Transitioning from Intel® Movidius™ Neural Compute SDK to Intel® Distribution of OpenVINO™ toolkit
Transitioning from Intel® Movidius™ Neural Compute SDK to Intel® Distribution of OpenVINO™ toolkit
November 14, 2018
https://software.intel.com/en-us/articles/transitioning-from-intel-movidius-neural-compute-sdk-to-openvino-toolkit
Intel Movidius
https://www.movidius.com/
Intel® Neural Compute Stick 2
https://software.intel.com/en-us/neural-compute-stick
This article provides guidance for transitioning from the Intel® Movidius™ Neural Compute SDK (NCSDK) to the Intel® Distribution of OpenVINO™ Toolkit.
Introduction
The original Intel® Movidius™ Neural Compute Stick (NCS) is a tiny, fanless deep learning device allows you to learn AI programming at the edge (locally). It is powered by the same high-performance Intel® Movidius™ Myriad™ Vision Processing Unit (VPU) that can be found in millions of smart security cameras, gesture controlled drones, industrial machine vision equipment, and more. Enable rapid prototyping, validation, and deployment of deep neural network (DNN) inference applications at the edge. The low-power vision processing unit (VPU) architecture enables an entirely new segment of AI applications that are not reliant on a connection to the cloud. Testing and deploying on the edge lowers latency than using the cloud and increases security because the work stays on your machine.
drone [drəʊn]:n. 雄蜂,嗡嗡的声音,懒惰者 n. 无人机 (非正式) vi. 嗡嗡作声,混日子 vt. 低沉地说
The original Intel® Movidius™ NCS and the Intel® Neural Compute Stick 2 (Intel® NCS 2) are hardware devices based on Vision Processing Units (VPU). The original NCS was based on the Intel® Movidius™ Myriad™ 2 VPU and the Intel® NCS 2 is based on the Intel® Movidius™ Myriad™ X VPU which includes two Neural Compute Engines (NCE) for accelerating deep learning inferences at the edge. The NCE is an on-chip hardware block specifically designed to run deep neural networks at high speed and low power without compromising accuracy, enabling devices to see, understand and respond to their environments in real time. Vision Processing Units (VPUs) are different from Graphic Processing Units (GPUs) as the GPU hardware is focused on multimedia tasks such as rasterizing, video processing, transcoding video, image analysis, and mapping for 3D graphics. GPUs are optimized for multimedia where VPUs enable visual intelligence at a high compute per watt. OpenVINO™ toolkit supports camera processing, computer vision, and deep learning inferences.
COMPUTER VISION HARDWARE
https://software.intel.com/en-us/openvino-toolkit/hardware
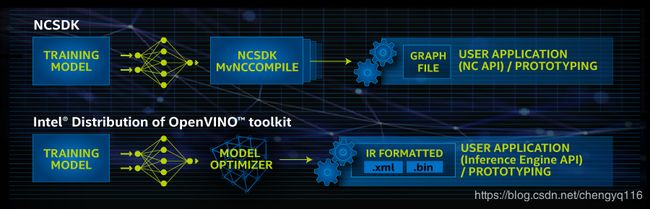
Figure 1. Workflow: NCSDK and OpenVINO™ toolkit
Intel® Movidius™ Neural Compute SDK (NCSDK) and Intel® Distribution of OpenVINO™ toolkit
The original NCS device was introduced with the software tools and API in the NCSDK. As part of Intel’s cohesive AI strategy, the primary software toolkit for Intel® NCS 2 that provides similar functionality is OpenVINO™ toolkit. The OpenVINO™ toolkit is provided with Python* and C++ APIs for users of the Intel® Movidius™ Neural Compute Stick (NCS). It includes software tools, an API, and examples, so developers can create software that takes advantage of the accelerated neural network capability provided by the Intel Movidius NCS hardware. The OpenVINO™ toolkit supports both the original NCS and the Intel® NCS 2. It also supports Central Processing Unit (CPU), GPU, and Field Programmable Gate Array (FPGA) hardware.
