你垃圾分类了吗?
本文 GitHub https://github.com/Jack-Cherish/PythonPark 已收录,有技术干货文章,整理的学习资料,一线大厂面试经验分享等,欢迎 Star 和 完善。
一、垃圾分类
还记得去年,上海如火如荼进行的垃圾分类政策吗?
2020年5月1日起,北京也开始实行「垃圾分类」了!
北京的垃圾分类标准与上海略有差别,垃圾分为厨余垃圾、可回收物、有害垃圾和其他垃圾四大类,分别对应四种不同颜色的垃圾桶,即绿色、蓝色、红色和灰色。

继上海之后,北京也迈入了“垃圾强制分类时代”。

垃圾分类,最变态的地方还是日本。
日本把垃圾分为资源、可燃、不可燃、危险、塑料、金属和粗大,这 7 大类垃圾。
并规定了回收站每天允许回收的垃圾种类,比如如周一收资源的,周二收塑料的。居民要在指定时间、指定地点丢垃圾。像桌子衣柜这些大件垃圾还要交钱才能扔。
敢乱扔垃圾的垃圾最多还可能吃 5 年牢饭并罚上 1000 万日元!
不过,有 24 小时在线发牌打理家务的家庭主妇,人家可以每天花上半小时去搞垃圾分类,然后照样有时间去刷刷抖音,打打农药,看看小电影啥的。
现在,中国一线城市的“社畜”们,干着 996 的活,又要操起“日本主妇的心”。
一家一个码农就够惨了,一家双码农那就是「惨上加惨」,下班一个比一个晚。
上海实行「垃圾分类」已经快一年了,不知近况如何?