INTEL® NEURAL COMPUTE STICK
https://software.intel.com/en-us/neural-compute-stick
cohesive [kəʊ'hiːsɪv]:adj. 凝聚的,有结合力的,紧密结合的,有粘着力的
If you are already familiar with Intel® Movidius™ Neural Compute SDK (NCSDK) this documentation will help make life easier when transitioning to the OpenVINO™ toolkit. If you are not already using NCSDK, start with the OpenVINO™ toolkit.
DEVELOP MULTIPLATFORM COMPUTER VISION SOLUTIONS
https://software.intel.com/en-us/openvino-toolkit
Intel® Distribution of OpenVINO™ toolkit
The OpenVINO™ toolkit is provided for users of the Intel® Movidius™ Neural Compute Stick (NCS). It includes software tools, an API, and examples, so developers can create software that takes advantage of the accelerated neural network capability provided by the NCS hardware. The OpenVINO™ toolkit supports both the original NCS and the Intel® NCS 2.
The Intel® Movidius™ Neural Compute SDK (NCSDK)
This toolkit came with Python and C Language API that enables applications that utilize hardware accelerated deep neural networks via neural compute devices such as the Intel® Movidius™ Neural Compute Stick (NCS).
- The NCSDK only supports the original NCS.
- The OpenVINO™ toolkit supports the Intel® NCS 2 and the original NCS.
In the reminder of this document, the key concepts which differ between NCSDK to OpenVINO™ toolkit will be explored.
Development Platform
Operating Systems
With NCSDK, the NCS could be used with Ubuntu* 16.04 (64 bit). NCS does work with OpenVINO™ toolkit on Ubuntu 16.04. In addition, CentOS* is a supported operating system.
Environment Setup
The default installation of the NCSDK made modifications to the user’s .bashrc which made the NCSDK tools available be default from any terminal. OpenVINO™ toolkit has a slightly different approach in that a setupvars.sh script is provided that the user can source before using the OpenVINO™ toolkit tools. If an experience closer to the NCSDK is desired, after completing the toolkit installation steps, you can optionally add the setupvars.sh command to your .bashrc file to permanently set the environment variables required to compile and run OpenVINO™ toolkit applications.
For users that like to use python virtual environments, the NCSDK had a configuration file that could be changed prior to installation and would install in a virtual environment. In OpenVINO™ toolkit it is recommended that you use a virtual environment.
Model Optimizer Developer Guide
https://software.intel.com/en-us/articles/OpenVINO-ModelOptimizer
Supported Frameworks
One advantage of the OpenVINO™ toolkit is that the deep learning framework support is expanded, which means you can compile a wider variety of trained networks for use with NCS devices. With NCSDK only Caffe* and TensorFlow* were supported, but the OpenVINO™ toolkit also provides support for the other deep learning frameworks. A variety of trained networks are available for all the frameworks. For example, the public list of ONNX* models is available on GitHub*.
Open Neural Network Exchange
https://github.com/onnx/models
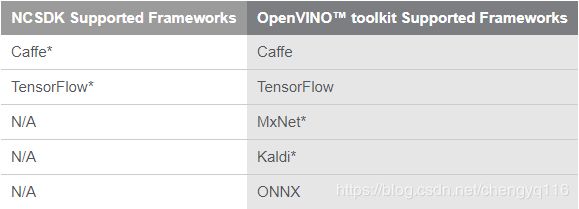
With NCSDK, frameworks are automatically installed. With OpenVINO™ toolkit, use the install_prerequisites.sh script to configure all the frameworks. Configure a specific network by using available scripts. More information can be found in the Configure Model Optimizer section.
Configuring the Model Optimizer
https://software.intel.com/en-us/articles/OpenVINO-ModelOptimizer#configuring-the-model-optimizer
Examples
ncappzoo on GitHub
https://github.com/movidius/ncappzoo
OpenVINO™ toolkit pre-trained models
PRETRAINED MODELS
https://software.intel.com/en-us/openvino-toolkit/documentation/pretrained-models
OpenVINO™ toolkit code samples
CODE SAMPLES
https://software.intel.com/en-us/openvino-toolkit/documentation/code-samples
API and Tools Terminology
Neural Compute API (NCAPI) equivalent
The NCAPI that comes with the the NCSDK provides a C and Python programming interface. The OpenVINO™ Toolkit includes an API called the Inference Engine, which is a library of C++ or Python classes that provide the OpenVINO™ toolkit equivilent to the NCAPI. OpenVINO™ toolkit does not include a C language API so be sure to use a C++ compiler when building a program that uses the OpenVINO™ toolkit Inference Engine. If you have existing C code that was using the NCSDK’s C library most of that should compile in C++ as well since C is (mostly) a subset of C++.
Tools equivalent
Also the NCSDK came with three tools, the MvNCCompile, MvNCProfile, and MvNCCheck programs. OpenVINO™ toolkit does not come with an equivalent for the MvNCProfile and MvNCCheck tools but the equivalent to the MvNCCompile compiler is the Model Optimizer for OpenVINO™ toolkit, which is the mo.py Python program installed as part of the OpenVINO™ toolkit.
MvNCCompile -> mo.py (model optimizer)
mvNCCompile is a command line tool that compiles network and weights files for Caffe or TensorFlow* models into an Intel® Movidius™ graph file format that is compatible with the Intel® Movidius™ Neural Compute SDK (Intel® Movidius™ NCSDK) and Neural Compute API (NCAPI). The following table shows the options of the MvNCCompile command and their equivalent in the model optimizer.

In addition to the above table, the following sections explain other differences between the compiler tools.
Model Optimizer Support for Metagraph*
One difference in the Model Optimizer compared to MvNCCompile for TensorFlow is NCSDK allowed TensorFlow metagraphs.
Loading non-frozen models to the Model Optimizer
There are three ways to store non-frozen TensorFlow models and load them to the Model Optimizer:
In this case, a model consists of three or four files stored in the same directory:
- model_name.meta
- model_name.index
- model_name.data-00000-of-00001 (digit part may vary)◦checkpoint (optional)
To convert such TensorFlow model:
- Go to the
/deployment_tools/model_optimizer directory - Run the mo_tf.py script with a path to the MetaGraph .meta file to convert a model:
mo_tf.py --input_meta_graph .meta
Saved model
In this case, a model consists of a special directory:
To convert such TensorFlow model:
- Go to the
/deployment_tools/model_optimizer directory - Run the mo_tf.py script with a path to the SavedModel directory to convert a model:
mo_tf.py --saved_model_dir
Checkpoint
In this case, a model consists of two files:
- inference_graph.pb or inference_graph.pbtxt
- checkpoint_file.ckpt
If you do not have an inference graph file, refer to Freezing Custom Models in Python.
Freezing Custom Models in Python*
https://software.intel.com/en-us/articles/OpenVINO-Using-TensorFlow#freezing-a-tensorflow-model
MvNCProfile
mvNCProfile is a command line tool that compiles a network for use with the NCSDK, runs the network on a connected neural compute device, and outputs text and HTML profile reports. The profiling data contains layer-by-layer statistics about the performance of the network. This is helpful in determining how much time is spent on each layer to narrow down potential changes to the network to improve the total inference time. There is no equivalent tool in the OpenVINO™ toolkit.
MvNCCheck
mvNCCheck is a command line tool that checks the validity of a Caffe or TensorFlow neural network on a neural compute device. The check is done by running an inference on both the device and in software on the host computer using the supplied network and appropriate framework libraries. The results for both inferences are compared to determine if the network passes or fails. The top 5 inference results are provided as output. This tool works best with image classification networks. There is no equivalent tool in the OpenVINO™ toolkit.
Multiple NCS Devices
The NCSDK provided an API to enumerate all NCS devices in the system and let the application programmer run inferences on specific devices. With the OpenVINO™ toolkit Inference Engine API, the library itself distributes inferences to the NCS devices based on device load so that logic does not need to be included in the application.