疫情前,曾去上海玩过一次,一个很明显的感受是垃圾分类确实是井然有序地进行着,租住的民宿摆放了 4 个垃圾桶,吃剩的垃圾都需要动动脑子才知道怎么丢。
不过,也在小区附近看到,分类垃圾桶旁,随意堆放的未分类的垃圾。

北京通知开始实施「垃圾分类」有几个月了,我所居住的小区在市中心,小区内还没有见到分类垃圾箱,倒是公告张贴了很多,应该还处于宣传阶段。
不过公司里,倒是开始垃圾分类了,看来是从企业开始行动,然后再到个人。
随着政策的完善,支持力度的加大,不知若干年后,是否会出现一家提供垃圾分类服务的家政公司?
二、垃圾分类助手
吐槽归吐槽,人们总归要随着时代的发展而顺势前行。
好在,一些 APP 或者小程序已经为我们准备好了查询工具。
查询方式无非三种形式:文字、语音、图片。
好多家,都有类似的产品。
你可以查询 「996加班掉落的头发是什么垃圾」,也可以查询「夜宵必备的小龙虾是什么垃圾」。
比如,腾讯有个微信小程序,叫「垃圾分类精灵」;
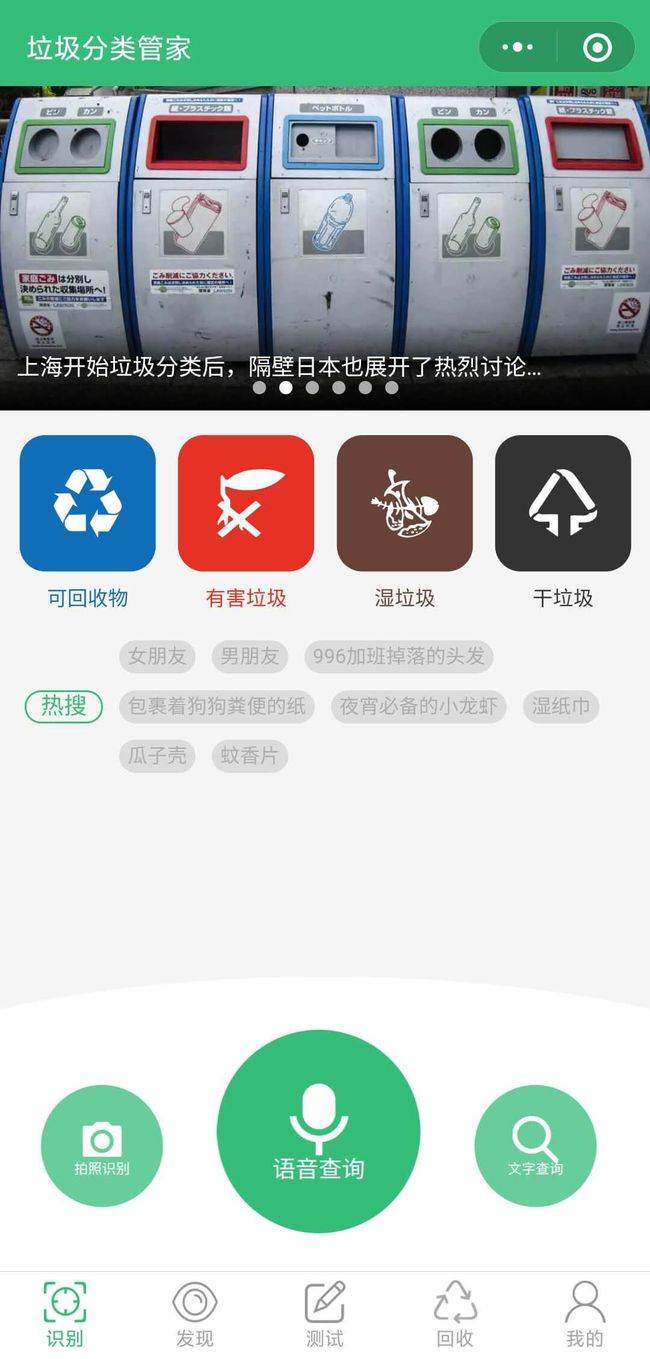
百度 APP 相机识别入口有个 tag ,叫「识垃圾」。

支付宝有个小程序,叫「垃圾分类指南」。
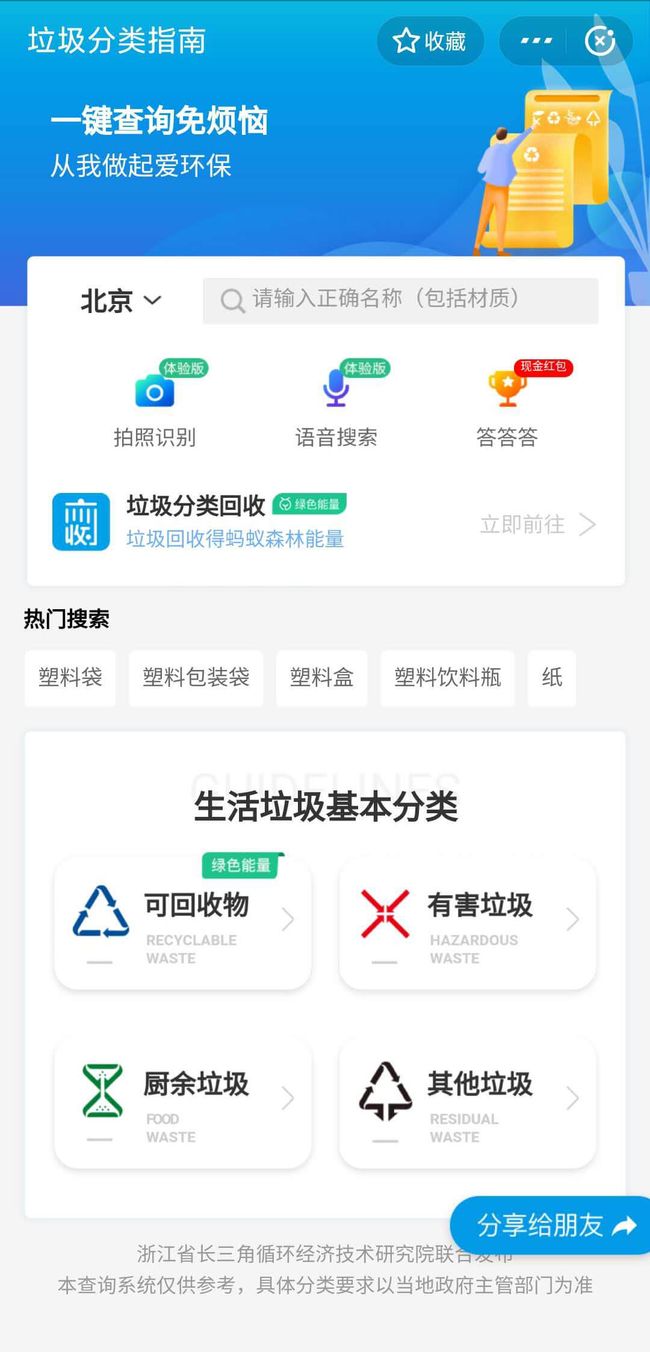
都支持文字、语音、图片的垃圾分类识别。
上海刚实行垃圾分类的时候,淘宝的「拍立淘」也有垃圾分类识别入口,不过现在貌似已经下线了。
垃圾分类哪家强,体验一下就知道了。
三、垃圾分类技术
垃圾识别背后的技术是什么呢?
文字和语音的都相对简单,文本匹配即可,语音多了一个音频转文本的步骤。
基于图片的垃圾识别就要难不少。
比如,卫生纸你可以弄成各种形状,团成一团,或者撕成一条一条。
甚至,可以把蛋糕恶趣味地做成「便便」的样子。
让算法通过图片去识别这些东西,显然有些难为算法。
目前,使用深度学习分类算法去识别垃圾种类,还是比较难做好的。
一般都是采用多级分类模型或检索,搭建的超大分类网络,比如 1 万多类物体识别,甚至 10 万。
然后根据类别标签做映射,映射到最终的垃圾类别。

底层技术实现,其实还是多分类。
垃圾分类不同于通用的图像识别,通用图像识别的「鱼」,可能是一条在水中自由自在嬉戏的金鱼。
而垃圾分类识别的「鱼」,则很可能是一个躺在餐盘里仅剩躯干骨的鱼骨头。
弄个合适的数据集,也是一门技术活。
数据集获取一般可以通过以下 3 个渠道:
- 写爬虫,爬各大网站的图片数据,然后使用自己的接口清洗或者人工标注;
- 将需求提交给数据标注团队,花经费标注数据。
前两个是要么得有技术、要么得有钱。
- 最后一个方法,就得碰运气了。翻论文,找公开数据集,或者去 AI 比赛网站或者 AI 开放平台碰碰运气。
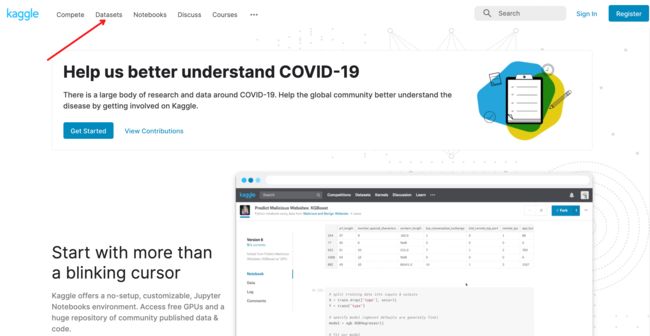
比赛,比如可以去 Kaggle 搜一搜数据集。
URL:https://www.kaggle.com/
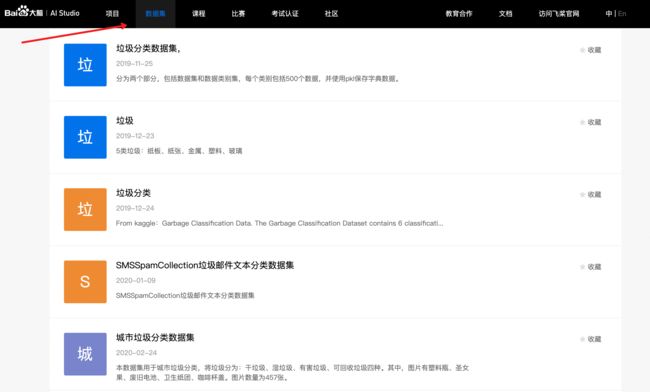
AI 开放平台,可以去 AI Studio看看。
URL:https://aistudio.baidu.com/aistudio/datasetoverview
在 AI Studio 我搜索到了不错的垃圾分类数据集。
一共 56528 张图片,214 类,总共 7.13 GB。
URL:https://aistudio.baidu.com/aistudio/datasetdetail/30982
瞧,运气不错,找到了一个不错的数据集。
下载速度也很给力,10 MB/s。
本文使用这个数据集,训练一个简单的垃圾分类模型。
四、数据处理
垃圾数据都放在了名字为「垃圾图片库」的文件夹里。
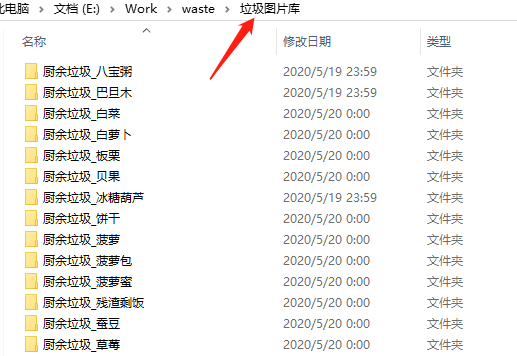
首先,我们需要写个脚本根据文件夹名,生成对应的标签文件(dir_label.txt)。
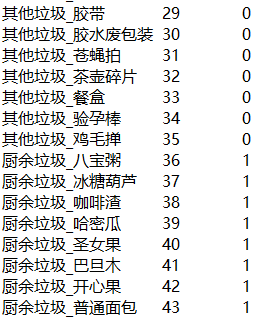
前面是小分类标签,后面是大分类标签。
然后再将数据集分为训练集(train.txt)、验证集(val.txt)、测试集(test.txt)。
训练集和验证集用于训练模型,测试集用于验收最终模型效果。
此外,在使用图片训练之前还需要检查下图片质量,使用 PIL 的 Image 读取,捕获 Error 和 Warning 异常,对有问题的图片直接删除即可。
写个脚本生成三个 txt 文件,训练集 48045 张,验证集 5652 张,测试集 2826 张。
脚本很简单,代码就不贴了,直接提供处理好的文件。
处理好的四个 txt 文件可以直接下载。
下载地址:点击查看
将四个 txt 文件放到和「垃圾图片库」的相同目录下即可。
有了前几篇教程的基础,写个数据读取的代码应该很轻松吧。