The key points when creating an OpenVINO™ toolkit application for multiple devices using the Engine API are:
- The application in general doesn’t need to be concerned with specific devices or managing the workloads for those devices.
- The application should create a single PlugIn instance using the device string “MYRIAD”. This plugin instance handles all “MYRIAD” devices in the system for the application. The NCS and Intel® NCS 2 are both “MYRIAD” devices as they are both based on versions of the Intel® Movidius™ Myriad™ VPU.
- The application should create an ExecutableNetwork instance for each device in the host system for maximum performance. However, there is nothing in the API that ties an ExecutableNetwork to a particular device.
- Multiple Inference Requests can be created for each ExecutableNetwork. These requests can be processed by the device with a level of parallelization that best works with the target devices. For Intel® NCS 2 devices, four inference requests for each Executable Network are the optimum number to create if your application is sensitive to inference throughput.
FIFO Queues
The NCAPI v2 came with built in FIFO queues that the application could write neural network input to and read network results from. The OpenVINO™ toolkit Inference Engine API doesn’t expose an equivalent queueing mechanism in the API, however, InferenceRequests are started. and these will be queued internally. For more information on the asynchronous API and inference requests the OpenVINO™ toolkit examples that highlight the Asynchronous API should be consulted.
Inference Engine Developer Guide
https://software.intel.com/en-us/articles/OpenVINO-InferEngine
Asynchronous example using OpenVINO™ toolkit.
Tutorial Step 4: Using Asynchronous API
https://github.com/intel-iot-devkit/inference-tutorials-generic/blob/openvino_toolkit_r3_0/car_detection_tutorial/step_4/Readme.md
Key Differences - Key Concepts
The following subsections describe a few key concepts and differences between the NCSDK and the OpenVINO™ toolkit for the typical application workflow.
Refer to the OpenVINO™ toolkit release notes for specific information about what is supported in any particular release.
Release Notes for Intel® Distribution of OpenVINO™ toolkit
https://software.intel.com/en-us/articles/OpenVINO-RelNotes
RPi - Raspberry Pi
Not initially supported with OpenVINO™ toolkit.
Virtual machine support
NCSDK instructions for Virtual Machine support.
Installation and Configuration with a Virtual Machine
https://movidius.github.io/ncsdk/vm_config.html
Virtual machine support for OpenVINO™ toolkit is not validated, but there are no known issues that would prevent it from working.
Docker support
NCSDK had specific instructions for Docker.
Installation and Configuration with Docker
https://movidius.github.io/ncsdk/docker.html
There are no specific instructions for OpenVINO™ toolkit.
Python virtual environment
Strongly recommended for all global Model Optimizer dependency installations: Create and activate a virtual environment. While not required, this step is strongly recommended since the virtual environment creates a Python sandbox, and dependencies for the Model Optimizer do not influence the global Python configuration, installed libraries, or other components. In addition, a flag ensures that system-wide Python libraries are available in this sandbox.
Virtual environment instructions are found in the Model Optimizer Guide configuration section.
Using Manual Configuration Process
https://software.intel.com/en-us/articles/OpenVINO-ModelOptimizer#inpage-nav-2-2
Simple inference code flow
The high level list of steps in a typical application for either NCSDK or OpenVINO™ toolkit would include the following.
- Device Initialization
- Load Neural Network
- Obtain input tensor
- Start inference
- Get inference result
- Clean up
Below, the C++ and Python Code for both NCSDK and OpenVINO™ toolkit to achieve these high level steps are provided.
Sample Code: Python - ncapi v2
"""NCAPI v2"""
### initialization
from mvnc import mvncapi
######################## Device Initialization #######################
device_list = mvncapi.enumerate_devices()
device = mvncapi.Device(device_list[0])
device.open()
########################################################################
####################### Load Neural Network ########################
# Initialize a graph from file at some GRAPH_FILEPATH
GRAPH_FILEPATH = './graph'
with open(GRAPH_FILEPATH, mode='rb') as f:
graph_buffer = f.read()
graph = mvncapi.Graph('graph1')
# CONVENIENCE FUNCTION:
# Allocate the graph to the device and create input/output Fifos with default options in one call
input_fifo, output_fifo = graph.allocate_with_fifos(device, graph_buffer
########################################################################
######################## Obtain Input Tensor #########################
# Read and pre-process input (data type must match input Fifo data type)
input_tensor = ...
########################################################################
######################### Start Inference #########################
# CONVENIENCE FUNCTION:
# Write the image to the input queue and queue the inference in one call
graph.queue_inference_with_fifo_elem(input_fifo, output_fifo, input_tensor, None)
########################################################################
######################### Get Inference result #######################
# Get the results from the output queue
output, user_obj = output_fifo.read_elem()
########################################################################
# Do something with the results...
############################# Clean up ###############################
input_fifo.destroy()
output_fifo.destroy()
graph.destroy()
device.close()
device.destroy()
########################################################################
Sample Code: Python - OpenVINO™ Toolkit
def main():
####################### Device Initialization ########################
# Plugin initialization for specified device and load extensions library if specified
plugin = IEPlugin(device="MYRIAD")
#########################################################################
######################### Load Neural Network #########################
# Read in Graph file (IR)
net = IENetwork.from_ir(model="graph1.xml", weights="graph1.bin")
input_blob = next(iter(net.inputs))
out_blob = next(iter(net.outputs))
# Load network to the plugin
exec_net = plugin.load(network=net)
del net
########################################################################
######################### Obtain Input Tensor ########################
# Obtain and preprocess input tensor (image)
# Read and pre-process input image maybe we don't need to show these details
image = cv2.imread("input_image.jpg")
# Preprocessing is neural network dependent maybe we don't show this
n, c, h, w = net.inputs[input_blob]
image = cv2.resize(image, (w, h))
image = image.transpose((2, 0, 1)) # Change data layout from HWC to CHW
image = image.reshape((n, c, h, w))
########################################################################
########################## Start Inference ##########################
# Start synchronous inference and get inference result
req_handle = exec_net.start_async(inputs={input_blob: image})
########################################################################
######################## Get Inference Result #########################
status = req_handle.wait()
res = req_handle.outputs[out_blob
# Do something with the results... (like print top 5)
top_ind = np.argsort(res[out_blob], axis=1)[0, -5:][::-1]
for i in top_ind:
print("%f #%d" % (res[out_blob][0, i], i))
############################### Clean Up ############################
del exec_net
del plugin
########################################################################
if __name__ == '__main__':
sys.exit(main() or 0)
Sample Code: C++ - ncapi v2
// initialization
#include
/////////////////////// Device Initialization ///////////////////////
struct ncDeviceHandle_t* deviceHandle;
ncDeviceCreate(deviceIndex, &deviceHandle);
ncDeviceOpen(deviceHandle);
/////////////////////////////////////////////////////////////////////
////////////////////////// Load Neural Network //////////////////////
// Create the graph handle
struct ncGraphHandle_t* graphHandle = NULL;
ncGraphCreate("graph", &graphHandle);
// Initialize and read in a graph from some GRAPHFILE_PATH
fp = fopen(GRAPHFILE_PATH, "rb");
if(fp == NULL)
return 0;
fseek(fp, 0, SEEK_END);
*length = ftell(fp);
rewind(fp);
if(!(graphBuffer = (char*) malloc(*length))) {
fclose(fp);
}
if(fread(graphBuffer, 1, *length, fp) != *length) {
fclose(fp);
free(graphBuffer);
}
fclose(fp);
struct ncFifoHandle_t* inputFifo = NULL;
struct ncFifoHandle_t* outputFifo = NULL;
// CONVENIENCE FUNCTION:
// Allocate and create input/output fifos in one call
ncGraphAllocateWithFifos(deviceHandle, graphHandle, graphBuffer, graphLength, &inputFifo, &outputFifo);
/////////////////////////////////////////////////////////////////////
/////////////////////// Obtain Input Tensor ///////////////////////
// Read and preprocess input from image file or camera etc.
inputTensor = ...