编写 dataset.py 读取数据,看一下效果。
import torch
from PIL import Image
import os
import glob
from torch.utils.data import Dataset
import random
import torchvision.transforms as transforms
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
class Garbage_Loader(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.train_tf = transforms.Compose([
transforms.Resize(224),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
])
self.val_tf = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor(),
])
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x:x.strip().split('\t'), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
def __getitem__(self, index):
img_path, label = self.imgs_info[index]
img = Image.open(img_path)
img = img.convert('RGB')
img = self.padding_black(img)
if self.train_flag:
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label
def __len__(self):
return len(self.imgs_info)
if __name__ == "__main__":
train_dataset = Garbage_Loader("train.txt", True)
print("数据个数:", len(train_dataset))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=1,
shuffle=True)
for image, label in train_loader:
print(image.shape)
print(label)读取 train.txt 文件,加载数据。数据预处理,是将图片等比例填充到尺寸为 280 * 280 的纯黑色图片上,然后再 resize 到 224 * 224 的尺寸。
这是图片分类里,很常规的一种预处理方法。
此外,针对训练集,使用 pytorch 的 transforms 添加了水平翻转和垂直翻转的随机操作,这也是很常见的一种数据增强方法。
运行结果:
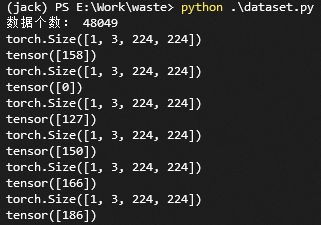
OK,搞定!开始写训练代码!