/////////////////////////////////////////////////////////////////////
//////////////////////// Start Inference /////////////////////////
// CONVENIENCE FUNCTION:
// Write the image to the input queue and queue the inference in one call
ncGraphQueueInferenceWithFifoElem(graphHandle, &inputFifo, &outputFifo, inputTensor, &inputTensorLength, 0);
/////////////////////////////////////////////////////////////////////
/////////////////////// Get Inference Result ////////////////////////
// Get the results from the output queue
ncFifoReadElem(outputFifo, outputData, &outputdataLength, NULL);
/////////////////////////////////////////////////////////////////////
// Do something with the results...
///////////////////////////// Clean up /////////////////////////////
ncFifoDestroy(&inputFifo);
ncFifoDestroy(&outputFifo);
ncGraphDestroy(&graphHandle);
ncDeviceClose(deviceHandle);
ncDeviceDestroy(&deviceHandle);
/////////////////////////////////////////////////////////////////////
Sample Code: C++ - OpenVINO™ Toolkit
///////////////////// Device Initialization //////////////////////
// Plugin initialization
InferenceEngine::PluginDispatcher dispatcher({"../../../lib/intel64", ""});
InferencePlugin plugin(dispatcher.getSuitablePlugin(TargetDevice::eMYRIAD));
/////////////////////////////////////////////////////////////////////
////////////////////// Load Neural Network //////////////////////
// Read in Graph file (IR)
CNNNetReader network_reader;
network_reader.ReadNetwork(input_model);
network_reader.ReadWeights(input_model.substr(0, input_model.size() - 4) + ".bin");
network_reader.getNetwork().setBatchSize(1);
CNNNetwork network = network_reader.getNetwork();
// Prepare input blobs
auto input_info = network.getInputsInfo().begin()->second;
auto input_name = network.getInputsInfo().begin()->first;
input_info->setPrecision(Precision::U8);
// Prepare output blobs
auto output_info = network.getOutputsInfo().begin()->second;
auto output_name = network.getOutputsInfo().begin()->first;
output_info->setPrecision(Precision::FP32);
// Load network to the plugin
auto executable_network = plugin.LoadNetwork(network, {});
auto infer_request = executable_network.CreateInferRequest();
auto input = infer_request.GetBlob(input_name);
auto input_data = input->buffer().as::value_type*>();
//////////////////////////////////////////////////////////////////////
/////////////////////// Obtain input tensor ////////////////////////
// Obtain and preprocess input tensor (image)
cv::Mat image = cv::imread(input_image_path);
cv::resize(image, image, cv::Size(input_info->getDims()[0], input_info->getDims()[1]));
size_t channels_number = input->dims()[2];
size_t image_size = input->dims()[1] * input->dims()[0];
for (size_t pid = 0; pid < image_size; ++pid) {
for (size_t ch = 0; ch < channels_number; ++ch) {
input_data[ch * image_size + pid] = image.at(pid)[ch];
}
}
//////////////////////////////////////////////////////////////////////
///////////////////////// Start Inference /////////////////////////
// Start synchronous inference and get inference result
infer_request.Infer();
//////////////////////////////////////////////////////////////////////
////////////////////// Get Inference Result ///////////////////////
auto output = infer_request.GetBlob(output_name);
auto output_data = output->buffer().as::value_type*>();
//////////////////////////////////////////////////////////////////////
// Do something with the results... (like print top 5)
std::cout << std::endl << "Top " << results_to_display << " results:" << std::endl << std::endl;
for (size_t id = 0; id < results_to_display; ++id) {
std::cout.precision(7);
auto result = output_data[results[id]];
std::cout << std::left << std::fixed << result << " label #" << results[id] << std::endl;
}
////////////////////////////// clean up //////////////////////////////
// clean up done in destructors, nothing explicit to do.
///////////////////////////////////////////////////////////////////////
For more complete information about compiler optimizations, see our Optimization Notice.
Optimization Notice
https://software.intel.com/en-us/articles/optimization-notice