五、垃圾分类初体验
我们使用一个常规的网络 ResNet50 ,这是一个非常常见的提取特征的网络结构。
整个训练过程也很简单,训练步骤不清楚的,可以看我上两篇教程:
《Pytorch深度学习实战教程(三):UNet模型训练》
《Pytorch深度学习实战教程(四):必知必会的炼丹法宝》
创建 train.py 文件,编写如下代码:
from dataset import Garbage_Loader
from torch.utils.data import DataLoader
from torchvision import models
import torch.nn as nn
import torch.optim as optim
import torch
import time
import os
import shutil
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
"""
Author : Jack Cui
Wechat : https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA
"""
from tensorboardX import SummaryWriter
def accuracy(output, target, topk=(1,)):
"""
计算topk的准确率
"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
class_to = pred[0].cpu().numpy()
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res, class_to
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
"""
根据 is_best 存模型,一般保存 valid acc 最好的模型
"""
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, 'model_best_' + filename)
def train(train_loader, model, criterion, optimizer, epoch, writer):
"""
训练代码
参数:
train_loader - 训练集的 DataLoader
model - 模型
criterion - 损失函数
optimizer - 优化器
epoch - 进行第几个 epoch
writer - 用于写 tensorboardX
"""
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
writer.add_scalar('loss/train_loss', losses.val, global_step=epoch)
def validate(val_loader, model, criterion, epoch, writer, phase="VAL"):
"""
验证代码
参数:
val_loader - 验证集的 DataLoader
model - 模型
criterion - 损失函数
epoch - 进行第几个 epoch
writer - 用于写 tensorboardX
"""
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
[prec1, prec5], class_to = accuracy(output, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1[0], input.size(0))
top5.update(prec5[0], input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % 10 == 0:
print('Test-{0}: [{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
phase, i, len(val_loader),
batch_time=batch_time,
loss=losses,
top1=top1, top5=top5))
print(' * {} Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(phase, top1=top1, top5=top5))
writer.add_scalar('loss/valid_loss', losses.val, global_step=epoch)
return top1.avg, top5.avg
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
if __name__ == "__main__":
# -------------------------------------------- step 1/4 : 加载数据 ---------------------------
train_dir_list = 'train.txt'
valid_dir_list = 'val.txt'
batch_size = 64
epochs = 80
num_classes = 214
train_data = Garbage_Loader(train_dir_list, train_flag=True)
valid_data = Garbage_Loader(valid_dir_list, train_flag=False)
train_loader = DataLoader(dataset=train_data, num_workers=8, pin_memory=True, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, num_workers=8, pin_memory=True, batch_size=batch_size)
train_data_size = len(train_data)
print('训练集数量:%d' % train_data_size)
valid_data_size = len(valid_data)
print('验证集数量:%d' % valid_data_size)
# ------------------------------------ step 2/4 : 定义网络 ------------------------------------
model = models.resnet50(pretrained=True)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, num_classes)
model = model.cuda()
# ------------------------------------ step 3/4 : 定义损失函数和优化器等 -------------------------
lr_init = 0.0001
lr_stepsize = 20
weight_decay = 0.001
criterion = nn.CrossEntropyLoss().cuda()
optimizer = optim.Adam(model.parameters(), lr=lr_init, weight_decay=weight_decay)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_stepsize, gamma=0.1)
writer = SummaryWriter('runs/resnet50')
# ------------------------------------ step 4/4 : 训练 -----------------------------------------
best_prec1 = 0
for epoch in range(epochs):
scheduler.step()
train(train_loader, model, criterion, optimizer, epoch, writer)
# 在验证集上测试效果
valid_prec1, valid_prec5 = validate(valid_loader, model, criterion, epoch, writer, phase="VAL")
is_best = valid_prec1 > best_prec1
best_prec1 = max(valid_prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': 'resnet50',
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer' : optimizer.state_dict(),
}, is_best,
filename='checkpoint_resnet50.pth.tar')
writer.close()代码并不复杂,网络结构直接使 torchvision 的 ResNet50 模型,并且采用 ResNet50 的预训练模型。算法采用交叉熵损失函数,优化器选择 Adam,并采用 StepLR 进行学习率衰减。
保存模型的策略是选择在验证集准确率最高的模型。
batch size 设为 64,GPU 显存大约占 8G,显存不够的,可以调整 batch size 大小。
模型训练完成,就可以写测试代码了,看下效果吧!
创建 infer.py 文件,编写如下代码:
from dataset import Garbage_Loader
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision import models
import torch.nn as nn
import torch
import os
import numpy as np
import matplotlib.pyplot as plt
#%matplotlib inline
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def softmax(x):
exp_x = np.exp(x)
softmax_x = exp_x / np.sum(exp_x, 0)
return softmax_x
with open('dir_label.txt', 'r', encoding='utf-8') as f:
labels = f.readlines()
labels = list(map(lambda x:x.strip().split('\t'), labels))
if __name__ == "__main__":
test_list = 'test.txt'
test_data = Garbage_Loader(test_list, train_flag=False)
test_loader = DataLoader(dataset=test_data, num_workers=1, pin_memory=True, batch_size=1)
model = models.resnet50(pretrained=False)
fc_inputs = model.fc.in_features
model.fc = nn.Linear(fc_inputs, 214)
model = model.cuda()
# 加载训练好的模型
checkpoint = torch.load('model_best_checkpoint_resnet50.pth.tar')
model.load_state_dict(checkpoint['state_dict'])
model.eval()
for i, (image, label) in enumerate(test_loader):
src = image.numpy()
src = src.reshape(3, 224, 224)
src = np.transpose(src, (1, 2, 0))
image = image.cuda()
label = label.cuda()
pred = model(image)
pred = pred.data.cpu().numpy()[0]
score = softmax(pred)
pred_id = np.argmax(score)
plt.imshow(src)
print('预测结果:', labels[pred_id][0])
plt.show()这里需要注意的是,DataLoader 读取的数据需要进行通道转换,才能显示。
预测结果:
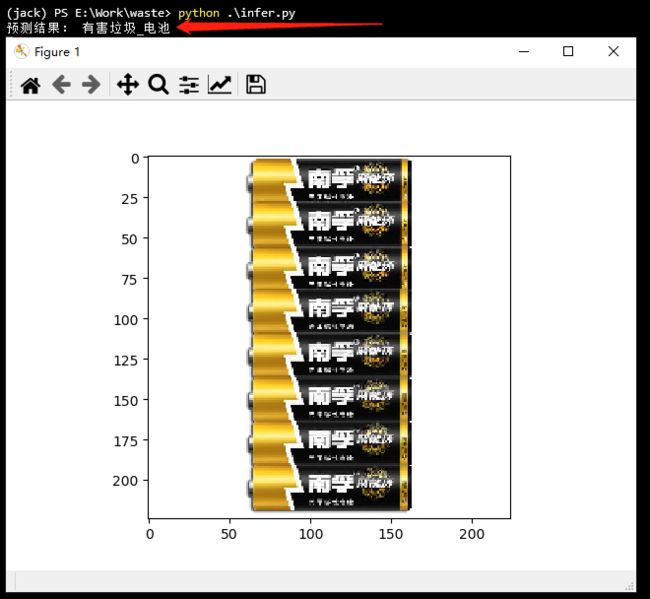
怎么样?还算简单吧?
赶快训练一个自己「垃圾分类器」体验一下吧!
六、总结
- 本文从实战出发,讲解了怎么训练一个自己的「垃圾分类器」。
- baseline 已经提供,提升精度,就是一些细节上的优化了。
- 训练好的模型,关注微信公众号,后台回复「垃圾分类」获取。
PS:文中出现的所有代码,均可在我的 github 上下载,欢迎 Follow、Star:点击查看
